
Распределенная технология обработки информации (История развития распределенных вычислительных систем)
Содержание:

Введение
Конкуренция на рынке постоянно возрастает. Технологические инновации снижают барьер входа новых участников на рынок и когда-то эксклюзивные товары и сервисы становятся широкораспространенными, а рынок перенасыщенным. В этих условиях для выживания бизнес должен быть более эффективным, чем его конкуренты: продуктивность сотрудников должна быть выше, а предоставляемые товары и сервисы должны лучше соответствовать потребностям покупателя. За последнее время требования к информационным системам автоматизации бизнес процессов существенно изменились. Опережающими темпами растет количество хранимой, обрабатываемой и передаваемой ими информации. Что в свою очередь вызвано экспоненциальным развитием технологии, а также возросшей зависимостью человечества от использования этих технологий. Прежние подходы к разработке информационных систем становятся неэффективными, так как производительность аппаратной части хотя и удваивается каждые два года, как было предсказано Г. Муром [1], не может покрыть полностью потребности в вычислительных мощностях. Ниже приведена диаграмма объема обрабатываемых информационными системами данных по результатам статистических исследований европейской экономической комиссии ООН[2].
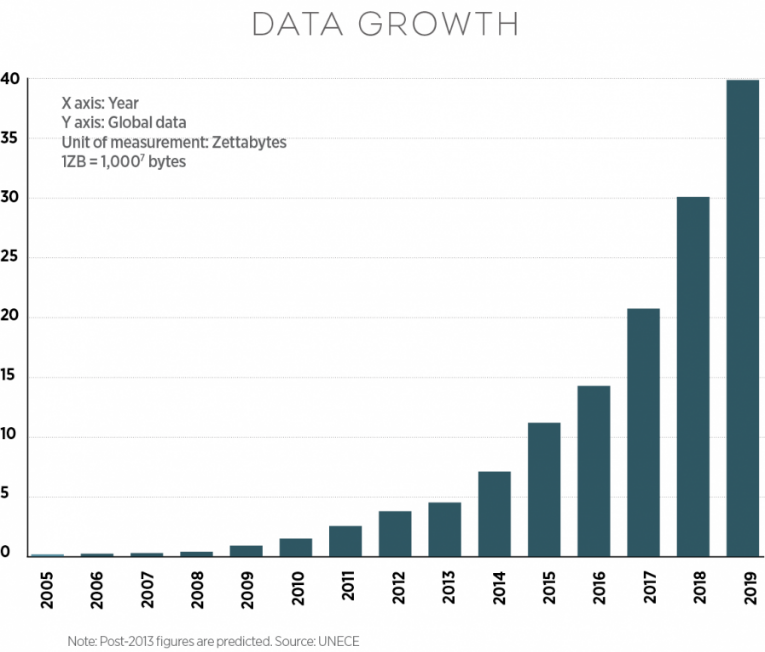
Рис. 1 Глобальный рост объема данных по годам
При сравнении роста объема данных с ростом вычислительных мощностей в относительных единицах эта тенденция видна довольно четко:
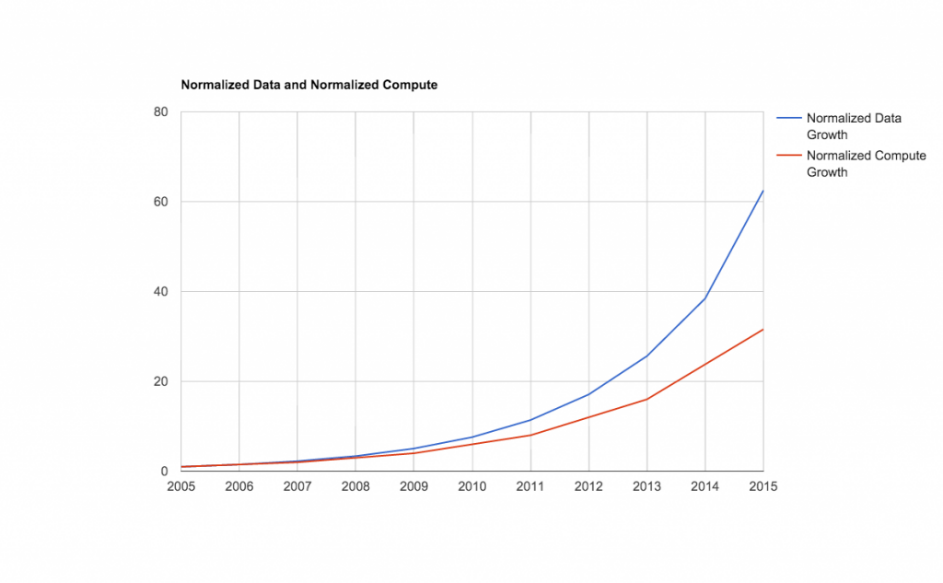
Рис. 2 Сравнение роста производительности и объема данных в относительных единицах
Таким образом появились предпосылки к широкому использованию распределенных систем. В условиях, когда одна машина не может обеспечить требуемых характеристик по вычислительной мощности, памяти или дисковому пространству логичным является распределение нагрузки на несколько машин. Этим обусловлена актуальность выбора темой данной работы исследование различных типов распределенных вычислительных систем, особенности их программной и аппаратной организации. Также в качестве примера полученные знания будут применены для решения прикладной задачи по разработке распределенной системы автоматизации бизнес-процесса. В первой главе будут рассмотрена самая общая информация о распределенных системах обработки информации, основные типы, архитектура, особенности разработки и применения. За основу для исследования будут взяты книги известных международных издательств, таких как John Wiley & Sons, Inc, McGraw-Hill, Apress, O’Reilly Media, Inc., специализирующихся на выпуске академических изданий, технической и инженерной литературы для профессионалов, преподавателей, исследователей и ученых. Большой тираж выбранных изданий, репутация издательств, наличие независимых рецензентов и подтвержденная на практике в ведущих компаниях мирового уровня компетентность авторов – это залог актуальности и достоверности информации, изложенной в выбранной литературе. Также использовались издания по тематике распределенных вычислительных систем российских ВУЗов. Во второй главе на основе полученной информации и реальной прикладной задачи будет разработан проект системы автоматизации. В третьей главе будет рассмотрена реализация программного обеспечения.
1. Теоретическая часть
1.1 История развития распределенных вычислительных систем
ENIAC (Electronic Numerical Integrator and Computer) - один из первых известных компьютеров (после Z3 в 1941 и Colossus в 1943), был разработан Джоном Моучли (1907–1980) совместно с Джоном Эккертом (1919–1995) по контракту с министерством обороны США в 1946. И в своей конструкции он поддерживал возможность параллельных вычислений. Машина считала в двоичной системе счисления и производила 5 тыс. операций сложения или 300 операций умножения в секунду, весила 30 т и для ее размещения требовалось 170 м2. Существенным недостатком этой системы была крайне примитивная система ввода программ. Если требовалось перейти от вычислений баллистических таблиц к расчету параметров аэродинамической трубы, то приходилось бегать по комнате, подсоединяя и отсоединяя сотни контактов, как на ручном телефонном коммутаторе. Сложность ввода программ стала причиной того, что возможности машины по параллельной обработке задач так и не были использованы [[1]].
В течение последующих десятилетий в основном применялись последовательные методы обработки информации. С активным внедрением транзисторов в 1950-х гг. связано рождение второго поколения компьютеров. Один транзистор был способен заменить 40 электронных ламп. В результате быстродействие машин возросло в 10 раз при существенном уменьшении веса и размеров. В компьютерах стали применять запоминающие устройства из магнитных сердечников, способные хранить большой объем информации [[2]].
Начало 60-х годов ознаменовано появлением первых интегральных схем (ИС). Первая интегральная схема (ИС) представляла собой тонкую германиевую пластинку длиной 1 см. Это устройство не отличалось особым изяществом. Пять компонентов схемы были изолированы друг от друга благодаря своей форме в виде букв U, L и т. п. Крошечные проволочки, соединяющие компоненты схемы друг с другом и с источником питания, просто припаивались. Вся конструкция скреплялась воском. До изобретения интегральной схемы (1959) каждый компонент электронной схемы изготавливался отдельно, а затем они соединялись пайкой. Появление ИС изменило всю технологию. Электронная аппаратура стала дешевле, универсальней, малогабаритней, надежней и более быстродействующей, поскольку электрическим импульсам приходилось преодолевать меньшие расстояния. Существенно уменьшились габариты машин. Появление чипа знаменовало рождение третьего поколения компьютеров, проектирующихся на основе интегральных схем малой (МИС – 10–100 компонентов на кристалл) и средней (СИС – 100–1000 компонентов на кристалл) степени интеграции [[3]].
В ходе дальнейшего развития появляется такое понятие как «суперкомпьютер». Авторство термина «суперкомпьютер» приписывается Джорджу Мишелю и Сиднею Фернбачу, в конце 60-х годов XX века работавшим в Ливерморской национальной лаборатории и компании CDC. Тем не менее, известен тот факт, что ещѐ в 1920 году газета New York World рассказывала о «супервычислениях», выполняемых при помощи табулятора IBM, собранного по заказу Колумбийского университета. В общеупотребительный лексикон термин «суперкомпьютер» вошёл благодаря распространённости компьютерных систем Сеймура Крея, таких как, CDC 6600, CDC 7600, Cray-1, -2, -3, -4. Сеймур Крей разрабатывал вычислительные машины, которые, по сути, становились основными вычислительными средствами правительственных, промышленных и академических научно-технических проектов США с середины 60-х годов до 1996 года. Технологии того времени делали эти машины очень дорогими. К примеру, наиболее успешная модель из линейки Cray-1 (1976) стоил 8.8 млн. долларов и весил 5 тонн. В то же время выдавая по современным меркам не такую высокую производительность в 166 MegaFLOPS (миллионов операций с числами с плавающей точкой в секунду) [[4]].
В общем случае, можно говорить, что суперкомпьютер — это компьютер значительно более мощный, чем доступные для большинства пользователей компьютеры, а скорость технического прогресса сегодня такова, что нынешний лидер по производительности легко может стать через несколько лет обычной компьютерной системой, доступной простому пользователю [[5]]. Характерной особенность архитектуры этих систем было применение векторных команд, работающих с целыми массивами независимых данных и позволяющих эффективно использовать конвейерные функциональные устройства [[6]]. Векторные архитектуры суперкомпьютеров преобладали вплоть до 90-х годов. Появившийся в 1988 Cray Y-MP также был основан на этом принципе, но в то же время включал в себя не одно, а от четырех до восьми полноценных векторных процессорных устройств. После чего архитектурный параллелизм начал развиваться в двух направлениях – векторный и мультипроцессорный.
Традиционным языком разработки математических вычислительных программ был Фортран. Язык быстро развивался для поддержки алгоритмов параллельного программирования. Но существенным недостатком все еще оставалась необходимость глубокого понимания архитектуры каждой конкретной машины для того чтобы полноценно использовать все преимущества параллельных вычислений. При переходе к более продвинутой модели суперкомпьютера с более совершенной архитектурой приходилось переписывать все программы, чтобы использовать возможности параллелизма. Что могли позволить себе только очень крупные организации, как например армия, большие концерны производителей, государственные исследовательские центры и т.п.
В начале 80-х с развитием локальных вычислительных сетей появляются ранние распределенные системы. Они обычно состояляли из 10 – 100 узлов, объединенных локальной вычислительной сеть. Их взаимодействие с глобальной сетью было как правило очень ограничено. Внутри сети предоставлялся небольшой набор сервисов таких как: общие принтеры, файловы и почтовые серверы, сервисы передачи файлов через интернет. Системы были как правило гомогенны, а открытость стандартов не ставилась в приоритет [[7]].
В ходе дальнейшего развития сетей со второй половины 1990-х появляются кластеры компьютеров. Поначалу это был способ постройки «суперкомпьютера для бедных»: материнские платы персональных компьютеров соединялись через локальную сеть. Первые конфигурации обычно включали от 64 до 128 узлов. С развитием технологии кластеры стали состоять из тысяч машин, при этом связь осуществлялась через оптическое волокно. К примеру, суперкомпьютер Jaguar (2009) размещен в Национальном центре компьютерных исследований в Окридже (США) и используется Министерством энергетики США для моделирования физических систем. Jaguar содержит 18688 вычислительных ячеек по 2 четырехъядерных процессора и еще 7832 ячеек с одним четырехъядерным процессором. Конструктивно 4 вычислительных процессорных элемента объединяются в Cray XT4 в один вычислительный blade-сервер. Пиковая производительность достигала 1.75 PetaFLOPS [[8]].
Низкая стоимость кластеров значительно увеличила доступность суперкомпьютеров для рядовых потребителей, поэтому большинство современных суперкомпьютеров относятся к этому классу. Компании, продававшие «традиционные суперкомпьютеры» ушли с рынка или снизили свою активность.
Другой аспект нового поколения суперкомпьютеров, обеспечивший им такую популярность это более простая модель программирования по сравнению с прежними системами и возможность переносимости - повторного использования кода. Причина в том, что парадигмы параллельного программирования в данном случае не привязаны к архитектуре конкретной машины. То есть могут быть использованы классические приемы распараллеливания алгоритмов, которые будут работать при переносе кода программы с одной машины на другую [[9]]. В некоторой степени глобальную сеть интернет также можно рассматривать как огромный суперкомпьютер – как например в случае с приложением SETI@home. SETI (Search for Extraterrestrial Intelligence) – некоммерческий проект, использующий свободные ресурсы на компьютерах добровольцев, для поиска внеземного разума. Другой известный проект - расшифровка геномов, а том числе и человека. Эти системы включали в себя десятки тысяч машин. Основным отличием от полноценных кластеров было то, что узлы не соединены высокоскоростными каналами передачи данных. Также не требовалась проверка безопасности при обмене между узлами [[10]].
Таким образом в настоящее время проблема распределенных вычислений сводится к проблеме соответствующего программного обеспечения.
1.2 Особенности распределенных систем
Распределенная система — это совокупность отдельных сущностей, которые взаимодействует для решения общей задачи, которую они не могли бы решить в одиночку. Распределенные системы существовали с момента зарождения Вселенной: например, различные экологические экосистемы можно рассматривать как распределенные. С широким распространением вычислительных сетей появилось понятие распределенных вычислительных систем. Это совокупность как правило автономных процессоров, взаимодействующих по некоторой сети связи [[11]]. Или другими словами, распределенная вычислительная система — это набор независимых компьютеров, представляющийся их пользователям единой объединенной системой [[12]].
Рассмотрим относительно общую, но очень важной моделью современной вычислительной системы, сформулированной в первой половине XX века математиком Фон-Нейманом. Эта модель оказалась базовой при проектировании практически всех современных компьютерных систем, включая суперкомпьютеры. Модель состоит из четырех ключевых компонентов:
Система памяти, которая хранит как команды, так и данные. Известна как система с хранимой программой. Доступ к этой памяти осуществляется с помощью регистра адреса (memory address register, MAR), куда подсистема памяти помещает адрес ячейки памяти, и регистра данных (memory data register, MDR), куда она помещает данные из ячейки с указанным адресом.
По крайней мере один блок обработки данных, наиболее известный как арифметико-логическое устройство (ALU). Эти блоки чаще называют центральными процессорами (CPU). Этот блок отвечает за выполнение всех команд. Процессор также имеет небольшой объем памяти, называемый набором регистров. Обсуждение процессоров будет более подробным.
Блок управления, отвечающий за операции между компонентами модели. Включает в себя счетчик команд, содержащий следующую команду для загрузки, и регистр команд, в котором находится текущая команда.
Системе необходим энергонезависимый способ хранения данных, а также выдачи их пользователю и принятия входных данных. Это осуществляется подсистемой ввода-вывода (I/O).
Несмотря на существенный прогресс в компьютерной технике за последние 60 лет, устройство компьютеров по-прежнему умещается в этих рамках. Несмотря на то, что компьютеры стали мощнее, а области их применения стали столь велики, что их невозможно было даже представить в конце второй мировой войны, основные идеи, заложенные фон Нейманом и его коллегами, среди которых были Алан Тьюринг, Энрико Ферми и другие видные ученые, пригодны и сегодня [[13]].
Компьютеры, входящие в вычислительную сеть, могут разнесены на значительные расстояния друг от друга. Они могут находиться на разных континентах, в одном здании или же в одной комнате. Отсюда вытекают следующие требования к распределенным вычислительным системам:
Параллельность выполнения. В группе нескольких компьютеров программы выполняются параллельно и независимо на каждой машине. Производительность системы в целом может быть увеличена добавлением новых узлом к сети. При этом особую важность приобретает логика координации параллельно выполняющихся программ при доступе к разделяемым ресурсам.
Отсутствие общих физических часов. Когда программам необходимо скоординировать действия они договариваются только через обмен сообщениями. Взаимодействие в пределах одной машины обычно тесно связано с понятием времени, когда данное событие произошло или команда была отправлена. Но в случае взаимодействия по вычислительной сети такой метод наталкивается на препятствие в виде точности, с которой возможно синхронизировать время на машинах, принадлежащих данной системе. Это прямое следствие факта, что взаимодействие внутри распределенной системы возможно только путем отправки асинхронных сообщений по коммуникационной сети [[14]].
Отсутствие общей памяти. Ключевая особенность распределенных систем, которая требует использования сообщений для обмена информацией. Эта особенность так же ведет к отсутствию общих часов. В то же время существуют различные методы для организации абстракции общего адресного пространства.
Пространственная распределённость. Возможны различные конфигурации распределенных систем. Например, соединенных посредством WAN (международной сети) или LAN (локальной вычислительной сети) – NOW/COW сеть/кластер рабочих станций.
Автономность и гетерогенность. Узлы распределенной сети слабо связаны, работают на разных скоростях и могут управляться разными операционными системами. Обычно они взаимодействуют друг с другом путем предоставления определенных сервисов или совместного решения поставленной задачи [[15]].
Независимость отказов. В практически любой компьютерной системе может возникнуть неисправность. Это является обязанностью системного архитектора спланировать ответы на случаи возможных отказов в работе. В случае распределенных систем появляются новые типы отказов. Ошибки в работе сети могут привести к изоляции отдельных узлов от остальной системы при том, что программа на этих узлах все еще может корректно выполняться. При это она может и не знать, что сетевое соединение не доступно или работает в нештатном режиме. С другой стороны, непредвиденное выключение отдельного компьютера или завершение запущенной на нем программы может остаться незамеченным для остальных компонентов системы в течение некоторого отрезка времени. Любой компонент распределенной системы может отказать независимо при том, что остальная система продолжить исправно работать. Чем больше компонентов входит в систему, тем вероятнее отказ. К примеру, на единичной машине вероятность отказа в течение часа практически нулевая, в то время как в системе из 10000 машин она приближается к 100%. Поэтому для распределенных систем необходимо создавать специальные механизмы разрешения таких ситуаций, предусматривать в программах возможности возникновения описанных проблем и закладывать в алгоритмы способы разрешения [[16]].
Возможность построения распределенных систем еще не означает полезность этого. Современная технология позволяет подключить к персональному компьютеру четыре дисковода. Это возможно, но бессмысленно [[17]]. Далее рассмотрим задачи, решаемые с помощью построения распределенной системы:
Поддержка изначально распределенных вычислений. Во многих типах приложений, таких как, например, перевод денежных средств в банковских системах, или же, например, достижение консенсуса между географически удаленными группами, задача изначально подразумевает распределенные вычисления.
Разделение общих ресурсов. Периферийные устройства (например, принтеры), полные базы данных, специальные библиотеки не могут полностью дублироваться на каждом узле системы, так как это не практично и не эффективно с точки зрения затрат. К тому же ресурсы такого типа не получится разместить на узле, та как он станет узким местом всей системы. Поэтому эти ресурсы распределяют по многим узлам системы.
Предоставление доступа к географически удаленным ресурсам. В некоторых случаях данные не могут быть дублированы на каждом узле из-за их размера или требований безопасности. К примеру, финансовые данные международной корпорации слишком объемисты для дублирования в каждом подразделении, поэтому они хранятся на центральном сервере [[18]].
Улучшенная надежность. Распределенные системы изначально хорошо справляются с возникновением неисправности за счет дублирования ресурсов на различных узлах. Выход из строя всех узлов значительно менее вероятен, чем выход из строя одного узла. Надежность включает несколько аспектов: улучшение доступности, улучшенная целостность данных, повышение устойчивости к отказам. Основным аспектом как правило считается доступность ресурсов. Доступность – это свойство вычислительной системы быть работоспособной тогда, когда это требуется. Важность этого аспекта обусловлена тем. Что если система не работает, то остальные ее достоинства не важны [[19]]. К причинам плохой доступности относят [[20]]:
- Нехватка вычислительных ресурсов
- Незапланированное увеличение нагрузки на систему
- Увеличение количества компонентов системы, которое может привести к непредвиденным взаимодействия внутри системы
- Проблемы во внешних зависимостях системы
- Технический долг (деградация качества программного кода системы)
Доступность измеряется в процентах времени, в течение которого системы была работоспособной за некоторый интервал времени (обычно это месяц или год). Общепринятые в современных проектах обозначения уровней доступности системы задаются количеством девяток [[21]]:
|
Количество девяток |
Доступность |
Простой системы в месяц |
|
2 |
99% |
432 мин |
|
3 |
99.9% |
43 мин |
|
4 |
99.99% |
4 мин |
|
5 |
99.999% |
26 сек |
|
6 |
99.9999% |
2.6 сек |
Для интернет-приложений приемлемым считается уровень трех девяток.
Улучшенное отношение производительность/стоимость. Распределение нагрузки на несколько машин как правило дает лучшие результаты чем использование специализированных высокопроизводительных одиночных машин.
Модульность и взаимозаменяемость. Узлы системы могут быть легко добавлены или заменены при условии, что используется совместимое программное обеспечение [[22]].
Масштабируемость. Масштабируемость – это способность подстраивать количество компонентов системы для достижения максимальной эффективности. Обычно это означает способность обработать больше данных, транзакций, запросов без ухудшения пользовательского опыта от пользования системой. Масштабируемость подразумевает как возможность увеличения емкости, так и ее уменьшения простым и дешевым способом [[23]].
Различают 3 направления масштабирования:
- Обработка большего объема данных. Например, с развитием компании приходится обрабатывать больше клиентских профилей или карточек товаров
- Обработка более высокого уровня параллельности. То есть сколько пользователей одновременно могут использовать приложение.
- Обработка большей интенсивности запросов. Это другое измерение предыдущего пункта – насколько часто отдельный пользователь может обращаться к приложению
Типовые архитектуры распределенных систем:
Remote Procedure Call. Использовался в ранних распределенных системах. Состоит из двух ассиметричных узлов – вызывающего и отвечающего. Вызывающий отправляет сообщение отвечающему с параметрами и ожидает прихода ответа. После выполнения вычислений отвечающий отправляет результат вызывающему, после чего он продолжает выполнение программы. При этом адресация в данной системе задавалась жестко – и вызывающий и отвечающий должны были знать друг друга.
Клиент-Сервер. Логичное улучшение предыдущего механизма. За счет динамической адресации система стала более гибкой. Механизм регистрации серверов предоставил возможность динамического выбора сервера.
Master-Slave (Ведущий–ведомый). Модификация предыдущей архитектуры, при которой инициатива в обмене исходит от одного узла – ведущего. Ведущий раздает задачи ведомым и агрегирует результат.
Peer-to-peer (Равный-равный). Идентичные узлы взаимодействует друг с другом для достижения общей цели. Взаимодействие как правило происходит через широковещательные сообщения или групповую передачу [[24]].
1.3 Масштабирование веб-приложений
Современные интернет-приложения могут быть отнесены к одному из следующих классов [[25]]:
- Традиционные многостраничные сайты. Нажатие по ссылке или кнопке вызывает новый запрос к веб-серверу и полную перезагрузку страницы
- Одностраничные приложения (SPA). Часть бизнес логики и вся логика отображения перенесены в браузер пользователя за счет использования специализированных JavaScript фреймворков. Функции веб-сервера ограничены предоставлением программного интерфейса к данным системы и аспектами безопасности.
- Гибридные приложения. Аналогичен традиционному многостраничному сайту, но с поддержкой частичного обновления страниц через AJAX. Как правило используется для обеспечения правильной индексации сайта в поисковых системах.
Прикладное программное обеспечение (ПО) может быть представлено в виде набора из трех частей, обычно называемых слоями (или уровнями):
- слой (уровень) логики (алгоритмов) представления, или презентационный слой;
- слой (уровень) бизнес-логики (вычислительных и управляющих алгоритмов), или слой прикладной логики;
- слой (уровень) логики доступа к данным, или слой управления ресурсами.
Происхождение термина «слой» связано с моделью, которая рассматривает каждую часть приложения в зависимости от ее положения относительно пользователя: от «переднего слоя» (front-end) – логики представления до «заднего слоя» (back-end) – логики доступа к данным). Одна из функций «среднего слоя» (бизнес-логики) состоит в обеспечении двунаправленного преобразования между структурами данных высокого уровня переднего слоя и низкоуровневыми структурами заднего слоя [[26]].
Важным свойство компонента системы при масштабировании является отсутствие состояния. Отсутствие состояния означает, что сервис, слой или сервер не хранят важных данных. Как следствие сервисы одного типа являются полностью взаимозаменяемыми, что обеспечивает хорошую масштабируемость. Если сервис не хранит каких-либо важных данных, то с точки зрения клиента он идентичен любому другому сервису такого же типа [[27]].
Рассмотрим особенности масштабирования каждого из этих слоев.
Уровень представления. Front-end. Масштабирование на данном уровне включает в себя следующие компоненты [[28]]:
CDN (Content Delivery Network) – Сервис, который предоставляет возможность глобального распространения статичных файлов (изображения, JavaScript, CSS). Как правило используется сторонний специализированный поставщик данного сервиса. В общем работает как дополнительный кэширующий слой между серверов компании и пользователями. При этом значительно снижая нагрузку на инфраструктуру компании и ускоряя загрузку на стороне пользователя [[29]].
DNS (Domain Name Service) – это первый элемент, к которому обращается пользователь, когда желает посетить веб-сайт. Данный сервис выдает клиенту IP-адрес веб-сервера по имени домена. И может предоставлять компании такие дополнительные возможности, как например выдача адреса ближайшего к пользователю веб-сервера или балансировка на группу веб-серверов [[30]].
Балансировщики нагрузки. Распределяют входящие запросы на группу идентичных серверов, тем самым уменьшая нагрузку. Существуют программные и более быстрые аппаратные балансировщики нагрузки.
Одной из важнейших технологий, применяемых на уровне представления, является кэширование. Вместо добавления новых сервисов для обработки нагрузки можно предотвратить появление этой нагрузки совсем, за счет сохранения предыдущих результатов вычислений [[31]].
Уровень бизнес-логики обычно соответствует веб-сервисам. Основное требования для масштабирования – это отсутствие в них состояния. За счет этого можно получить следующие преимущества:
- Возможность балансировки нагрузки на уровне запроса. Любой экземпляр сервиса может обработать любой запрос.
- Устойчивость к отказам сервисов. При возникновении критической ошибки достаточно исключить сбойный экземпляр из пула балансировщика.
- Возможность выключения сервера для обслуживания в любое время. Достаточно запустить новые экземпляры на другом сервере и перенаправить туда трафик, далее можно выключить обслуживаемый сервер.
- Возможность обновления сервисов без простоя.
- Простое масштабирование путем добавления новых экземпляров сервиса.
- Возможность автоматического масштабирования без участия человека [[32]].
При масштабировании веб-сервисов сложность вызывают распределенные транзакции при работе с бизнес-сущностями. Распределенная транзакция – это последовательность шагов различных сервисов, которые либо все завершаются успешно, либо все отклоняются. Существует два подхода к реализации распределенных транзакций [[33]]:
- 2PC – двух стадийное подтверждение при выполнении запроса к СУБД
- Использование компенсирующих транзакций
На уровне доступа к данным существует несколько приемов для распределения нагрузки:
- Репликация данных. Хранение нескольких копий данных на разных машинах. Применительно к распространённой СУБД Mysql – репликация позволяет синхронизировать состояние между двумя узлами ведущим (master) и ведомым(slave). Существенное ограничение – это возможность записи только в master базу, необходимость полного копирования всех данных, задержка в появлении данных на slave базе [[34]].
- Шардирование. Данные разделяются по какому-либо принципу на более мелкие наборы. Ключевым моментом является выбор принципы разбиения данных. При правильном выборе возможно масштабирование базы данных практически до любых размеров [[35]].
- Использование NoSQL баз данных, которые изначально поддерживают масштабирование.
2. Проектная часть
2.1 Постановка задачи
В качестве прикладной задачи в данной работе выбрано создание модуля мгновенного обмена сообщениями для CRM-системы интернет-магазина. Важность задачи была обусловлена необходимостью оптимизации процесса приемки заказов. Пропускная способность системы приемки заказов (СПЗ) в CRM системе является производной от двух параметров – количество операторов и времени обработки звонка оператором. Поэтому существенный прирост пропускной способности СПЗ даст оптимизация пользовательского интерфейса CRM системы с целью сокращения времени, затрачиваемого оператором на оформление заказа. Одной из причин почему звонок может обрабатываться дольше регламентированного времени, это ситуация, которая требует консультации или вмешательства супервайзера колл-центра. В CRM системе отсутствовали какие-либо программные средства, позволяющие оператору и супервайзеру общаться и обмениваться оперативной информацией, не покидая рабочего места. Поэтому сотрудники колл-центра вынуждены покидать рабочее место и решать вопросы лицом к лицу. На тратится достаточно много времени.
Обязательные требования к функционалу нового модуля CRM-системы:
- Чат включается при входе в клиентское приложение колл-центра.
- Для каждого логина в CRM должна быть заведена своя учетная запись с распознаваемым логином или именем.
- Поддержка мгновенного обмена текстовыми сообщениями между двумя пользователями чата.
- Хранение истории сообщений (сообщения за как минимум последние сутки).
- Поддержка создания групп рассылок. Один пользователь может состоять в нескольких группах.
- Поддержка мгновенной отправки текстового сообщения всем пользователям определенной группы рассылки
- Поддержка не менее двух ролей пользователей: «руководитель» (администратор) с полными правами, в том числе и на блокировку/разблокировку пользователей и модерацию групп рассылок, «оператор» с правами на общение только с пользователями из определенной категории (супервайзерами)
- Желательно также наличие промежуточная роли "супервайзер", для которой открыты все права, кроме блокировки/разблокировки других пользователей в базе чата.
- Ограничение круга пользователей-адресатов сообщения. Для операторов перечень адресатов должен быть ограничен супервайзерами.
- В чате одновременно будут находится в среднем около 100-150 пользователей, однако в пиковые дни эта цифра может вырасти до 400-500. Необходимо обеспечить минимальную нагрузку на сервер.
- Модуль создаваемого чата должны быть максимально автономны и получать из CRM лишь информацию о пользователях (логин, ФИО, роль) и, возможно, сессиях.
- Требования к поддерживаемым сообщениям. Максимальная длина сообщения - 250 символов. Простой текст, с возможностью переноса на новую строку.
Требования к интерфейсу чата:
Расположение окна чата. Удобно было бы расположить его в правом нижнем углу экрана. Любое окно чата может быть свернуто или развернуто:
Рисунок 2.1 Расположение окна чата
Написание сообщений. В раскрытом окне основным управляющим элементом должна быть область с возможностью ввести логин того или иного пользователя для начала чата с ним или выбрать одну из существующих групп рассылок. Желательно в окне чата разместить историю сообщений за последние 5 календарных дней.
Опционально (по усмотрению разработчика) можно указывать дату-время отправки сообщения и логин автора в теле сообщения.
При написании сообщений для участников группы рассылки окно чата у отправителя автоматически не открывается. Макет окна представлен на рисунке:
Рисунок 2.2 Окно написания сообщения
Получение новых сообщений. При получении сообщений должно появляться соответствующее уведомление под заголовком свернутого окна с чатом. Заголовок при этом должен мигать или приобретать яркий заметный цветовой формат. Если при получении сообщений окно с чатом было открыто, появляется дополнительный управляющий элемент "Не прочитано". Сообщение считается новым, только если оно не было прочитано ранее и отправлено не ранее чем сутки назад. Опционально (по усмотрению разработчика) можно при выходе из системы (или не активности пользователя в течение часа или более) помечать все полученные до этого момента сообщения как прочитанные.
2.2 Обоснование проектных решений
Система мгновенного обмена сообщениями – чат – будет разрабатываться с нуля. По требованиям технического задания она должна быть программно обособлена от остальных систем и должна создавать минимальную нагрузку на сервер. Анализ функционала чата позволяет сделать вывод, что от выбираемого языка программирования/технологии требуется хорошая поддержка многозадачности. Многозадачность наиболее просто реализуется в Actor-модели, поэтому во внимание нужно принять наличие удобных библиотек реализующих эту модель программирования. Должны быть доступны бесплатные библиотеки для поддержки протоколов HTTP и Websocket. Также важно максимально уменьшить время разработки данной системы. Исходя из требования по производительности системы можно ограничить рассматриваемый набор распространенными современными компилируемыми языками для платформы Linux: C++, Java, Scala. Исходя из требований наличия библиотек поддержки Actor-модели и скорости разработки для реализации чата был выбран язык программирования Scala с библиотекой Akka.
При разработке системы будет применен подход Event Sourcing, так ка он хорошо сочетается с Actor-моделью. И это означает, что от хранилища данных не требуется поддержка таких возможностей реляционных СУБД, как транзакции и объединение таблиц. Поэтому для хранения данных чата идеально подходит СУБД Mongo, так как позволяет хранить документы без определенной схемы, то есть нет необходимости в этапе проектирования схемы базы данных, что ускоряет процесс разработки и упрощает последующие доработки.
В основе фреймворка Akka (названия взято от горы в Швеции) лежит реализация модели акторов, предназначенная для распараллеливания вычислений. Модель акторов изначально была предложена в статье «Universal Modular Actor Formalism for Artificial Intelligence» вышедшей в 1973 [[36]]. В статье актор определен как активный агент, влияющий на сигнал в соответствии с заложенным алгоритмом. Изначально модель использовалась для узкого круга задач, но в последнее время интерес к данной модели значительно возрос.
Вплоть до середины 90-х годов большинство приложений использовали для работы один однопроцессорный компьютер. Если приложение требовало больше вычислительных ресурсов, то стандартным ответом была установка более мощного процессора или увеличение оперативной памяти без необходимости изменений в коде. В 2005 Херб Суттер в своей статье написал о необходимости изменений такого подхода, так как практически достигнут предел скорости процессора. Для дальнейшего увеличения производительности необходимо распараллеливание задач на несколько потоков [[37]].
Масштабируемость характеризует способность системы подстраиваться к изменениям в нагрузке на систему без уменьшения производительности. Распараллеливание вычислений это один из способов достижения масштабируемости системы. К сожалению, в большинстве языков программирования поддержка параллельных вычислений с тех пор осталась на базовом уровне: программист по-прежнему должен работать с низкоуровневыми абстракциями типа потока или блокировки. Помимо распараллеливания вычислений на одном компьютере (подход Scale-Up –масштабирование вширь) возможно распараллеливание за счет добавления большего количества компьютеров (подход Scale-Out –масштабирование вверх). На этом направлении также по сути мало что изменилось: в большинстве технологий для выполнения вычислений на другом компьютере используется синхронный запрос по сети. С другой стороны, развитие многопроцессорных систем и облачных вычислений сделало легко доступными дополнительные вычислительные ресурсы. Но использование этих ресурсов проблематично, так как существенно повышает сложность программного обеспечения при разработке его прежними методами, не ориентированными на распределенные и параллельные вычисления [[38]].
Этот пробел был заполнен фреймворком Akka, который используя модель акторов скрывает от программиста сложности организации параллельных и распределенных вычислений и позволяет масштабировать программу как вверх, так и вширь. Данный фреймворк разработан под влиянием идей из манифеста реактивного программирования (Reactive Manifesto) – набора принципов для разработки надежных, устойчивых и гибких систем, которые удовлетворяют современным требованиям:
Блокирующий ввод-вывод ограничивает возможности использования параллельных вычислений, поэтому предпочтителен неблокирующий
Синхронные взаимодействия ограничивают параллелизм, поэтому предпочтительны асинхронные
Использование подхода с опросом ресурса повышает использование вычислительных мощностей, поэтому предпочтителен событийный подход
Если один узел может привести к отказу всей системы, то необходимо его изолировать
Система должна быть гибкой в использовании ресурсов: при низкой нагрузке – меньше ресурсов, с увеличением ресурсов – больше ресурсов
Данные принципы приводят к следующим отличиям от традиционной модели:
Таблица 2.1
Отличия классического подхода от принципов Reactive Manifesto [[39]]
|
Цель |
Традиционный подход |
Подход Akka |
|
Масштабирование |
Использование потоков, разделяемого изменяемого состояния в базе данных и синхронных веб-сервисов |
Акторы принимают и отправляют сообщения. Отсутствует разделяемое изменяемое состояние. Используется журнал неизменяемых событий. |
|
Получение информации реального времени |
Периодический опрос текущего состояния |
Событийный подход – событие передается в заинтересованные подсистемы |
|
Масштабирование вширь в сети |
Синхронный вызов сервисов, блокирующий ввод-вывод |
Асинхронная передача событий, неблокирующий ввод-вывод |
|
Обработка ошибок |
Обработка всех ошибок. Работа программы прекращается в случае необработанной ошибки |
Ошибки изолируются в отдельные подмодули. Работа приложения продолжается при ошибке в подмодуле. |
|
Хранение данных при перезапуске и завершении программы |
Использование базы данных для хранения разделяемого изменяемого состояния |
Состояние хранится в памяти и восстанавливается из журнала событий |
Фреймворк Akka основан на акторах, рассмотрим работу актора.
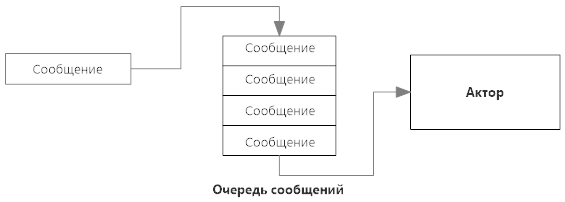
Рисунок. 2.3 Схема работы актора
Каждый актор состоит из очереди сообщений и некоторой логики по их обработке. Сообщения в очереди — это простые неизменяемые структуры данных. Актор последовательно выбирает сообщения из очереди и обрабатывает, результатом обработки может быть изменение внутреннего состояния актора и/или отправка им сообщения другому актору или себе. Актор имеет следующие четыре ключевые операции [[40]]:
Отправка сообщения. Актор может взаимодействовать с только другими акторами путем отправки им сообщений. В отличии от ООП (объектно-ориентированный проектирование), где можно выбрать какие методы и свойства доступны снаружи, акторы не предоставляют доступа ко внутренним методам и состоянию. Акторы не могут разделять доступ к данным с изменяемым состоянием. Сообщения также должны быть неизменяемыми.
Создание актора. Актор может создать другого актора, при этом автоматически регистрируется иерархия: первый актор становится супервизором созданного актора.
Смена состояния. Актор может реализовывать модель конечного автомата с помощью метода смены текущего состояния. В этом случае входящие сообщения обрабатываются по-разному в зависимости от текущего состояния.
Контроль за актором. Актор может наблюдать за событиями жизненного цикла другого актора. Актор-создатель также имеет право на определение стратегии действий при возникновении ошибки в созданном им акторе. Например, может выбрать игнорирование, перезапуск или остановку актора с ошибкой.
Рассмотрим состав модуль мгновенного обмена сообщениями:
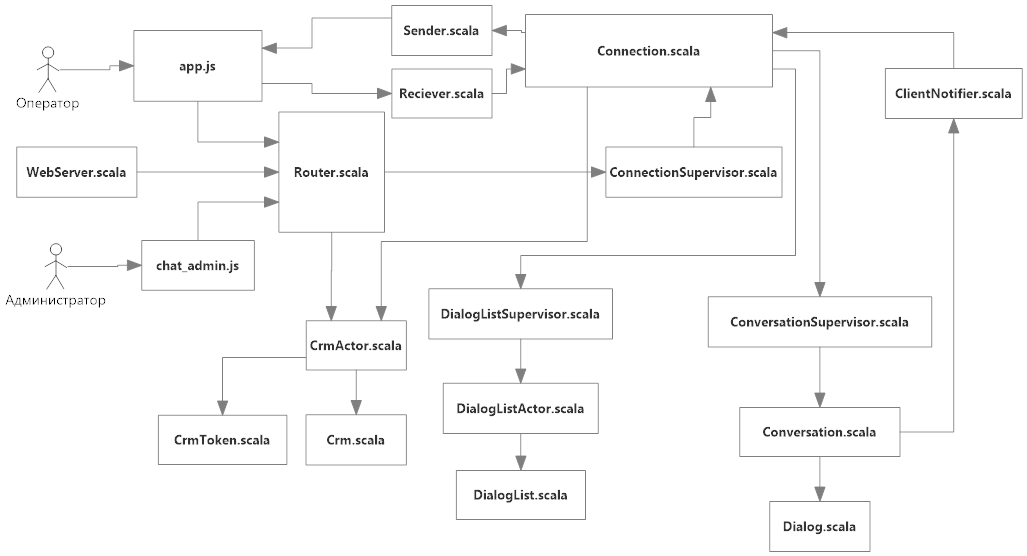
Рисунок 2.4 Диаграмма вызова программных модулей подсистемы мгновенного обмена сообщениями
Система состоит из трех отдельных частей:
Серверная часть. Реализует всю бизнес логику чата и хранит данные о пользователях, группах и переписках. Программный код написан на языке программирования Scala на базе фреймворка Akka.
Клиентское приложение чата для оператора. Одностраничное приложение, работающее в клиентском приложении колл-центра. Предоставляет интерфейс оператору для использования чата. Программный код разработан на языке JavaScript с использованием фреймворка AngularJs.
Клиентское приложение чата для администратора. Одностраничное приложение, работающее в клиентском приложении колл-центра. Предоставляет интерфейс администратору для настройки чата. Программный код разработан на языке JavaScript с использованием фреймворка AngularJs.
Ключевые сущности, которые должны использоваться в модуле мгновенного обмена сообщениями:
Crm.User (Пользователи из CRM системы). Представляет собой справочник локальных для модуля копий учетных записей операторов и супервайзеров колл-центра. Справочник формируется администратором чат-системы через разработанный интерфейс импорта учетных записей из CRM по запросам бизнес-пользователей. Учетные записи содержат следующие данные: идентификатор учетной записи в CRM; логин, имя, фамилия и отчество пользователя; уровень прав в чате; список групп, в которые включен пользователь и флаг активности. На программном уровне реализуется как агент, доступный во всех частях модуля. Сохраняется на диск в виде снимков состояния и списка записей об изменениях.
Crm.Group (Группы пользователей для массовой рассылки сообщений). Справочник групп, составляемый администратором чат-системы по запросам бизнес-пользователей. Группы в чате необходимы для эффективной рассылки сообщения нескольким пользователям одновременно. Запись содержит данные о названии и активности. На программном уровне реализуется как агент, доступный во всех частях модуля. Сохраняется на диск в виде снимков состояния и списка записей об изменениях.
Chat.Dialog (Диалог между пользователями). В данной структуре хранятся оперативные данные модуля. Каждый диалог содержит следующие данные: список пользователей, участвующих в диалоге; список сообщений в диалоге; время последнего сообщения, флаги наличия новых сообщений для каждого пользователя. Сообщения диалога задаются набором данных: текст, время и автор. Каждый диалог реализован как актор с сохраняемыми на диск данными: снимками текущего состояния и списка изменений.
На рисунке представлена взаимосвязь между описанными сущностями.
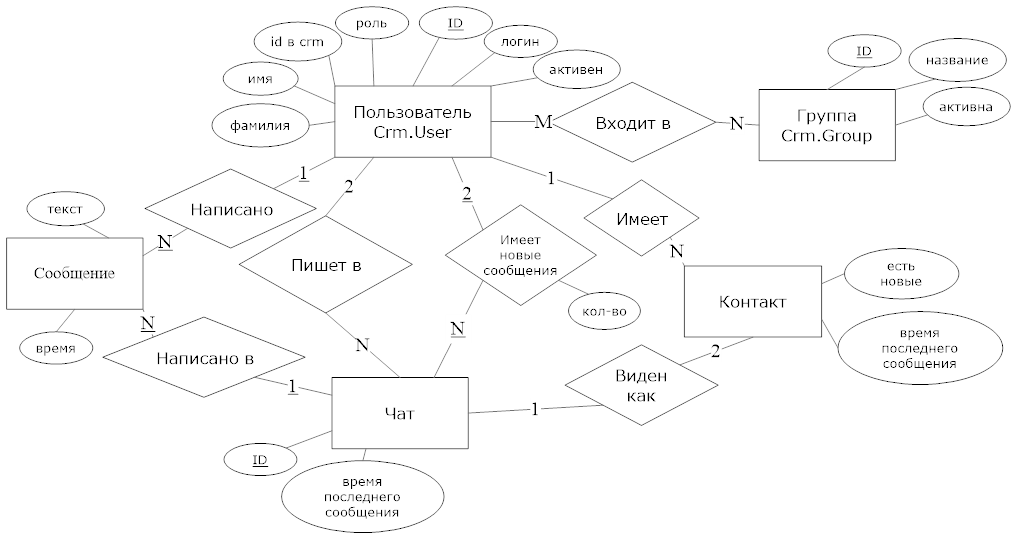
Рисунок 2.5 Диаграмма связей сущностей модуля мгновенной отправки сообщений
Модуль хранить изменения сущностей в виде лога. Различают два подхода к выбору сохраняемых изменений [[41]]:
Event sourcing (ES). Сохраняются результирующие изменения в данных
Command sourcing (CS). Сохраняются запросы на изменение данных
Для структур «Пользователь» и «Группа» был выбран подход Command Sourcing, так как логика обработки входных команд достаточно проста и нет необходимости вводить дополнительные типы для каждого вида изменений. Для остальных сущностей использовался подход Event Sourcing, так как их проблемная область достаточно сложна.
2.3 Пример работы разработанного модуля
Далее рассмотрим реализацию модуля мгновенного обмена сообщениями для колл-центра.
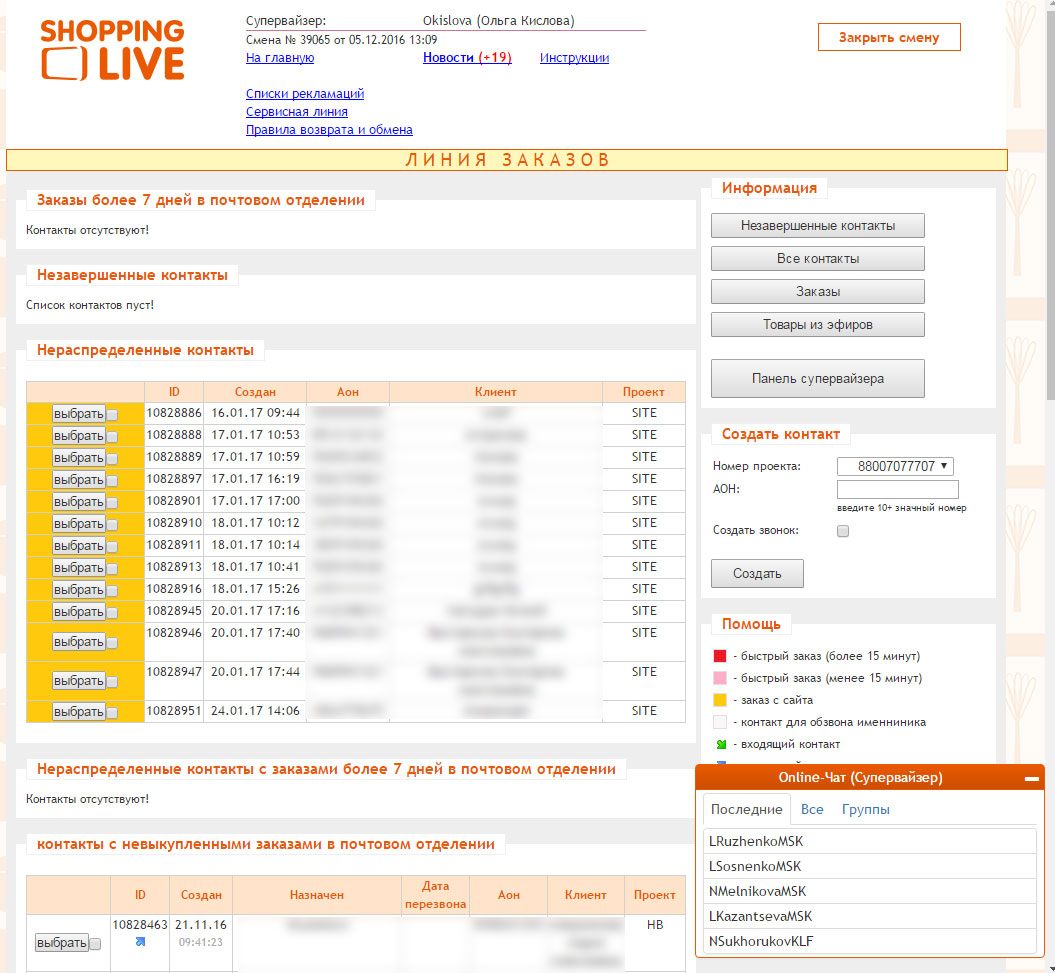
Рисунок 2.6 Окно чата супервайзера в интерфейсе клиентского приложения колл-центра
После авторизации клиентская часть модуля чата выводит вкладку с последними контактами текущего пользователя, отсортированными по дате последнего сообщения. Для начала общения пользователь выбирает диалог кликом мыши. После чего клиентское приложение запрашивает историю диалога.
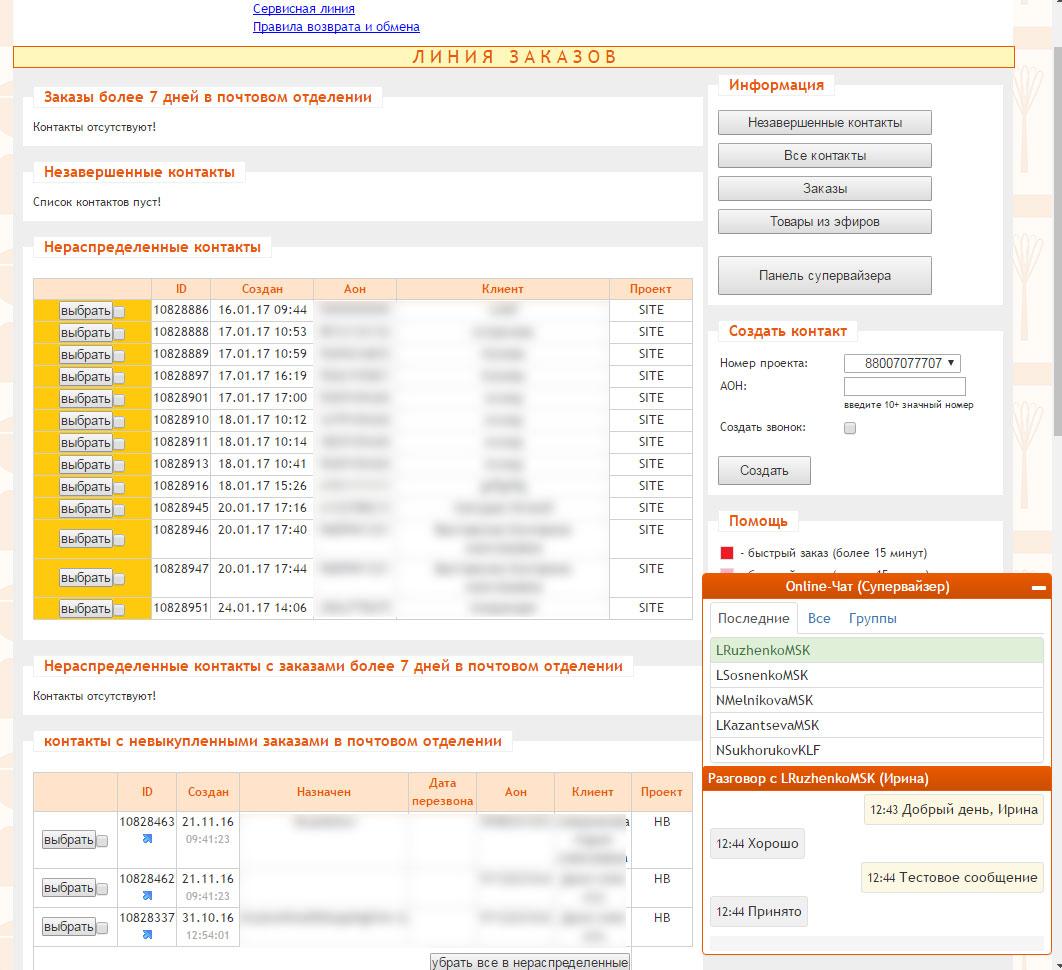
Рисунок 2.7 Окно чата супервайзера в интерфейсе клиентского приложения колл-центра
Сообщения пользователя отображаются справа, сообщения собеседника – слева. Для отправки сообщения пользователь набирает текст и нажимает Enter.
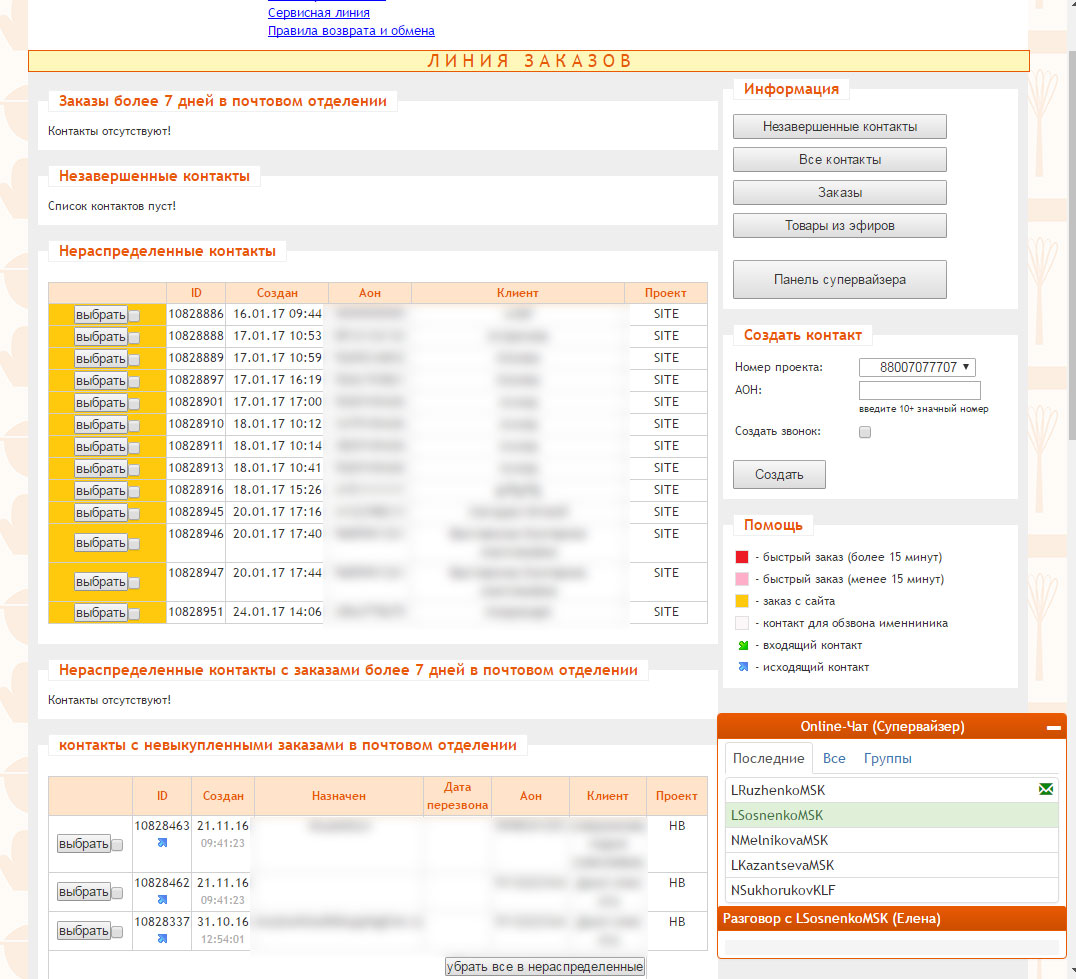
Рисунок 2.8 Окно чата супервайзера в интерфейсе клиентского приложения колл-центра
При поступлении нового сообщения от пользователя, выводится анимированный значок в списке контактов.
Модуль мгновенного обмена сообщений настраивается через панель администрирования. Клиентская часть выполнена на базе JavaScript фреймворка AngularJS, основной особенностью которого является двухстороннее связывание между html-конструкциями (по сути элементами DOM страницы) и переменными в JavaScript коде. Что позволяет программисту работать производительнее, так как нет необходимости работать в программе непосредственно с элементами верстки страницы – все преобразования данных между элементами страницы и переменными кода выполняются автоматически фреймворком.
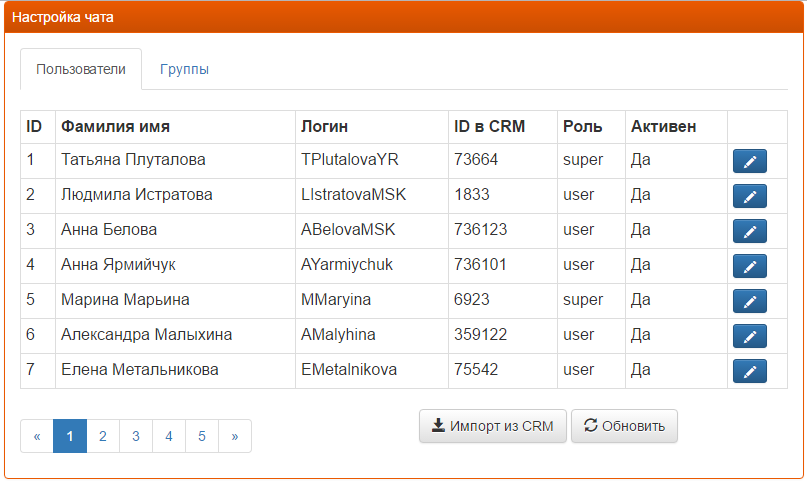
Рисунок 2.9 Окно просмотра списка пользователей чата
На вкладке «Пользователи» выведен список пользователей, зарегистрированных в модуле чата с набором кнопок для их редактирования и импорта. При нажатии на кнопку редактирования строка видоизменяется и выводит элементы управления для изменения полей Роль и Активность, а также кнопки сохранения и отмены.
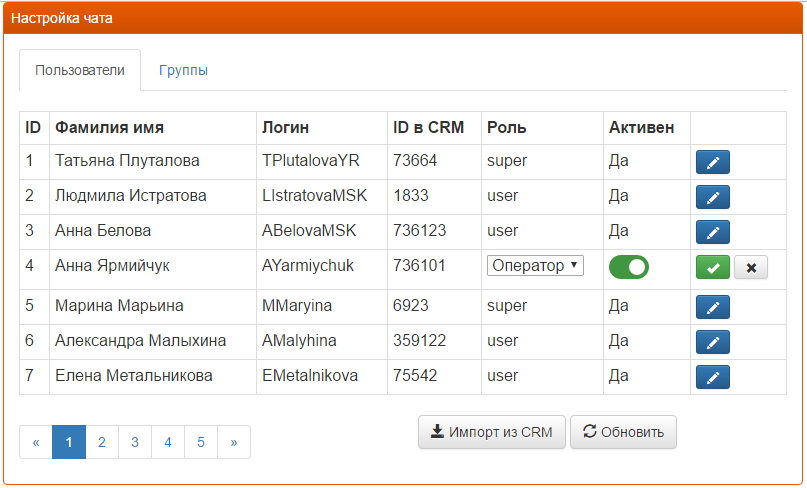
Рисунок 2.10 Режим редактирования пользователя
Вкладка «Группы» отображает список зарегистрированных групп, форму добавления группы и кнопки деактивации.
Рисунок 2.11 Просмотр списка групп
При нажатии на кнопку с количеством пользователей происходит переход на редактирование состава группы.
Рисунок 2.12 Редактирование состава группы
Заключение
В данной работе рассматривались распределенные вычислительные системы. История их развития - от первых вычислительных систем, к векторным суперкомпьютерам и в итоге к полноценным кластерным системам. Изучались основополагающие принципы построения распределенных вычислительных систем, различные аспекты и особенности. В практической части данной работы была решена прикладная задача – автоматизация одного из аспектов процесса приемки заказа в интернет-магазине. Был проведен анализ задачи и обоснован выбор программного фреймворка для разработки распределенного приложений. Был спроектирован и реализован дополнительный модуль для CRM-системы компании. После завершения разработки модуль были протестирован и развернуты на боевом сервере (Production environment), снимки экрана с демонстрацией работы приложены в соответствующей главе. Таким образом поставленные во введении цели были выполнены. В дальнейшем предполагается развитие системы по следующим направлениям: расширение функционала модуля мгновенного обмена сообщениями, добавление новых функций (передача файлов, изображений, звонков, отчетность) и интеграция с бизнес-функциями системы приемки и регистрации заказов (передача и управление звонками и заказами в интерфейсе чата).
Использованная литература
- С.В.Абламейко, Краткий курс истории вычислительной техники и информатики, 2014, Минск, Белорусский Государственный Университет, ISBN 978-985-518-978-8.
- В. Л. Баденко, Высокопроизводительные вычисления, 2010, Санкт-Петербург, Издательство Политехнического университета
- Serge Haddad, Distributed Systems design and algorithms, 2011, Addison-Wesley, ISBN 978-1-84821-250-3
- George Coulouris, DISTRIBUTED SYSTEMS Concepts and Design, 2012, Cambridge University, Addison-Wesley, ISBN 978-0-13-214301-1
- Андрианов С.Н. Параллельные и распределенные вычисления. Часть 1, 2007, САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ, ISBN 979-5-983-40073-2
- Ajay D. Kshemkalyani, Distributed Computing Principles, Algorithms, and Systems, 2008, Cambridge University, ISBN 978-0-511-39341-9
- Э. Таненбаум, Распределенные системы. Принципы и парадигмы, 2003, ISBN 5-272-00053-6
- Lee Atchison, Architecting for Scale, 2016, O’Reilly Media, ISBN 978-1-491-94339-7
- Carl Hewitt, A Universal Modular ACTOR Formalism for Artificial Intelligence, 1973
- Raymond Roestenburg, Akka in Action, 2017, Manning Publications Co., ISBN 9781617291012
- Scott Millett, Patterns, Principles, and Practices of Domain-Driven Design, 2015, John Wiley & Sons, ISBN: 978-1-118-71470-6
- Moore, Gordon E. (1965-04-19). "Cramming more components onto integrated circuits". Electronics. Retrieved 2016-07-01.
- https://statswiki.unece.org/display/bigdata/Big+Data+in+Official+Statistics
- Храпский С.Ф. РАСПРЕДЕЛЕННАЯ ОБРАБОТКА ИНФОРМАЦИИ, 1998, Омск, Омский Государственный Технический Университет
- Artur Ejsmont, Web Scalability for Startup Engineers, 2015, McGraw-Hill Education, ISBN: 978-0-07-184366-9
Приложения
Приложение 1. REST API модуля мгновенного обмена сообщениями
GET /group – Возвращает список всех групп в чате
POST /group – Создает новую группу на основе отправленных данных
GET /group/:id – Возвращает описание группы с идентификатором :id
PUT /group/:id – Изменяет описание группы с идентификатором :id
GET /user – Возвращает список всех пользователей чата
POST /user – Создает нового пользователея в системе на основе отправленных данных
GET /user/:id – Возвращает информацию о пользователе с идентификатором :id
PUT /user/:id – Обновляет информацию о пользователе с идентификатором :id
Модуль управления кэширование сайта предоставляет следующие операции:
GET /cache-control/tasks/queue Возвращает список всех запланированных задач
POST /cache-control/tasks/queue Добавляет в очередь на выполнение новую задачу
GET /cache-control/tasks/running Возвращает список всех выполняющихся задач
GET /cache-control/product/:sku Возвращает текущее содержимое кэша товара с артикулом :sku
GET /cache-control/section/:code Возвращает текущее содержимое кэша категории каталога по коду :code
POST /cache-control/html/clear Сбрасывает html кэш в зависимости от переданных параметров
GET /cache-control/request Возвращает результат запроса к поисковому сервису по переданным параметрам
Приложение 3.
Модуль системы мгновенного обмена сообщениями DialogsListActor. scala
package ru.shoppinglive.chat.chat_api
import akka.actor.{ActorLogging, ActorRef, Props}
import akka.agent.Agent
import akka.event.LoggingReceive
import akka.persistence._
import ru.shoppinglive.chat.chat_api.ClientNotifier.AddressedMsg
import ru.shoppinglive.chat.chat_api.Cmd.{AuthenticatedCmd, GetContacts}
import ru.shoppinglive.chat.chat_api.DialogsListActor.DialogState
import ru.shoppinglive.chat.chat_api.Event.{DialogCreated, MsgConsumed, MsgPosted}
import ru.shoppinglive.chat.chat_api.Result.{ContactChanges, ContactInfo, ContactUpdate, ContactsResult}
import ru.shoppinglive.chat.domain.{Crm, DialogHeader}
import ru.shoppinglive.chat.domain.Dialog.Msg
import scaldi.{Injectable, Injector}
import scala.collection.mutable
/**
* Created by rkhabibullin on 31.12.2016.
*/
class DialogsListActor(val id:Int)(implicit inj:Injector) extends PersistentActor with ActorLogging with Injectable{
private var state = mutable.Map.empty[Int, DialogState]
private val usersDb = inject [Agent[Seq[Crm.User]]] ('usersDb)
private val dialogsAgent = inject [Agent[Map[Int, DialogHeader]]] ('dialogsDb)
private var events=0
private val snapInterval = inject[Int]("chat.snapshot_interval")
implicit private val ec = context.system.dispatcher
override def persistenceId: String = "contacts-list-"+id
override def receiveRecover: Receive = LoggingReceive {
case MsgConsumed(dlgId, time, who) if who==id => state(dlgId) = getDlg(dlgId).copy(newMsg = 0)
case MsgPosted(dlgId, time, from, _) if from==id => state(dlgId) = getDlg(dlgId).copy(last = time)
case MsgPosted(dlgId, time, from, _) if from!=id => val curDlg = getDlg(dlgId)
state(dlgId) = curDlg.copy(last = time, newMsg = curDlg.newMsg+1)
case SnapshotOffer(metadata, snapshot) => state = mutable.Map(snapshot.asInstanceOf[Map[Int, DialogState]].toSeq: _*)
case RecoveryCompleted =>
import scala.concurrent.duration._
if(snapInterval>0)context.system.scheduler.schedule(snapInterval.seconds, snapInterval.seconds, self, "snap")
}
override def receiveCommand: Receive = LoggingReceive {
case AuthenticatedCmd(fromUser, GetContacts(), replyTo) =>
val users = usersDb()
val user = getUser(id)
replyTo ! ContactsResult((if(user.role==Crm.Admin){
users
} else{
users filter (_.role == Crm.Admin)
}) filter(_.id!=user.id) map { other => state.values.find(_.withWhom==other.id).map(dlg =>
ContactInfo(dlg.dlgId, dlg.withWhom, other.login, dlg.newMsg>0, dlg.last, other.name, other.lastName)).getOrElse(
ContactInfo(0, other.id, other.login, false, 0, other.name, other.lastName)
)})
case e@MsgConsumed(dlgId, time, who) => persistAsync(e){_=>}
if(who==id){
val dlg = getDlg(dlgId).copy(newMsg = 0)
state(dlgId) = dlg
val withUser = getUser(dlg.withWhom)
inject [ActorRef] ('notifier) ! AddressedMsg(id, ContactUpdate(ContactChanges(dlgId, dlg.withWhom, false, dlg.last)))
}
case e@MsgPosted(dlgId, time, from, _) => persistAsync(e){_=>}
if(from==id){
val dlg = getDlg(dlgId).copy(last = time)
state(dlgId) = dlg
}else{
val curDlg = getDlg(dlgId)
val dlg = curDlg.copy(last = time, newMsg = curDlg.newMsg+1)
state(dlgId) = dlg
val withUser = getUser(dlg.withWhom)
inject [ActorRef] ('notifier) ! AddressedMsg(id, ContactUpdate(ContactChanges(dlgId, dlg.withWhom, true, dlg.last)))
}
case"reset" => deleteMessages(Long.MaxValue); deleteSnapshots(SnapshotSelectionCriteria.create(Long.MaxValue,Long.MaxValue))
state = mutable.Map.empty[Int, DialogState]
case "snap" => if(events>5)saveSnapshot(state.toMap)
case SaveSnapshotSuccess(metadata) => deleteMessages(metadata.sequenceNr)
deleteSnapshots(SnapshotSelectionCriteria.create(metadata.sequenceNr-1, Long.MaxValue))
}
private def getDlg(dlgId:Int):DialogState = {
state.getOrElseUpdate(dlgId, DialogState(dlgId, dialogsAgent()(dlgId).between.find(_!=id).get, 0, 0))
}
private def getUser(id:Int): Crm.User ={
usersDb()(id-1)
}
}
object DialogsListActor {
def props(id:Int)(implicit inj:Injector) = Props(new DialogsListActor(id))
case class DialogState(dlgId:Int, withWhom:Int, newMsg:Int, last:Long)
}
Приложение 4.
Модуль системы мгновенного обмена сообщениями app.js
/**
* Created by rkhabibullin on 05.12.2016.
*/
var app = angular.module('chatApp', ['mgcrea.ngStrap', 'ngSanitize', 'ajaxToken', 'ngWebSocket', 'ngRoute']);
app.constant('serviceUrl', 'ws://localhost:9100/chat');
app.constant('adminApiUrl', 'http://127.0.0.1:9100/admin/');
app.config(function($routeProvider) {
$routeProvider.when("/login", {
templateUrl: '/tpl/login.html',
controller: 'loginCtrl'
}).when("/chat", {
templateUrl: '/tpl/chat.html',
controller: 'chatCtrl'
}).when("/admin", {
templateUrl: '/tpl/admin.html',
controller: 'adminCtrl'
}).otherwise('/login');
});
app.run( function($rootScope, token, $location) {
$rootScope.$on( "$routeChangeStart", function(event, next, current) {
if (!token() && next.templateUrl != "/tpl/login.html" && next.templateUrl != "/tpl/admin.html") {
$location.path( "/login" );
}
});
});
app.factory('contactsService', function($websocket, serviceUrl, token, $q, $timeout){
var stream;
function request(cmdType, data){
service.processing++;
var rd = angular.extend({}, data, {jsonClass:'Cmd$'+cmdType});
return stream.send(rd).finally(function(){
service.processing--;
});
}
var connDefer = null;
var waitingCreation = null;
var service = {
sentMsg: [],
connected: false,
contacts: null,
groups: null,
dialog: null,
user: null,
connect: function(){
if(stream){
stream.close();
}
stream = $websocket(serviceUrl);
setMsgCb();
service.token(token());
connDefer = $q.defer();
return connDefer.promise;
},
close: function(){
stream.close();
stream = null;
},
token: function(token){
return request('TokenCmd', {token:token})
},
startDlg : function(toWhom){
waitingCreation = toWhom;
return request('FindOrCreateDlgCmd', {withWhom: toWhom});
},
openDlg: function(contact_id){
service.dialog = null;
angular.forEach(service.contacts, function(v){
if(v.dlgId==contact_id)service.dialog = angular.extend({history:[]}, v);
service.read(contact_id);
});
},
closeDlg: function(){
service.dialog = null;
},
read: function(contact_id){
return request('ReadCmd', {dlgId:contact_id})
},
readNew: function(contact_id){
return request('ReadNewCmd', {dlgId:contact_id})
},
sendMsg: function(msg){
if(service.dialog){
service.sentMsg.push({text:msg, dlgId:service.dialog.dlgId});
return request('MsgCmd', {dlgId:service.dialog.dlgId, msg:msg})
}else{
return $q.reject("Invalid state");
}
},
broadcastMsg: function(msg, groupId){
return request('BroadcastCmd', {group:groupId, msg:msg})
},
typing: function(){
if(service.dialog){
return request('TypingCmd', {dlgId:service.dialog.dlgId})
}else{
return $q.reject("Invalid state");
}
},
requestGroups: function(){
return request('GetGroups')
},
requestContacts: function(){
return request('GetContacts')
},
processing:false,
error: null
};
function setMsgCb() {
stream.onOpen(function(){
service.connected = true;
});
stream.onClose(function(){
if(!connDefer.promise.$$state.status){
connDefer.reject(true);
}
service.connected = false;
service.dialog=null;
service.contacts=null;
service.groups=null;
service.sentMsg = [];
});
stream.onMessage(function (msg) {
console.log(msg);
var data = JSON.parse(msg.data);
var type = data.jsonClass.replace(/^Result\$/, '');
switch (type) {
case 'AuthSuccessResult':
service.user = data;
service.connected = true;
connDefer.resolve(true);
service.requestContacts();
if(service.user.role=='admin'){
service.requestGroups();
}
break;
case 'AuthFailedResult':
service.error = data.reason;
service.close();
connDefer.reject(true);
break;
case 'GroupsResult':
service.groups = data.groups;
break;
case 'ContactsResult':
service.contacts = data.contacts;
break;
case 'DialogMsgAccepted':
angular.forEach(service.sentMsg, function(v,k){
if(v.dlgId==data.dlgId && javaHashCode(v.text)==data.hash){
delete service.sentMsg[k];
angular.forEach(service.contacts, function(v,k){
if(v.dlgId==v.dlgId)service.contacts[k].last = data.time;
});
if(service.dialog.dlgId==v.dlgId){
service.dialog.history.push({text:v.text, time:data.time, from:service.user.id});
}
}
});
break;
case 'DialogIdResult':
var toUser = data.withWhom;
var dlgId = data.dlgId;
var found = -1;
angular.forEach(service.contacts, function (v, k) {
if (!v.dlgId && v.userId==toUser){
service.contacts[k].dlgId = dlgId;
found = k
}
});
if(found>=0) {
if (waitingCreation && waitingCreation == toUser) {
service.dialog = angular.extend({history:[]}, service.contacts[found]);
waitingCreation = null;
}
}
break;
case 'DialogNewMsg':
if(service.dialog && data.dlgId==service.dialog.dlgId) {
service.dialog.history = service.dialog.history.concat(data.msg);
service.dialog.typing =false;
}
break;
case 'DialogMsgList':
if(service.dialog && data.dlgId==service.dialog.dlgId) {
service.dialog.history = data.msg;
service.dialog.typing =false;
}
break;
case 'ContactUpdate':
var k = contactByDlgId(data.contact.dlgId);
if(k>=0){
angular.extend(service.contacts[k], data.contact);
if(service.dialog && service.dialog.dlgId==data.contact.dlgId && data.contact.hasNew){
service.readNew(data.contact.dlgId);
}
}
break;
case 'TypingNotification':
if(service.dialog && data.dlgId==service.dialog.dlgId){
service.dialog.typing=true;
$timeout(function(){
if(service.dialog && data.dlgId==service.dialog.dlgId){
service.dialog.typing=false;
}
}, 5000);
}
break;
default: console.log('unknown msg ', type)
}
});
}
function javaHashCode(str){
var hash = 0;
if (str.length == 0) return hash;
for (i = 0; i < str.length; i++) {
char = str.charCodeAt(i);
hash = ((hash<<5)-hash)+char;
hash = hash & hash; // Convert to 32bit integer
}
return hash;
}
function contactByDlgId(id){
var found = -1;
angular.forEach(service.contacts, function (v, k) {
if(v.dlgId==id)found=k;
});
return found;
}
return service;
});
app.controller('chatCtrl', function($scope, $filter, contactsService, $timeout, $interval){
function updateContacts(){
if($scope.cs.contacts){
$scope.tabs.last = $filter('orderBy')($scope.cs.contacts, ['-hasNew', '-last']).slice(0, 5);
$scope.tabs.all = $filter('orderBy')($scope.cs.contacts, 'login');
$scope.tabs.new = $filter('filter')($scope.cs.contacts, {hasNew:true}, true);
}else{
$scope.tabs = {
last:[], all:[], new:[]
}
}
}
contactsService.connect();
$scope.cs = contactsService;
$scope.chat ={
open: false,
contactTab: 'last',
broadcast:null
};
$scope.$watch('cs.dialog.history.length', function(len){
if(len>0){ $timeout(scrollDialog, 50);}
});
$scope.$watch('cs.dialog.typing', function(flag){
if(flag>0){ $timeout(scrollDialog, 50);}
});
function scrollDialog(){
var e = document.getElementById('dialog_messages'); e.scrollTop = e.scrollHeight;
}
$scope.$watchCollection('cs.contacts', updateContacts);
var reconPromise=null;
$scope.$watch('cs.connected', function(connected){
if(!connected){
if(reconPromise)reconPromise.cancel();
reconPromise = $timeout(function(){
if(!$scope.cs.connected){
$scope.cs.connect()
}
},10000);
}
});
$scope.$on("$destroy", function() {
if(reconPromise){
reconPromise.cancel(); reconPromise=null
}
});
$scope.toggleWnd = function(){
$scope.chat.open = !$scope.chat.open;
if(!$scope.chat.open){
$scope.cs.closeDlg();
}
};
$scope.tabs = {
new: [],
last: [],
all: [],
group: $scope.cs.groups
};
if($scope.cs.contacts && $scope.cs.contacts.length)updateContacts();
$scope.openDialog = function(dlg){
$scope.chat.open = true;
$scope.chat.broadcast = null;
if(dlg.dlgId){
$scope.cs.openDlg(dlg.dlgId);
}else{
$scope.cs.startDlg(dlg.userId);
}
};
$scope.openGroup = function (group) {
$scope.cs.close();
$scope.chat.broadcast = group;
};
$scope.sendMsg = function(){
$scope.cs.sendMsg($scope.chat.dialogText);
$scope.chat.dialogText = '';
};
$scope.broadcast = function(){
$scope.cs.broadcastMsg($scope.chat.broadcast.id, $scope.chat.broadcastText);
$scope.chat.broadcastText ='';
};
var lastTyping = 0;
$scope.typing = function () {
if(lastTyping+5000<Date.now()){
lastTyping=Date.now();
$scope.cs.typing()
}
};
});
app.controller('loginCtrl', function($scope, $location, $rootScope, chatAdminService){
chatAdminService.getUsers().then(function(list){
angular.forEach(list, function(v){
$scope.logins.push({id:v.crmId, login:v.login});
})
});
$scope.logins = [];
$scope.userId = null;
$scope.login = function(){
if($scope.userId) {
$scope.$emit('set-token', $scope.userId);
$location.path("/chat");
}
}
});
app.filter('shortDate', function($filter){
var filterDate = $filter('date');
function isToday(date){
var today = new Date();
return today.getDate()==date.getDate() && today.getMonth()==date.getMonth() && today.getYear()==date.getYear();
}
return function(date){
date = new Date(date);
return isToday(date)?filterDate(date, 'HH:mm'):filterDate(date, 'dd.MM HH:mm');
}
});
-
С.В.Абламейко, Краткий курс истории вычислительной техники и информатики,2014, стр. 37-38 ↑
-
С.В.Абламейко, Краткий курс истории вычислительной техники и информатики,2014, стр. 47 ↑
-
С.В.Абламейко, Краткий курс истории вычислительной техники и информатики,2014, стр. 48 ↑
-
Serge Haddad, Distributed Systems design and algorithms, стр. 13 ↑
-
В. Л. Баденко, Высокопроизводительные вычисления, 2010, стр. 12 ↑
-
В. Л. Баденко, Высокопроизводительные вычисления, 2010, стр. 23 ↑
-
George Coulouris, Distributed systems Concepts and Design, 2012, стр. 39 ↑
-
В. Л. Баденко, Высокопроизводительные вычисления, 2010, стр. 75 ↑
-
Serge Haddad, Distributed Systems design and algorithms, стр. 15 ↑
-
В. Л. Баденко, Высокопроизводительные вычисления, 2010, стр. 47 ↑
-
Ajay D. Kshemkalyani, Distributed Computing Principles, Algorithms, and Systems, стр.21 ↑
-
Э. Таненбаум, Распределенные системы. Принципы и парадигмы, стр. 23 ↑
-
Андрианов С.Н. Параллельные и распределенные вычисления, стр. 5 ↑
-
George Coulouris, DISTRIBUTED SYSTEMS Concepts and Design, стр. 2 ↑
-
Ajay D. Kshemkalyani, Distributed Computing Principles, Algorithms, and Systems, стр. 2 ↑
-
Serge Haddad, Distributed Systems design and algorithms, стр.22 ↑
-
Э. Таненбаум, Распределенные системы. Принципы и парадигмы, стр. 25 ↑
-
Ajay D. Kshemkalyani, Distributed Computing Principles, Algorithms, and Systems, стр. 4 ↑
-
Lee Atchison, Architecting for Scale, стр. 4 ↑
-
Lee Atchison, Architecting for Scale, стр. 6 ↑
-
Lee Atchison, Architecting for Scale, стр.16 ↑
-
Ajay D. Kshemkalyani, Distributed Computing Principles, Algorithms, and Systems, стр. 5 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 3 ↑
-
Serge Haddad, Distributed Systems design and algorithms, стр.27-28 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 84 ↑
-
Андрианов С.Н. Параллельные и распределенные вычисления, стр. 11 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 85 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 100 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 14 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 102 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 113 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 140 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 143 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 156-164 ↑
-
Artur Ejsmont, Web Scalability for Startup Engineers, стр. 175 ↑
-
Carl Hewitt, A Universal Modular ACTOR Formalism for Artificial Intelligence ↑
-
Raymond Roestenburg, Akka in Action, стр 1 ↑
-
Raymond Roestenburg, Akka in Action, стр 4-5 ↑
-
Raymond Roestenburg, Akka in Action, стр 7-8 ↑
-
Raymond Roestenburg, Akka in Action, стр. 20 ↑
-
Scott Millett, Patterns, Principles, and Practices of Domain-Driven Design, стр. 324 ↑

- Теоретические основы стадий жизненного цикла организации
- Управление конфликтами в органах государственной региональной власти (Конфликт в государственной сфере: понятие, содержание, проблемы)
- Роль межбюджетных трансфертов в формировании бюджетов субъектов Российской Федерации
- Управление миграционными процессами (Управление миграционными процессами)
- Особенности управления организацией в современных условиях и пути его совершенствования (Теоретические основы особенностей управления организациями в современных условиях)
- Особенности управления организациями в современных условиях и пути его совершенствования (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ СИСТЕМЫ УПРАВЛЕНИЯ ОРГАНИЗАЦИИ)
- Понятие и признаки государства (Психологическая теория происхождения государства)
- Теории происхождения права (Основные пути возникновения права)
- Теория и практика разделения властей (Возникновение и основные положения классической теории разделения властей)
- Роль мотивации в поведении организации (Мотивация трудовой деятельности)
- Роль мотивации в поведении организации (ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ИССЛЕДОВАНИЯ МОТИВАЦИИ ПЕРСОНАЛА ОРГАНИЗАЦИИ)
- Гарантии прав и свобод человека и гражданина (ПРИРОДА И СУЩНОСТЬ ПРАВ И СВОБОД ЧЕЛОВЕКА)