
Принципы разработки безопасных программных продуктов
Содержание:

ВВЕДЕНИЕ
В настоящее время существует множество языков программирования и сред программирования. Некоторые из них предназначены для написания клиентских приложений, некоторые для написания серверных приложений. Сегодня умение работать в среде программирования Delphi является ценным качеством для профессионала, поэтому необходимо развивать навыки работы в этой среде, что, в свою очередь, поможет нам стать квалифицированными специалистами в области программирования.
Delphi-это среда программирования, которая использует язык программирования Object Pascal. Начиная со среды разработки Delphi 7.0, в официальных документах Borland стал использовать имя Delphi для обозначения языкового объекта Pascal.
Актуальность выбранной темы обусловлена тем, что базы данных в настоящее время используются во всех сферах человеческой деятельности.
Целью курсовой работы является: изучение теоретического материала и написание программного обеспечения на Delphi, которое позволит корректно работать с базой данных.
В соответствии с поставленной целью при выполнении работ ставятся следующие задачи:
- изучение теоретических основ защитного программирования;
- изучение и анализ методов структурирования программ и программных модулей;
- изучение среды программирования Borland Delphi 7;
- создание приложения в среде программирования Borland Delphi 7 для работы с базами данных;
- отладка разработанного приложения.
При написании работы автор опирался на труды отечественных и зарубежных ученых Братчикова И. Л., Гулидова А. И., Наберухина Ю. И., Дейкстры Е. А., Ершова А. П., и др.
1.ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1 Защитное программирование
1.1.1 Правила написания программ с блоками защиты от несанкционированного ввода данных
Парольная система как неотъемлемая составляющая подсистемы управления доступом системы защиты информации (СЗИ) является частью "переднего края обороны" всей системы безопасности. Поэтому парольная система становится одним из первых объектов атаки при вторжении злоумышленника в защищенную систему.
Подсистема управления доступом СЗИ затрагивает следующие понятия:
- идентификатор доступа - уникальный признак субъекта или объекта доступа;
- идентификация - присвоение субъектам и объектам доступа идентификатора и (или) сравнение предъявляемого идентификатора с перечнем присвоенных идентификаторов;
- пароль - идентификатор субъекта доступа, который является его (субъекта) секретом;
- аутентификация - проверка принадлежности субъекту доступа предъявленного им идентификатора;
- подтверждение подлинности.
Можно встретить и такие толкования терминов идентификатор и пароль пользователя [1]:
1. Идентификатор - некоторое уникальное количество информации, позволяющее различать индивидуальных пользователей парольной системы (проводить их идентификацию). Часто идентификатор также называют именем пользователя или именем учетной записи пользователя;
2. Пароль - некоторое секретное количество информации, известное только пользователю и парольной системе, предъявляемое для прохождения процедуры аутентификации.
Учетная запись - совокупность идентификатора и пароля пользователя.
Одним из наиболее важных компонентов парольной системы является база данных учетных записей (база данных системы защиты). Возможны следующие варианты хранения паролей в системе:
- в открытом виде;
- в виде хэш-значений (hash (англ.) - смесь, мешанина);
- зашифрованными на некотором ключе.
Наибольший интерес представляют второй и третий способы, которые имеют ряд особенностей.
Хэширование не защищает от сопоставления паролей словаря в случае, если злоумышленник получает базу данных. При выборе алгоритма хэширования, который будет использоваться для вычисления хэшей паролей, необходимо убедиться, что значения хэшей, полученные из разных паролей пользователей, не совпадают. Кроме того, должен быть предусмотрен механизм, гарантирующий уникальность хэш-значений, если два пользователя выбирают одни и те же пароли. Для этого при вычислении каждого хэш-значения обычно используется определенное количество "случайной" информации, например, выдаваемой генератором псевдослучайных чисел.
При шифровании паролей особое значение имеет способ создания и хранения ключа шифрования базы данных учетных записей. Доступны следующие параметры:
- ключ генерируется программно и хранится в системе, что позволяет ему автоматически перезапускаться;
- ключ генерируется программно и хранится на внешнем носителе, который считывается при каждом запуске;
- ключ генерируется на основе пароля, выбранного администратором, который вводится в систему при каждом запуске.
Наиболее безопасное хранение паролей обеспечивается их хэшированием и последующим шифрованием полученных хэш-значений, т. е. комбинацией второго и третьего способов хранения паролей в системе.
Как пароль может попасть в руки злоумышленника? Наиболее реально выглядят следующие случаи:
- пароль, который вы записали, был найден злоумышленником;
- пароль был подсмотрен злоумышленником при вводе легального пользователя;
- злоумышленник получил доступ к базе данных системы безопасности.
Меры по противодействию первым двум опасностям очевидны.
В последнем случае злоумышленнику потребуется специализированное программное обеспечение, поскольку записи в таком файле редко хранятся в открытом виде. Прочность системы паролей определяется ее способностью противостоять атаке злоумышленника, который завладел базой данных учетных записей и пытается восстановить пароли, и зависит от скорости "самой быстрой" реализации используемого алгоритма хеширования. Восстановление пароля состоит из вычисления значений хэша из возможных паролей и сравнения их с существующими значениями хэша пароля, а затем представления их явно в форме с учетом регистра.
Из базы данных учетных записей пароль может быть восстановлен различными способами: словарная атака, последовательная (полная) грубая сила и гибрид словарной атаки и последовательной грубой силы.
В словарной атаке хэш-значения для каждого словарного слова или модификации словарного слова последовательно вычисляются и сравниваются с хэш-значениями паролей каждого пользователя. Если хэш-значения совпадают, пароль найден. Преимуществом метода является его высокая скорость. Недостатком является то, что таким образом можно найти только очень простые пароли, которые доступны в словаре или являются модификациями словарных слов. Успех этой атаки зависит от качества и объема используемого словаря (такие готовые словари легко найти в Интернете).
Последовательный поиск всех возможных комбинаций (brute force -англ.) - грубая сила, лобовое решение) использует набор символов и вычисляет хэш-значение для каждого возможного пароля, состоящего из этих символов. При использовании этого метода пароль всегда будет определен, если его составляющие символы присутствуют в выбранном наборе. Единственным недостатком этого метода является количество времени, которое может потребоваться для определения пароля. Чем больше символов (букв разного регистра, цифр, специальных символов) содержится в выбранном наборе, тем больше времени может пройти до окончания поиска комбинаций.
При восстановлении паролей гибридом атаки по словарю и последовательного перебора к каждому слову или модификации слова словаря добавляются символы справа и/или слева (123parol). Помимо этого, может осуществляться проверка использования: имен пользователей в качестве паролей; повторения слов (dogdog); обратного порядка символов слова (elpoep); транслитерации букв (parol); замену букв кириллицы латинской раскладкой (gfhjkm).
Для каждой получившейся комбинации вычисляется хэш-значение, которое сравнивается с хэш-значениями паролей каждого из пользователей.
Какой пароль можно однозначно назвать слабым во всех отношениях (за исключением запоминаемости)? Типичный пример: пароль из небольшого количества (до 5) символов/цифр. По некоторым данным, из 967 паролей одного из взломанных почтовых серверов сети Интернет 335 (почти треть) состояла исключительно из цифр. Количество паролей, включающих буквы и цифры оказалось равным 20. Остальные пароли состояли из букв в основном в нижнем регистре за редким исключением (в количестве 2 паролей) включающих спецсимволы ("*", "_"). Символ "_", однако, часто встречался в именах пользователей. В 33 случаях имя и пароль пользователя совпадали. Самым популярным оказался пароль 123 (встречался 35 раз, почти каждый 27 пароль). На втором месте пароль qwerty (20 паролей). Как удобно он набирается, не правда ли? Далее следуют: 666 (18 раз), 12 (17 раз), xakep (14 раз) и 1, 11111111, 9128 (по 10 раз). 16 паролей состояли из одного символа/цифры.
В повседневной жизни современному человеку приходится держать в памяти немалое количество информации: пин-коды к банковской карте и мобильному телефону, комбинации кодовых замков, пароль для доступа в Интернет, к ресурсам разного рода, электронным почтовым ящикам. Все ли пароли необходимо держать в памяти? Все зависит от оценки уровня потерь в результате попадания вашего пароля в чужие руки. Пароли для доступа в Интернет и к ресурсам сети никто не мешает записать в блокнот, если вы не опасаетесь, что кто-нибудь войдет в сеть без вашего ведома и ознакомится с содержанием почтового ящика. Данное умозаключение, однако, не распространяется на пароли, используемые на рабочем месте. Получение доступа к локальной сети от вашего имени может, по определенным причинам, стать заманчивым вариантом. Пин-код банковской карты тоже не запрещается фиксировать на бумаге, главным условием в этом случае является раздельное хранение карты и записанной без пояснений кодовой комбинации.
1.1.2 Приемы надежного программирования
Альтернативой правильного ПС является надежное ПС. Надежность ПС — это его способность безотказно выполнять определенные функции при заданных условиях в течение заданного периода времени с достаточно большой вероятностью [5]. При этом под отказом в ПС понимают проявление в нем ошибки [2]. Таким образом, надежная ПС не исключает наличия в ней ошибок - важно лишь, чтобы эти ошибки при практическом применении этого ПС в заданных условиях проявлялись достаточно редко. Убедиться, что ПС обладает таким свойством можно при его испытании путем тестирования, а также при практическом применении. Таким образом, фактически мы можем разрабатывать лишь надежные, а не правильные ПС.
Разрабатываемая ПС может обладать различной степенью надежности. Как измерять эту степень? Так же как в технике, степень надежности можно характеризовать [2] вероятностью работы ПС без отказа в течении определенного периода времени. Однако в силу специфических особенностей ПС определение этой вероятности наталкивается на ряд трудностей по сравнению с решением этой задачи в технике. Позже мы вернемся к более обстоятельному обсуждению этого вопроса.
При оценке степени надежности ПС следует также учитывать последствия каждого отказа. Некоторые ошибки в ПС могут вызывать лишь некоторые неудобства при его применении, тогда как другие ошибки могут иметь катастрофические последствия, например, угрожать человеческой жизни. Поэтому для оценки надежности ПС иногда используют дополнительные показатели, учитывающие стоимость (вред) для пользователя каждого отказа.
Рассмотрим теперь общие принципы обеспечения надёжности ПС, что, как мы уже подчёркивали, является основным мотивом разработки ПС, задающим специфическую окраску всем технологическим процессам разработки ПС. В технике известны четыре подхода обеспечению надёжности [11]:
- предупреждение ошибок;
- самообнаружение ошибок;
- самоисправление ошибок;
- обеспечение устойчивости к ошибкам.
Целью подхода предупреждения ошибок — не допустить ошибок в готовых продуктах, в нашем случае — в ПС. Проведенное рассмотрение природы ошибок при разработке ПС позволяет для достижения этой цели сконцентрировать внимание на следующих вопросах:
-борьбе со сложностью;
-обеспечении точности перевода;
-преодоления барьера между пользователем и разработчиком;
- обеспечения контроля принимаемых решений.
Этот подход связан с организацией процессов разработки ПС, т.е. с технологией программирования. И хотя, как мы уже отмечали, гарантировать отсутствие ошибок в ПС невозможно, но в рамках этого подхода можно достигнуть приемлемого уровня надежности ПС.
Остальные три подхода связаны с организацией самих продуктов технологии, в нашем случае — программ. Они учитывают возможность ошибки в программах. Самообнаружение ошибки в программе означает, что программа содержит средства обнаружения отказа в процессе ее выполнения. Самоисправление ошибки в программе означает не только обнаружение отказа в процессе ее выполнения, но и исправление последствий этого отказа, для чего в программе должны иметься соответствующие средства.
Обеспечение устойчивости программы к ошибкам означает, что в программе содержатся средства, позволяющие локализовать область влияния отказа программы, либо уменьшить его неприятные последствия, а иногда предотвратить катастрофические последствия отказа. Однако, эти подходы используются весьма редко (может быть, относительно чаще используется обеспечение устойчивости к ошибкам).
1.1.3 Причины ошибок программного обеспечения
Рассмотрим неправильный перевод как причина ошибок в программных средствах. При разработке и использовании ПС мы многократно имеем дело [3] с преобразованием (переводом) информации из одной формы в другую (см. Рис. 1). Заказчик формулирует свои потребности в ПС в виде некоторых требований. Исходя из этих требований, разработчик создаёт внешнее описание ПС, используя при этом спецификацию (описание) заданной аппаратуры и, возможно, спецификацию базового программного обеспечения. На основании внешнего описания и спецификации языка программирования создаются тексты программ ПС на этом языке. По внешнему описанию ПС разрабатывается также и пользовательская документация. Текст каждой программы является исходной информацией при любом её преобразовании, в частности, при исправлении в ней ошибки. Пользователь на основании документации выполняет ряд действий для применения ПС и осуществляет интерпретацию получаемых результатов. Везде здесь, а также в ряде других процессах разработки ПС, имеет место указанный перевод информации.
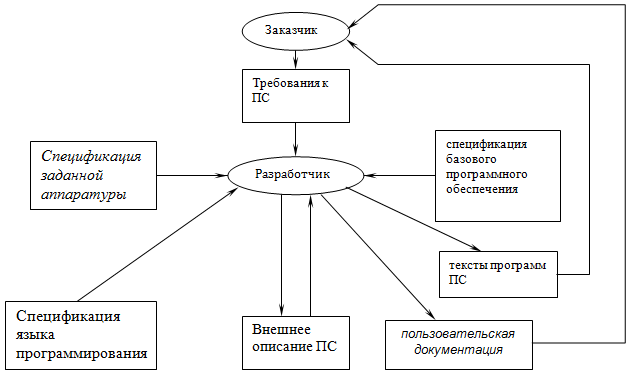
Рисунок 1. Грубая схема разработки и применения ПС
На каждом из этих этапов перевод информации может быть осуществлён неправильно, например, из-за неправильного понимания исходного представления информации. Возникнув на одном из этапов ошибка в представлении информации распространяется на последующие этапы разработки и, в конечном счёте, окажется в самом ПС.
Чтобы понять природу ошибок при переводе рассмотрим модель [3], изображённую на Рис. 2. На ней человек осуществляет перевод информации из представления A в представление B. При этом он совершает четыре основных шага перевода:
- он получает информацию, содержащуюся в представлении A, с помощью своего читающего механизма R;
- он запоминает полученную информацию в своей памяти M;
- он выбирает из своей памяти преобразуемую информацию и информацию, описывающую процесс преобразования, выполняет перевод и посылает результат своему пишущему механизму W;
- с помощью этого механизма он фиксирует представление B.
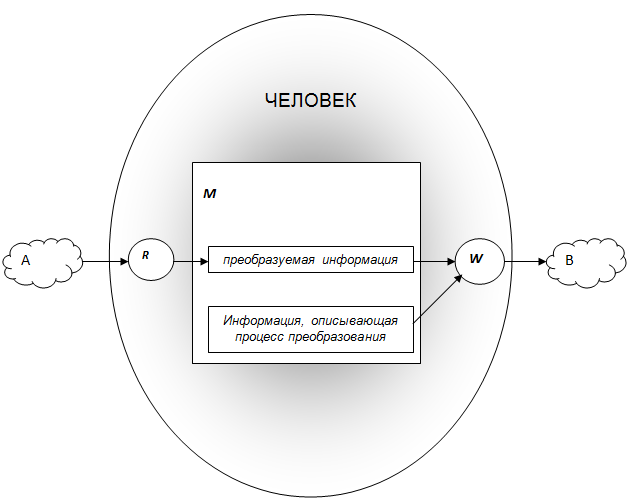
Рисунок 2. Модель перевода
На каждом из этих шагов человек может совершить ошибку разной природы. На первом шаге способность человека «читать между строк» (способность, позволяющая ему понимать текст, содержащий неточности или даже ошибки) может стать причиной ошибки в ПС. Ошибка возникает в том случае, когда при чтении документа A человек, пытаясь восстановить недостающую информацию, видит то, что он ожидает, а не то, что имел в виду автор документа A. В этом случае лучше было бы обратиться к автору документа за разъяснениями. При запоминании информации человек осуществляет её осмысливание (здесь важен его уровень подготовки и знание предметной области, к которой относится документ A). И, если он поверхностно или неправильно поймёт, то информация будет запомнена в искажённом виде. На третьем этапе забывчивость человека может привести к тому, что он может выбрать из своей памяти не всю преобразуемую информацию или не все правила перевода, в результате чего перевод будет осуществлён неверно. Это обычно происходит при большом объёме плохо организованной информации. И, наконец, на последнем этапе стремление человека поскорее зафиксировать информацию часто приводит к тому, что представление этой информации оказывается неточным, создавая ситуацию для последующей неоднозначной её интерпретации.
1.1.4 Источники ошибок программного обеспечения
Известно, что практически во всех более или менее сложных программах (а также в ОС, которая является комплексом многих программ) есть ошибки. Причина этого очевидна-программы делают люди, а люди склонны ошибаться.
Рассмотрим источники ошибок на разных этапах проектирования.
На этапе подготовки технического задания, формирования и утверждения технического задания источниками ошибок могут быть: логическая несогласованность требований, пропусков, неточности алгоритма.
На этапе определения функций отдельных модулей источниками ошибок могут быть: пропуск функций, отсутствие согласованного протокола, допускающего взаимодействие оборудования и программ, неправильный выбор протоколов связи и алгоритмов, неточности, неверная интерпретация технических требований, пропуск определенных информационных потоков.
На стадии разработки и производства соответственно прототипа источниками ошибок могут быть при разработке-упущения некоторых признаков, неправильная интерпретация технических требований, дефект в схемах синхронизации, нарушение правил проектирования; при изготовлении компонентов прототипа - неисправные модули, неисправная сборка; при разработке программного обеспечения-упущение некоторых функций технического задания, неточности в алгоритмах, неточное кодирование.
Каждый из этих источников ошибок может вызвать большое количество субъективных или физических ошибок, которые необходимо локализовать и устранить. Обнаружение ошибок и локализация неисправностей являются сложными по нескольким причинам: Во-первых, из-за большого количества неисправностей; во-вторых, потому, что различные неисправности могут проявляться одинаково. Поскольку нет моделей субъективных ошибок, эта задача не формализована. Был достигнут определенный прогресс в разработке методов и инструментов для обнаружения ошибок, и обнаружения физических неисправностей. Эти методы и средства широко используются для проверки рабочего состояния и диагностики неисправностей дискретных систем при проектировании, изготовлении и эксплуатации последних.
Субъективные недостатки отличаются от физических тем, что после обнаружения, локализации и коррекции они больше не возникают. Однако, согласно перечню источников ошибок, субъективные ошибки могут быть введены при разработке спецификации системы, что означает, что даже после самого тщательного тестирования системы на соответствие ее внешним спецификациям, система может иметь субъективные ошибки.
Процесс проектирования является итерационным процессом. Неисправности, обнаруженные на этапе приемо-сдаточных испытаний, могут привести к корректировке спецификации и, следовательно, к началу всего проектирования системы. Необходимо выявлять неисправности как можно раньше, для этого необходимо контролировать правильность проекта на каждом этапе разработки.
1.1.5 Классификация ошибок программного обеспечения
Рассмотрим классификацию ошибок по месту их возникновения, которая рассмотрена в книге С. Канера "тестирование программного обеспечения". Основные понятия управления бизнес-приложениями. Главным критерием программы должно быть ее качество, которое трактуется как отсутствие в ней недостатков, а также сбоев и явных ошибок. Недостатки программы зависят от субъективной оценки ее качества потенциальным пользователем.
В то же время авторы скептически относятся к спецификации и утверждают, что даже если она имеется, выявленные на заключительном этапе недостатки свидетельствуют о ее низком качестве. При таком подходе преодоление недостатков программы, особенно на заключительном этапе проектирования, может привести к снижению надежности. Очевидно, что такой подход не подходит для разработки ответственного и безопасного программного обеспечения, но проблемы ошибок в спецификациях, субъективной оценки качества программы пользователем существуют и не могут быть проигнорированы.
Необходимо разработать систему определенных ограничений, учитывающую эти факторы при разработке и сертификации такого программного обеспечения. Для обычных программ все проблемы, связанные с субъективной оценкой их качества и наличием ошибок, скорее всего, неизбежны.
В краткой классификации выделены следующие ошибки.
- ошибка пользовательского интерфейса;
- ошибки расчета;
- ошибки управления потоком;
- ошибки передачи или интерпретации данных;
- перегрузки;
- контроль версий;
- ошибка обнаружена и забыта;
ошибки тестирования.
1. Ошибки пользовательского интерфейса.
Многие из них субъективны, потому что они часто являются неудобствами, а не "чистыми" логическими ошибками. Однако они могут спровоцировать ошибки пользователя программы или замедлить время ее работы до недопустимого значения. В результате мы будем иметь ошибки информационной системы (ИС) в целом. Основным источником таких ошибок является сложный компромисс между функциональностью программы и простотой обучения и работы с программой.
Задача должна решаться при проектировании системы на уровне ее декомпозиции на отдельные модули, исходя из того, что вряд ли возможно спроектировать простой и удобный пользовательский интерфейс для модуля, перегруженного различными функциями. Кроме того, следует рассмотреть рекомендации по проектированию пользовательских интерфейсов.
На этапе тестирования программного обеспечения полезно предусмотреть встроенные средства тестирования, которые бы запоминали последовательность действий пользователя, время отдельных операций, расстояние до курсора мыши. Кроме того, можно использовать гораздо более сложные средства психофизического тестирования на этапе тестирования пользовательского интерфейса, которые позволят оценить скорость реакции пользователя, частоту этих реакций, утомляемость и т.д.
Следует отметить, что такие ошибки очень критичны с точки зрения коммерческого успеха разрабатываемого программного обеспечения, так как они будут в первую очередь оцениваться потенциальным заказчиком.
2. Ошибки расчета.
Существуют следующие причины таких ошибок:
- неправильная логика (может быть следствием как ошибок проектирования, так и кодирования);
- арифметические операции выполняются некорректно (как правило-это ошибки кодирования);
- неточные расчеты (могут быть следствием как ошибок проектирования, так и кодирования). Это очень сложная тема, необходимо развивать свое отношение к ней с точки зрения разработки безопасного программного обеспечения.
Выделяются элементы: устаревшие константы, ошибки вычисления; неправильно расставленные скобки, неправильный порядок операторов; неправильно выполняемая базовая функция; переполнение и потеря значащих цифр; ошибки отсечения и округления; путаница с подачей данных; неправильное преобразование данных из одного формата в другой; неправильная формула, неправильная аппроксимация.
3. Ошибки управления потоком.
Этот раздел включает в себя все, что связано с последовательностью и обстоятельствами выполнения программных операторов.
Выделяются подпункты:
- очевидно некорректное поведение программы;
- логика, основанная на определении вызывающей подпрограммы;
- использование таблиц переходов;
- выполнение данных (вместо команд). Ситуация возможна из-за ошибок указателя, отсутствия проверок границ массива, ошибок перехода, вызванных, например, ошибкой в таблице адресов перехода, ошибками сегментации памяти.
4. Ошибки обработки или интерпретации данных.
Выделяются подпункты:
- проблемы при передаче данных между подпрограммами (это включает в себя несколько типов ошибок: параметры указаны в неправильном порядке или пропущены, несоответствие типов данных, псевдонимы и различная интерпретация содержимого одной и той же области памяти, неправильная интерпретация данных, неадекватная информация об ошибке, перед аварийным выходом из подпрограммы, правильное состояние данных не восстанавливается, устаревшие копии данных, связанные переменные не синхронизируются, локальная установка глобальных данных (имеется в виду путаница локальных и глобальных переменных), глобальное использование локальных переменных, недопустимая маска битового поля, недопустимое значение из таблицы);
- границы компоновки данных (это включает в себя несколько типов ошибок: не обозначенный конец строки с нулевым окончанием, неожиданный конец строки, чтение и запись за пределы структуры данных или элемента, чтение вне буферного сообщения, чтение вне буферного сообщения, добавление переменных к полным словам, переполнение и выход за пределы нижнего предела стека данных, затирание данных или кода другого процесса);
- проблемы с обменом сообщениями (это включает в себя несколько типов ошибок: отправка сообщения на неправильный процесс или неправильный порт, ошибка распознавания полученного сообщения, пропущенное или несинхронизированное сообщение, сообщение передается только N процессов из N+1, повреждение данных, хранящихся на внешнем устройстве, потеря изменений, которые вы не сохранили введенные данные, объем данных слишком велик для обработки-получатель, неудачная попытка отменить запись данных).
5.Повышенная нагрузка.
Дополнительные ошибки могут возникнуть, если рабочая нагрузка высока или ресурсов недостаточно. Выделяются элементы: необходимый ресурс недоступен, не освобождается ресурс; отсутствует сигнал на устройстве освобождения; старый файл не удаляется с накопителя; система не возвращается в неиспользуемую память; дополнительное компьютерное время; нет свободного блока памяти достаточного размера; недостаточный размер входного буфера или очереди; не очищается очередь, буфер или стек; теряются сообщения; замедляется производительность; повышается вероятность ситуационных гонок; при высокой нагрузке объем необязательных данных не уменьшается; снижение производительности другого процесса не распознается при высокой нагрузке; низкоприоритетные задания не приостанавливаются.
В этом разделе мы хотели бы обратить внимание на следующее:
- некоторые ошибки в этом разделе могут возникать при не очень высоких нагрузках, но, возможно, они будут возникать реже и с большими интервалами;
- многие ошибки из 2 предыдущих разделов уже в своей формулировке носят вероятностный характер, поэтому следует предположить возможность использования вероятностных моделей и методов их идентификации.
6. Контроль версий и идентификаторов.
Выделенные подпункты таинственно появляются старые ошибки; обновление не всех копий данных или программных файлов; нет заголовка; нет номера версии; неверный номер версии в заголовке экрана; отсутствует или неверная информация об авторских правах; программа, скомпилированная из резервной копии, не соответствует проданному варианту; готовые диски содержат неверный код или данные.
7. Ошибки тестирования.
Это ошибки сотрудников группы тестирования, а не программы. Выделяются подпункты:
- пропущенные ошибки в программе;
- проблема не замечена (отмечаются следующие причины: тестер не знает, каким должен быть правильный результат, ошибка теряется в большом количестве выходных данных, тестер не ожидал такого результата теста, тестер устал и невнимателен, ему скучно, механизм выполнения теста настолько сложен, что тестер уделяет ему больше внимания, чем результатам);
- пропуск ошибок на экране;
- документирована проблема (есть следующие причины для этого: тестер небрежно записывает, тестер не уверен, что эти действия ошибочны, ошибка была слишком незначительной, тестер считает, что ошибка не будет исправлена, тестер попросил не документировать больше подобных ошибок).
8. Ошибка выявлена и забыта.
Описываются ошибки использования результатов тестирования. По-моему, раздел следует объединить с предыдущим. Выделяются подпункты: не составлен итоговый отчет; серьезная проблема не документирована повторно; не проверено исправление; перед выпуском продукта не проанализирован список нерешенных проблем.
Необходимо заметить, что изложенные в 2-х последних разделах ошибки тестирования требуют для устранения средств автоматизации тестирования и составления отчетов. В идеальном случае, эти средства должны быть проинтегрированы со средствами и технологиями проектирования ПО. Они должны стать важными инструментальными средствами создания высококачественного ПО. При разработке средств автоматизированного тестирования следует избегать ошибок, которые присущи любому ПО, поэтому нужно потребовать, чтобы такие средства обладали более высокими характеристиками надежности, чем проверяемое с их помощью ПО.
1.1.6 Основные пути борьбы с ошибками
Учитывая рассмотренные особенности действий человека при переводе можно указать следующие пути борьбы с ошибками:
- сужение пространства перебора (упрощение создаваемых систем);
- обеспечение требуемого уровня подготовки разработчика (это функции менеджеров коллектива разработчиков);
- обеспечение однозначности интерпретации представления информации;
- контроль правильности перевода (включая и контроль однозначности интерпретации).
1.2 Методы структурирования
В общем случае произвольная программа не может быть преобразована в структурированную программу, которая реализует тот же алгоритм, построена с применением тех же конструкций и не использует дополнительных переменных. Такое преобразование возможно при использовании трех известных методов:
- дублирование кодов программы;
- введение переменной состояния;
- метод булевых признаков.
1.2.1 Метод дублирования блоков
Для блокирования (парирования) случайных угроз информационной безопасности в компьютерных системах необходимо решить ряд задач. Дублирование информации является одним из наиболее эффективных способов обеспечения целостности информации. Он защищает информацию как от случайных угроз, так и от преднамеренных воздействий. В зависимости от ценности информации, особенностей структуры и режимов работы КС могут использоваться различные методы дублирования, которые классифицируются по различным критериям.
Согласно времени восстановления информации, методы дублирования можно разделить в:
- оперативный;
- нерабочий.
Оперативные методы включают методы дублирования информации, которые позволяют использовать дублирующую информацию в реальном времени. Это означает, что переход на использование дублированной информации осуществляется во времени, что позволяет выполнить запрос на использование информации в реальном времени для данного КС. Все методы, которые не удовлетворяют этому условию, называются неоперативными методами дублирования. С помощью средств, используемых для целей дублирования, методы дублирования можно разделить на методы, использующие:
- дополнительные внешние запоминающие устройства (блоки);
- специально выделенная область памяти на съемном машиночитаемом носителе;
- съемный носитель.
По количеству копий методы дублирования делятся на:
- одноуровневый;
- многоуровневый.
Как правило, количество уровней не превышает трех. По степени пространственной удаленности основных носителей и дублирующей информации методы дублирования можно разделить на следующие методы:
- целенаправленное дублирование;
- рассеянное дублирование.
Для определенности целесообразно рассматривать методы концентрированного дублирования такие методы, для которых носители с основной и дублирующей информацией находятся в одном помещении. Все остальные методы рассредоточены.
В соответствии с процедурой дублирования различают методы:
- полная резервная копия;
- отражение;
- частичная копия;
- комбинированная копия.
Полная копия дублирует все файлы. При зеркальном копировании любое изменение основной информации сопровождается такими же изменениями избыточной информации. При таком дублировании основная информация и двойник всегда идентичны. Частичное копирование включает в себя создание дубликатов определенных файлов, таких как пользовательские файлы. Один тип частичной копии, называемый инкрементной копией, - это метод создания дубликатов файлов, которые изменились с момента последней копии.
Комбинированное воспроизведение позволяет осуществлять такие комбинации, как полное и частичное резервное копирование с различной периодичностью их проведения. Наконец, по типу дублирующей информации методы дублирования подразделяются на:
- способы сжатия информации;
- методы без сжатия данных.
Жесткие диски и ленточные накопители используются в качестве внешних запоминающих устройств для хранения дублированной информации. Жесткие диски обычно используются для оперативного дублирования информации. Самый простой способ дублирования данных в CS-это использование выделенных областей памяти на рабочем диске. Наиболее важная системная информация дублируется в этих областях. Например, таблицы каталогов и таблицы файлов дублируются таким образом, что они размещаются на цилиндрах и поверхностях жесткого диска (пакета дисков), отличных от тех, на которых расположены рабочие таблицы. Это дублирование защищает от полной потери информации при повреждении определенных участков поверхности диска.
Очень надежным методом оперативного дублирования является использование зеркальных дисков. Зеркало представляет собой жесткий магнитный диск отдельного накопителя, на котором хранится информация, полностью идентичная информации на рабочем диске. Это достигается параллельным выполнением всех операций записи на обоих дисках. При сбое рабочего диска зеркальный диск автоматически переключается в режим реального времени. Информация хранится в полном объеме.
1.2.2 Метод булева признака
Сущность данного метода: в программу, содержащую циклы, вводится некоторый признак. Начальное значение признака задается до цикла. Цикл выполняется, пока признак сохраняет свое исходное значение. Значение признака изменяется при наличии некоторых условий внутри цикла.
Рассмотрим применение метода булева признака на примере преобразования неструктурной схемы, приведенной на рисунке 3.
программа обеспечение ошибка
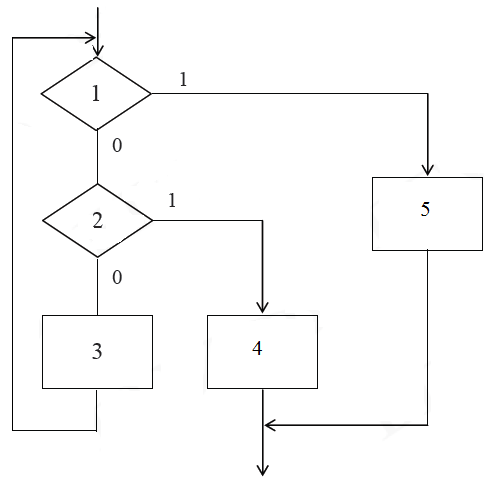
Рисунок 3. Исходная неструктурированная схема
Схема данного алгоритма не является структурированной, поскольку входящий в нее цикл (блоки 1,2,3) содержат вход и два выхода. На схеме 1 и 2 – некоторые условия, определяющие выполнение того или иного участка вычислений, значения 1 и 0 возле выходов символов «Решение» соответствует логическим значениям «да» и «нет».
В соответствии с рассмотренным методом в исходную схему вводится признак (например J). Схема приобретает структурированный вид (рисунок 3) и легко реализуется конструкциями обобщенного цикла и принятия двоичного решения.
Достоинства метода булева признака:
- компактность, экономичность,
- топология исходной схемы изменяется незначительно.
Недостаток: метод предназначен для использования только в циклах.
Иногда можно обойтись без специального признака, используя те условия, которые уже есть в исходной схеме. Например, исходную неструктурированную схему можно представить так, как показано на рисунке 4.
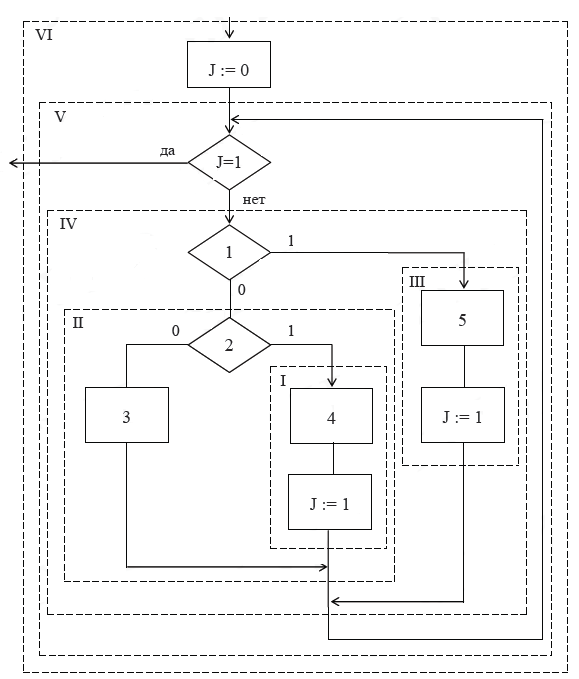
Рисунок 4. Схема, преобразованная по методу булева признака
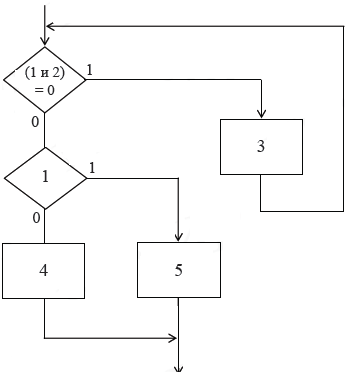
Рисунок 5. Схема, преобразованная без специального признака
На рисунке 4 условие «(1 и 2) = 0» означает, что тело цикла 3 будет выполнено в том случае, если оба условия 1 и 2 не выполняются (равны нулю) Итоговая схема содержит обобщенный цикл с одним входом и одним выходом и конструкцию if-then-else, т.е. является структурированной.
Следует иметь ввиду, что преобразование схемы к структурированному виду без дополнительного признака возможно только при небольшом количестве условий.
1.2.3 Метод введения переменной состояния
Данный метод был впервые предложен Ашкрофтом и Манной.
Рассмотрим применение этого на примере неструктурированной программы, алгоритм которой представлен на рисунке 6.
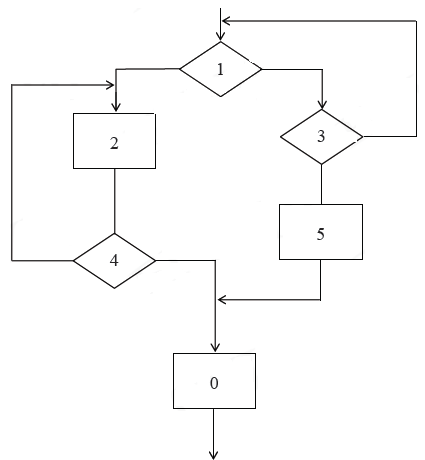
Рисунок 6. Схема алгоритма исходной неструктурированной программы
Данная схема не является структурированной, так как из цикла, состоящего из блоков 1 и 3, существует 2 выхода. Таким образом, нарушено условие «один вход – один выход», которому должны удовлетворять структурированные схемы
Процесс преобразования программы в структурированную состоит из нижеприведенной последовательности шагов.
1. Каждому блоку неструктурированной схемы приписывают номер. Обычно первому блоку присваивается 1, последнему – 0.
2. В программу вводится дополнительная переменная целого типа (например I), называемая переменной состояния.
3. Функциональные блоки исходной схемы заменяются блоками, выполняющими помимо основных функций преобразование переменной I: переменной I присваивается значение, равное номеру блока-приемника в исходной схеме.
4. Аналогично преобразуются логические блоки. При этом если в логическом блоке условие истинно, то это соответствует одному значению I, если ложно – другому.
5. Исходная схема преобразуется к виду, предложенному Ашкрофтом – Манной – рисунок 7.
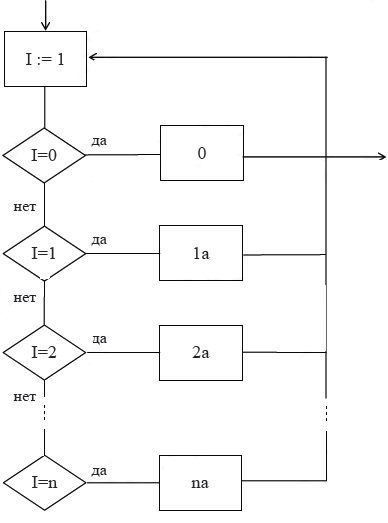
Рисунок 7. Схема алгоритма Ашкрофта – Манны
На данной схеме блоки la – na являются аналогами соответствующих блоков исходной схемы и, помимо этого, присваивают значение переменной I.
В результате преобразований Ашкрофта – Манны исходная неструктурированная схема принимает вид, изображенный на рисунке 8.
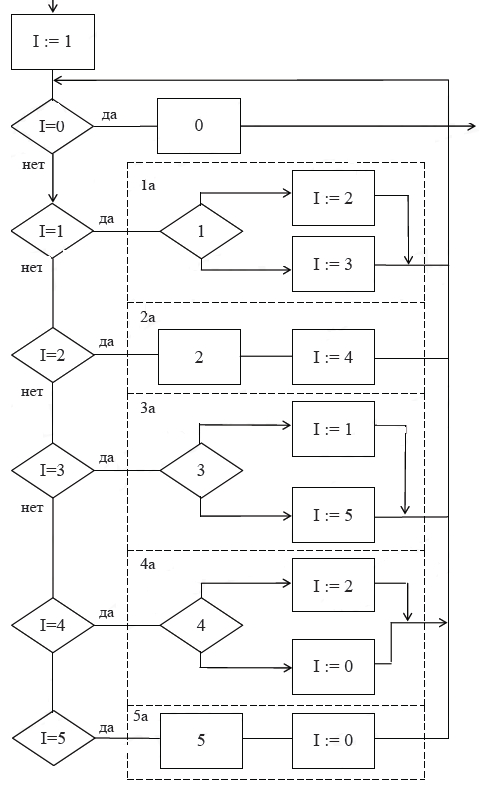
Рисунок 8. Исходная схема, преобразованная по методу Ашкрофта – Манны
При выполнении алгоритма, реализованного по методу Ашкрофта – Манны, переменная состояния I устанавливается в начальное значение, равное номеру первого блока не преобразованной схемы (как правило, это единица). Затем осуществляется последовательный опрос переменной I, начиная с нуля и заканчивая максимальным номером блока исходной схемы (в нашем примере он равен 5). Выполняется тот блок исходной схемы, номер которого соответствует текущему значению I. Помимо этого в I заносится значение, равное номеру того блока исходной схемы, который должен выполняться за текущим блоком. Когда значение I станет равным нулю, выполняется последний раз блок непреобразованной схемы (блок с номером 0) и осуществляется выход из алгоритма.
Полученная по методу Ашкрофта – Манны схема алгоритма является структурированной. Для доказательства этого достаточно последовательно преобразовать данную схему к одному функциональному блоку.
1.2.4 Концептуальное программирование
Концепция – определенный способ понимания или трактовки какого-либо явления или процесса, основная точка зрения, руководящая идея, ведущий замысел, конструктивный принцип различных видов деятельности.
Концепция – это совокупность взаимосвязанных представлений или взглядов на какую-либо проблему (противоречие).
Концептуальное программирование – направление в информатике, основанное на описании понятий для выражения смысла и формы конкретной проблемы, по описанию которой автоматически могут быть получены результаты или синтезируются программы для выполнения.
Концептуальное программирование включает такой сорт программирование как объектно-ориентированное.
При стратегии сначала в ширину дерево поиска обходится ярус за ярусом сверху вниз. Она гарантирует нахождение решения, если оно существует. Однако стратегия требует значительно большего объема памяти и поэтому получила сравнительно небольшое распространение.
Одно из достоинств языков логического программирования состоит в том, что на их основе достаточно удобно реализовать стратегии параллельного типа, причем порядок обхода дерева не столь важен; существен лишь тот факт, что должно быть обойдено все дерево. Именно последнее обстоятельство и дает принципиальную возможность вести поиск параллельно.
Обычно различают два типа параллелизма: ИЛИ - параллелизм, означающий одновременное применение для выделенной подцели из цели всех правил из базы знаний, и И-параллелизм, означающий параллельную обработку одновременно всех литералов (подцелей) целевого утверждения. Кроме того, параллелизм возможен и необходим при унификации (так как эта операция применяется часто). Наибольшие перспективы имеют именно параллельные стратегии, но для их эффективной реализации необходимы соответствующие процессоры, использующие принципы параллельной архитектуры.
К дедуктивным подходам решения задач относится и концептуальное программирование [7]. Этот метод ориентирован в основном на решение так называемых вычислительных задач, т. е. задач, которые могут быть сформулированы в следующем виде.
При заданном описании условий задачи М по значениям переменных х\, х2, ..., хт, удовлетворяющих М, вычислить значения переменных уi, у2, ..., у„, также удовлетворяющих М.
Основу концептуального программирования составляет метод структурного синтеза программ, использующий две эквивалентные формы представления знаний о задачах: формульное представление; графовое представление.
2. ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1 Delphi. Основные понятия и определения
Delphi — среда программирования, в которой используется язык программирования Object Pascal. Начиная со среды разработки Delphi 7.0, в официальных документах Borland стала использовать название Delphi для обозначения языка Object Pascal.
Изначально среда разработки была предназначена исключительно для разработки приложений Microsoft Windows, затем был реализован также для платформ Linux (как Kylix), однако после выпуска в 2002 году Kylix 3 его разработка была прекращена, и, вскоре после этого, было объявлено о поддержке Microsoft .NET. При этом высказывались предположения, что эти два факта взаимосвязаны.
Реализация среды разработки проектом Lazarus (Free Pascal, компиляция в режиме совместимости с Delphi) позволяет использовать его для создания приложений на Delphi для таких платформ, как Linux, Mac OS X и Windows CE.
Также предпринимались попытки использования языка в проектах GNU и написания компилятора для GCC.
2.2 Процесс написания программы
Для начала запустим Delphi. Назовем главную форму приложения «БД Товары». Для этого нажмем на главную форму и в окне инспектора свойств изменим свойство Caption – рисунок 9.
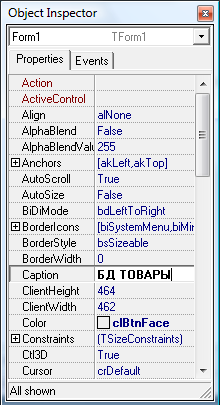
Рисунок 9. Изменение названия главной формы
После этого перейдем в меню инструментов на вкладку ADO – рисунок 10.
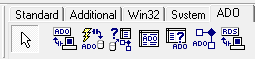
Рисунок 10. Вкладка ADO
На данной вкладке выберем компонент ADOConnection  и положим его на главную форму приложения. Компонент «ADOConnection» используется для создания соединения с базой данных другой системы. В нашем случае соединение будет создаваться с разработанной базой данных «Товары».
и положим его на главную форму приложения. Компонент «ADOConnection» используется для создания соединения с базой данных другой системы. В нашем случае соединение будет создаваться с разработанной базой данных «Товары».
Для настройки соединения выделим компонент ADOConnection1 и найдем в инспекторе свойств свойство ConnectionString – рисунок 11.
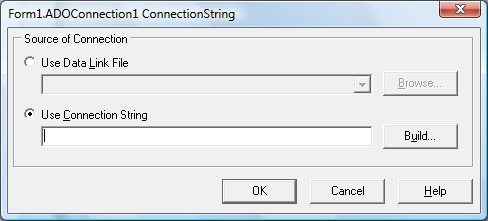
Рисунок 11. ConnectionString
Для назначения конкретной базы данных необходимо нажать Build. После чего выбираем необходимого поставщика услуг – рисунок 12.
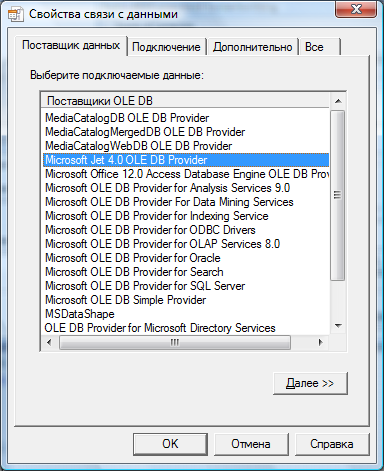
Рисунок 12. Выбор поставщика связи
Далее переходим непосредственно к выбору базы данных. Для этого выбираем вкладку «Подключение» и выбираем конкретную базу данных – рисунок 13.
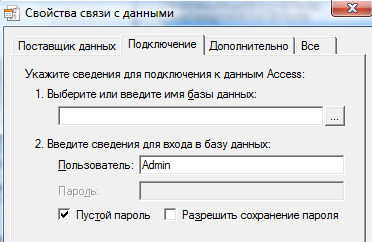
Рисунок 13. Выбор базы данных
После выбора базы данных, нажимаем Ок и переходим на главную форму приложения. Чтобы ADOConnection1 стало активным и другие компоненты смогли бы его использовать, необходимо свойство Connected установить в True. В появившемся окне (рисунок 14) не нужно ничего вводить. Достаточно нажать Ок.
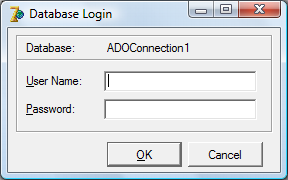
Рисунок 14. Запрос логина и пароля
Разместим на главной форме приложения следующие компоненты с вкладки ADO меню компонент. - ADOTable1. Данный компонент необходим для работы с таблицами базы данных.
- ADOTable1. Данный компонент необходим для работы с таблицами базы данных.
После этого переходим на вкладку DataAccess – рисунок 15.

Рисунок 15. Вкладка DataAccess
На этой вкладке выбираем компонент  и кладем его на форму. Переходим на складку DataControls - рисунок 16.
и кладем его на форму. Переходим на складку DataControls - рисунок 16.

Рисунок 16. Вкладка DataControls
Выбираем компонент DBGrid  и кладем его на главную форму приложения.
и кладем его на главную форму приложения.
Теперь перейдем к настройкам каждого из выбранных компонент. Для каждого из описанных компонент необходимо установить следующие свойства:
ADOTable1.Connection := ADOConnection1;
ADOTable1.TableName := ‘goods’;
ADOTable1.Active := ‘true’;
DataSource1.DataSet := ADOTable1;
DBGrid1.DataSource := DataSource1;
После чего ты увидим, что товары появились на форме – рисунок 16.
Для удобной навигации по базе данных необходимо разместить на главной форме приложения  DBNavigator1. Этот компонент предназначен для быстрого перемещения по базе данных, а также вставки, удаления, редактирования базы данных.
DBNavigator1. Этот компонент предназначен для быстрого перемещения по базе данных, а также вставки, удаления, редактирования базы данных.

Рисунок 17. БД Товары на форме
Настроим его следующим образом:
DBNavigator1. DataSource := DataSource1;
Запустим приложение при помощи кнопки запуска – рисунок 18.
Рисунок 18. Запуск приложения
После запуска приложение будет выглядеть следующим образом – рисунок 19.
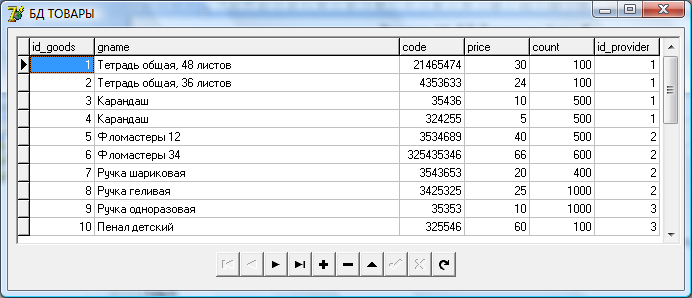
Рисунок 19. Запущенное приложение
Данное приложение позволяет работать с базой данных «товары».
ЗАКЛЮЧЕНИЕ
В процессе написания курсовой работы и программы были получены навыки работы в среде разработки Delphi 7, достигнуты поставленные задачи и цели: разработка программы «Построитель графиков», написание руководства пользователя и т.д.
В главе Детерминированное программирование мы узнали основные понятия и определения, а также разобрали различные виды и ответвления этого программирования.
В главе Руководство пользователя были рассмотрены определения и правила написания руководства пользователя.
В заключительной главе было сделано обоснование темы, рассказано о языке Delphi. Данная глава содержит иллюстрации, что во многом облегчает работу пользователю.
Таким образом, мы можем сказать, что задачи были решены, а поставленная цель достигнута.
Написанная программа называется «Построитель графиков». Она может претендовать на математический, физиологический инструмент, в помощь тем, кто пишет рефераты, курсовые, дипломные используя в них графики. Основное отличие от аналогов – график рисуется по точкам, в процессе соединение точек можно убрать, что очень удобно для наглядности.
К основным возможностям программы можно отнести то, что значения вводятся в таблицу x,y от 0 до 13, вывод графика на Form2, возможность корректировать значения Form1 не выключая Form2 и получить другой результат, а также внешний вид программы прост и понятен в использовании.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Ахо А., Ульман Дж. «Теория синтаксического анализа, перевода и компиляции» в 2 тт., том 1, М., Мир, 2016.
- Братчиков И.Л. «Синтаксис языков программирования» Наука, М: Инси, 2015. – 344 с.
- Гулидов А.И., Наберухин Ю.И. Диалектика необходимого – случайного в свете концепции динамического хаоса. 2017. – № 1(9). – С.33–46.
- Дейкстра Э. Заметки по структурному программированию - М: Дрофа, 2016, - 455 с.
- Ершов А.П. Введение в теоретическое программирование - М: РОСТО, 2018, - 288 с.
- Захарова И.Г. Информационные технологии в образовании: Учеб. пособие для студ. высш. пед. учеб. заведений. – М.: Издательский центр «Академия», 2015. – 192 с.
- Кнут Д. Искусство программирования для ЭВМ, т.1. М.: 2016, 735 с.
- Коган Д.И., Бабкина Т.С. «Основы теории конечных автоматов и регулярных языков. Учебное пособие» Издательство ННГУ, 2017. - 97 с.
- Майерс Г. Надежность программного обеспечения - М: Дрофа, 2018, - 360 с.
- Мендельсон Э. Введение в математическую логику, М: Инси, 2018, - 320 с.
- Рудаков А. В. Технология разработки программных продуктов. М: Издательский центр "Академия", 2016. – 306 с.
- Свешникова Е.Ю. Анализ режимов детерминированного хаоса в переходных процессах электроэнергетических систем. М: Издательство «Агат», 2016. - 181 с.
- Тыугу, Э.Х. Концептуальное программирование. - М.: Наука, 2017, - 256 с.
- Хопкрофт Дж., Мотвани Р., Ульман Дж. «Введение в теорию автоматов, языков и вычислений» - М.: Издательство ВИЛЬЯМС, 2018. - 527с.
- Хьюз Дж., Мичтом Дж. Структурный подход к программированию -М: Мир, 2016, - 278 с.
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, DB, ADODB, Grids, DBGrids, ExtCtrls, DBCtrls;
type
TForm1 = class(TForm)
ADOConnection1: TADOConnection;
ADOTable1: TADOTable;
DataSource1: TDataSource;
DBGrid1: TDBGrid;
DBNavigator1: TDBNavigator;
procedure FormCreate(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.FormCreate(Sender: TObject);
begin
ADOTable1.Connection := ADOConnection1;
ADOTable1.TableName := ‘goods’;
ADOTable1.Active := ‘true’;
DataSource1.DataSet := ADOTable1;
DBGrid1.DataSource := DataSource1;
DBNavigator1. DataSource := DataSource1;
ADOTable1.Connection := ADOConnection1;
ADOTable1.TableName := ‘goods’;
ADOTable1.Active := ‘true’;
DataSource1.DataSet := ADOTable1;
DBGrid1.DataSource := DataSource1;
DBNavigator1. DataSource := DataSource1;
end;
end.
Размещено на Allbest.ru

- Обзор языков программирования высокого уровня Определение языка программирования)
- Информационная система повышения эффективности компании по обслуживанию компьютеров
- Финансовые Рынки
- Анализ доходов и расходов банка на примере ПАО «ФК Открытие»
- Понятие и признаки государства ( Сущность государства)
- Теории происхождения государства (Синтезный путь развития государства)
- Понятие правонарушения ( Виды)
- Коммерческая деятельность розничного торгового предприятия и ее совершенствование (на примере конкретной организации)
- Антикризисное управление: понятие, цели и проблемы
- Организация заработной платы. Понятие тарифной системы, форм и систем заработной платы (Формы коллективного премирования)
- Понятия и признаки государства (Территориальная организация населения и публичная (государственная) власть)
- Изучение составляющих социального обеспечения