
Способы представления данных в информационных системах
Содержание:

ВВЕДЕНИЕ
Актуальность темы заключается в том, что компьютерные технологии изначально возникли как средство автоматизации расчетов. Следующим типом обрабатываемой информации был текст. Сначала тексты просто объясняли сложные столбцы чисел, но затем машины стали преобразовывать текстовую информацию все более и более значительно. Дизайн текстов быстро вызвал желание людей дополнить их графиками и рисунками. Были предприняты попытки частично решить эти проблемы в рамках символического подхода: были введены специальные символы для рисования таблиц и диаграмм. Но практические потребности людей в графике сделали его появление среди типов компьютерной информации неизбежным. Числа, тексты и графика образовывали некоторое относительно замкнутое множество, которого было достаточно для решения многих задач на компьютере. Постоянное увеличение скорости компьютерных технологий создало широкие технические возможности для обработки аудиоинформации, а также для быстро меняющихся изображений.
Объектом исследования, представленным в теоретической части, являются данные в информационных системах.
Целью работы является рассмотрение форматов данных их представления в информационных системах.
Для достижения цели необходимо решить следующие задачи:
• Изучить уровни представления и их внутреннюю структуру;
• Рассмотреть классификацию структур данных;
• Изучить способы представления данных;
• Рассмотреть элементарные данные.
Задача, поставленная во второй части курсовой работы, состоит в том, чтобы рассмотреть способы представления данных в информационных системах.
1. ПРЕДСТАВЛЕНИЕ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
Области применения информационных систем разнообразны. В этих условиях трудно найти две одинаковые системы. Они отличаются разнообразием основных свойств и особенностей, например: характер обрабатываемой информации, целевые функции, технический уровень системы и т. д. Перечисленные функции влияют на форму представления информации как в системе, так и в системе. для пользователя характер процессов обработки информации и взаимодействия информационных систем со средой, состав оборудования и программного обеспечения.
Классификация информационных систем по основным признакам была проведена ранее в разделе. Очевидно, что предметом этого рассмотрения следует считать автоматизированные и автоматические информационные системы, в которых компьютеры используются для хранения, обработки и извлечения информации. Конечно, сегодня эти системы отличаются широкими функциональными возможностями, способностью хранить и обрабатывать очень большие объемы информации. Характерной особенностью этих систем является широкое использование компьютеров в самых разнообразных узлах и сборках, в частности, в системах сбора, подготовки, передачи и выдачи информации.
Любая информационная система работает в среде внешней среды, которая для нее является источником ввода и потребителем выходной информации. В рамках такой системы, начиная от входа в систему и заканчивая выходом из нее, поток информации проходит несколько этапов обработки. Как известно, основные этапы обработки информации включают сбор, регистрацию и первичную обработку, передачу по каналу связи от источника к компьютеру, создание и обслуживание информационных массивов, обработку и генерацию выходных форм, передачу по каналам связи из компьютеры для потребителей, преобразование в удобную форму для восприятия пользователем.
Информация, поступающая в компьютерную информационную систему, отображает состояние объектов или отдельных компонентов окружающего мира, а в алгоритмах приведены некоторые правила ее обработки, соответствующие правилам ее обработки в среде.
Информация, поступающая в компьютеры, располагается в памяти, образуя информационные массивы, из которых состоит информационный фонд. Информационные массивы имеют определенную структурную организацию, которая связана со структурным составом объекта реального мира, связями между его отдельными элементами и их характеристиками.
Над элементами массива и фонда в целом выполняются различные операции обработки, основными из которых являются: логические и арифметические операции, операции сортировки и поиска, ведение и исправление информации. В результате этих операций обеспечивается актуальность информации, то есть существует необходимость соответствия между внешним миром и фактически его компьютерной моделью. Кроме того, выходная информация генерируется в соответствии с заданием на обработку.
1.1 Уровни представления данных в информационных системах
Как уже было установлено, автоматизированные информационные системы хранят и обрабатывают информацию об объектах реального мира. Большие объекты из-за естественной сложности могут быть разделены, используя принцип декомпозиции, на отдельные единицы и узлы.
Некоторый набор информации, описывающей конкретный объект или его часть, называется логической записью или просто записью. Набор записей, описывающих набор объектов определенного класса, называется информационным массивом.
В реальном мире между объектами или их отдельными единицами существуют определенные отношения и взаимосвязи, которые имеют разную степень сложности. Во время разработки систем обработки и хранения информации эти отношения идентифицируются и отображаются путем структурирования записей и информационных массивов. Организация информационного массива, который обеспечивает определенные связи и связи между данными, называется структурой данных. Чтобы обработка данных в компьютере не теряла своего содержимого, значение отношений, существующих между объектами в реальном мире, не нарушается, структуры должны поддерживаться, т.е. любые манипуляции, выполняемые с данными во время их обработки, не должны уничтожить структуру данных. Структура отображает свойства описываемого объекта, поэтому разрушение структуры приведет к потере ее свойств в результате неадекватного описания объекта..
Структура данных как совокупность элементов и связей между ними




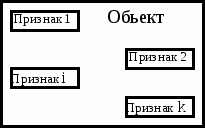

Рис. 1.1. Взаимосвязь между объектом и структурой данных
Существует три уровня представления данных: логический уровень, уровень хранения и физический уровень.
На логическом уровне они работают с логическими структурами данных, которые отражают реальные отношения, существующие между объектами, и их характеристиками, то есть указывают, как данные представляются пользователю системы. При разработке логических структур данных также учитываются информационные потребности пользователей системы и характер задач, для которых они предназначены. Единицей информации на этом уровне является логическая запись, объект, описываемый соответствующей логической записью, характеризуется определенными признаками - свойствами, которые выражаются как атрибуты записи. На логическом уровне разработчик системы устанавливает список функций, который полностью характеризует описанный класс объектов. Набор признаков и их взаимосвязь определяют внутреннюю структуру логической записи.
Логическая структура данных должна исчерпывающе характеризовать объекты, в отношении которых обрабатывается АИС; адекватно отражать реальные отношения между объектами и их характеристиками; обеспечить удовлетворение информационных потребностей пользователей системы и задач приложения. Какие из свойств объекта должны отражать атрибуты записи, разработчик системы решает на основе известных принципов достаточности.
На логическом уровне представления данных техническое и математическое программное обеспечение системы (тип компьютера, тип памяти, язык программирования, операционная система) не учитывается.
На уровне хранения они работают со структурами хранения - представлениями логической структуры данных в памяти компьютера. Структура хранения должна полностью отображать логическую структуру данных и поддерживать ее в процессе функционирования АИС (автоматизированная информационная система). Единица информации на этом уровне также является логической записью. АИС должна преобразовывать логический уровень в уровень хранения, избегая искажений.
Операционная память машины и внешняя память имеют разные возможности, поэтому средства и методы организации данных в ОЗУ (RAM) и на OVC (внешние устройства хранения) различны. При разработке или выборе структуры хранения принимается во внимание тип хранилища, в котором будут храниться данные, устанавливается тип и формат данных и определяется метод поддержания логической структуры.
Существуют различные способы представления данных в ОЗУ и в OVC, и одна и та же логическая структура данных может быть реализована в памяти компьютера различными структурами хранения. Каждая структура хранения обеспечивает определенный способ доступа к данным и определенные возможности для манипулирования данными. Он характеризуется количеством памяти, необходимой для хранения данных. Эффективность обработки данных напрямую зависит от выбора структуры хранения. Правильно подобранная структура хранилища обеспечивает быстрый поиск необходимых данных, возможность добавления новых и удаления устаревших записей без разрушения логической структуры, а также возможность корректировки записей, минимальное потребление памяти компьютера.
Структура хранилища поддерживается программным обеспечением. Для реализации ряда структур хранения требуются определенные языки программирования, поэтому при разработке или выборе структуры хранения следует учитывать возможности языка программирования, на котором будут написаны программы данных.
На физическом уровне представления данных работают с физическими структурами данных. На этом уровне решается задача реализации структуры хранения непосредственно в определенной памяти конкретного компьютера. Единицей информации на этом уровне является физическая запись, представляющая часть носителя, на которой размещена одна или несколько логических записей. При разработке структур памяти анализируются параметры конкретных технических средств: тип и объем памяти, метод адресации, метод и время доступа к данным. На этом уровне решаются задачи организации обмена данными между основной и внешней памятью компьютера.
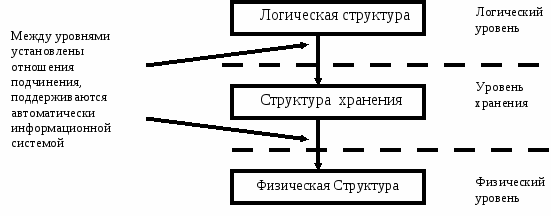
Рис. 1.2. Уровни представления данных
При разработке структур данных всех уровней должен быть обеспечен принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в технической поддержке системы не должны влиять на логические структуры и прикладные программы, то есть не должны вызывать изменения в них. Независимость логических данных означает, что изменения в структурах хранения не должны вызывать изменений в логических структурах данных и прикладных программах. Кроме того, изменения, внесенные в логические структуры данных из-за появления новых пользователей и новых запросов, не должны влиять на прикладные программы других пользователей системы.
Соблюдение принципа независимости данных позволяет использовать определенные типы данных: виртуальные и прозрачные данные.
Виртуальные данные существуют только на логическом уровне. Кажется, что эти данные действительно существуют у программиста, и он использует их в своих программах. Каждый раз, когда к данным обращаются, операционная система определенным образом генерирует их на основе других данных, физически существующих в системе. Объявление некоторых данных виртуальными экономит память машины.
Кажется, что прозрачные данные не существуют на логическом уровне. Это позволяет скрыть от программиста или пользователя многие сложные механизмы, используемые при преобразовании логических структур данных в физические, и упростить прикладные программы..
1.2. Внутренняя структура данных
Логические обозначения составляют основу информационных массивов в информационных системах. Логическая запись состоит из отдельных элементов, связанных определенными отношениями, и может иметь многоуровневую структуру. Формирование элементов более высокого уровня из нижних элементов осуществляется в соответствии с определенными правилами.
Элементами первого, нижнего уровня являются элементарные данные: числа, символы, логические данные, знаки. Элементарные данные считываются и обрабатываются программой в целом, доступ к ее частям невозможен. Обычно эти данные не являются непосредственным объектом поиска информации, но в некоторых случаях они должны быть доступны. Так, например, в процессе поиска может возникнуть необходимость сравнить отдельные символы.
Элементарные данные каждого типа имеют определенную форму представления в памяти; для их хранения выделяется строго определенный объем памяти. Знание форматов хранения элементарных данных позволяет рассчитать объем памяти, необходимый для размещения данных и программ.
Элементом второго уровня является поле записи. Это последовательность элементарных данных, которая имеет определенное значение, но не имеет значимой полноты. Данные, образующие отдельное поле записи, описывают соответствующий атрибут - свойство объекта.
Каждая особенность объекта имеет имя и значение (рис. 1.1.). Например, для учеников, чьи записи хранятся в AIS, в качестве знаков можно использовать идентификационный номер ученика, фамилию и знак средней оценки. Каждый конкретный ученик характеризуется определенными значениями этих знаков, например, названием знака. Средний балл, значение 4,7. Отдельные студенты различаются в значениях знаков одного и того же имени.
Очевидно, что количество признаков, характеризующих объект, определяет количество полей в записи. Каждое поле содержит значение соответствующего атрибута. Поля записи названы, и имя поля может совпадать с именем атрибута.
Знак, используемый для идентификации записи во время обработки или поиска, называется ключом или ключом записи. Поле ввода, содержащее ключ, называется полем ключа. Если каждое из возможных значений ключа идентифицирует одну запись, такой ключ называется уникальным. Таким образом, идентификационный номер студента является уникальным ключом для каждой записи в массиве, хранящем информацию о студентах в данном университете.
Запись может содержать дополнительные поля для хранения служебной информации: теги, ссылки, различные указатели. Поле записи может быть объектом поиска информации в различных приложениях, а также в тех случаях, когда это поле является ключевым. Однако, как уже отмечалось, поле записи не имеет смысловой полноты. Например, поле «СРЕДНИЙ ШАР» может быть объектом поиска, но информационное значение этого поля будет иметь значение только тогда, когда известны фамилия, имя и отчество учащегося.
Понятие поля записи не следует отождествлять с понятием поля машинной памяти. Эти понятия относятся к различным уровням представления данных. Для хранения записи поле может быть использовано как блок памяти компьютера фиксированной и переменной длины.
Поля записи объединяются в группу данных (агрегация данных, сгруппированные данные). Группа данных - элемент третьего уровня внутренней структуры записи - это именованная коллекция элементов данных, которая рассматривается как единое целое. Например, группа данных, имеющая наименование АДРЕС, состоит из элементов данных ГОРОД, УЛИЦА, НОМЕР ДОМА, НОМЕР КВАРТИРЫ. В качестве своего элемента группа может иметь другую группу данных. Группа данных имеет определенный смысл и может быть объектом поиска, но не имеет смысловой завершенности. Так, например, адрес полезно знать лишь в том случае, если известно, чей он.
Логическая запись - это именованная коллекция полей или групп данных. Запись представляет собой отдельную логическую единицу и имеет значительную полноту.
Каждая запись описывает отдельный объект или класс объектов. Логическая запись является непосредственным предметом поиска информации, основной единицей обработки информации.
Список полей, последовательность их расположения и взаимосвязь между ними составляют внутреннюю структуру записи, которая в конечном итоге определяет тип записи. Поля записи могут быть расположены один за другим, в этом случае запись называется неструктурированной. Запись может быть структурированной, со сложными нелинейными связями между полями. Структурирование записей является одним из основных понятий баз данных.
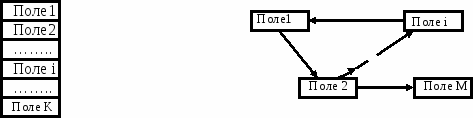
Рис. 1.3. Структурированные и неструктурированные записи
Отдельные логические записи, которые описывают определенный класс объектов, группируются в информационный массив. Массивы, хранящиеся в ВЗУ, называются файлами. Файл имеет имя и рассматривается как единое целое. Например, совокупность записей всех студентов учебной группы можно рассматривать как отдельный файл.
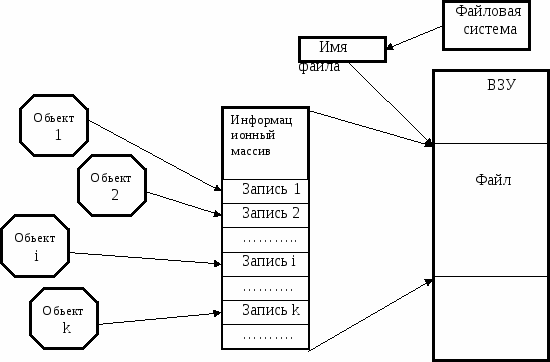
Рис. 1.4. Логические записи, информационные массивы и файлы
1.3 Классификация структур данных
Ранее говорилось, что в ходе работы АИС записи и массивы претерпевают изменения. В то же время новые записи добавляются в массивы, и записи становятся ненужными. В связи с этим различаются операции над массивами и операции над содержимым отдельных записей, которые составляют массивы.
Процесс поддержания массива информации в его текущем состоянии, который состоит в добавлении (включении) и удалении (исключении) записей, называется обслуживанием.
Отдельные характеристики объектов могут со временем меняться, поэтому в записи должны быть внесены соответствующие изменения. Процесс внесения изменений в записи называется корректировкой или модификацией.
Конечной целью любой операции, выполняемой в АИС, является отдельная запись. Чтобы добавить, удалить или настроить обработку информации, содержащейся в конкретной записи, сначала необходимо найти нужную запись или ее местоположение в массиве. Таким образом, поисковые операции являются традиционными для систем обработки и хранения информации и, можно считать, наиболее часто выполняемыми операциями в AИС. Поиск записей должен выполняться как можно быстрее, поскольку время поиска существенно определяет общее время обработки информации. Очевидно, что эти свойства AИС зависят от того, как организован уровень хранилища и какие правила, алгоритмы применяются для поиска записей в массивах и файлах.
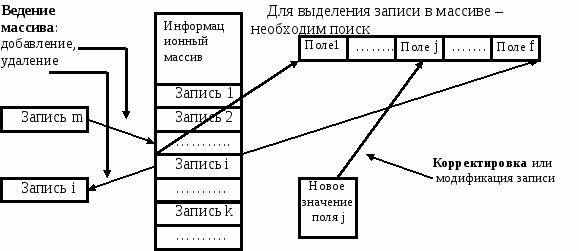
Рис 1.5. Операции над записями в массивах
Чтобы обеспечить «жизнеспособность» информационного массива структуры, в которую организованы данные, они должны обеспечить возможность поддержки массива и настройки отдельных записей, быстрого поиска записей и минимального потребления памяти для массива. Перечисленные требования противоречивы, поэтому ужесточение требований, ведущих к улучшению некоторых характеристик АИС, может сопровождаться ухудшением других. При выборе структуры данных они часто останавливаются на компромиссном решении.
Структуры данных делятся на линейные и нелинейные структуры. В нелинейных структурах, в отличие от линейных, связь между элементами структуры (записями) определяется отношениями подчиненности или некоторыми логическими условиями. Линейные структуры данных включают в себя массив, стек, очередь, таблицу. Тенденции, графики, многосвязные списки и структуры списков принадлежат нелинейным структурам.
Ряд структур данных после создания не позволяет включать или исключать записи, а только позволяет их корректировать. Это структуры фиксированного размера. Структуры переменного размера позволяют включать и исключать записи, что позволяет динамически изменять массив данных. В зависимости от того, как структуры представлены в памяти компьютера (последовательная или подключенная), структурам переменного размера предоставляется возможность увеличиваться и уменьшаться либо в предварительно зарезервированном блоке памяти, либо во всем свободном адресном пространстве. В первом случае необходимо заранее знать количество элементов структуры и выделить блок памяти для максимального размера информационного массива. Если количество элементов структуры оказалось больше ожидаемого, то дополнительные элементы не смогут быть размещены в памяти. Если элементов меньше, память останется неиспользованной. Со связанным представлением структуры переменного размера могут свободно расти и сжиматься. Количество элементов конструкции может быть неизвестно заранее.
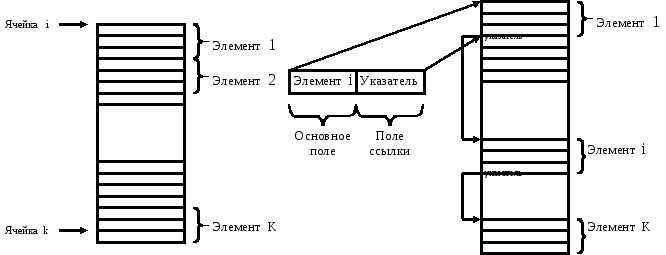
Рис. 1.6. Последовательное и связное представление структур данных
Разные структуры данных обеспечивают разный доступ к своим элементам: в одних структурах доступ возможен к любому элементу, в других - к строго определенному. Ограничение доступа сопровождается увеличением времени поиска необходимых записей.
Структуры данных могут быть однородными и разнородными. В однородных структурах все элементы представлены записями одного типа. В гетерогенных структурах элементы одной структуры могут быть записями разных типов.
1.4 Последовательное и связанное представления данных в памяти
На уровне хранения в памяти компьютера данные могут иметь последовательное или связанное представление (см. Рис. 1.7). Соответственно, структуры хранения различаются с использованием согласованного представления данных и связанного представления данных.
В последовательном представлении данные в памяти машины расположены в соседних последовательных ячейках. В этом случае физический порядок записей полностью согласуется с логическим порядком, определяемым логической структурой, то есть логическая структура поддерживается физическим порядком данных. Набор записей, помещаемых в последовательные ячейки памяти, называется последовательным списком.
Для хранения информационного массива в виде последовательного списка в памяти выделяется блок свободных ячеек для максимального размера массива. Записи, имеющие следующий логический порядок: Зап. В, Зап. А, Зап. F, Зап. С, ..., Зап.N, — разместятся в памяти машины так, как это показано на рис. 1.7,а.. Вновь появившиеся записи размещаются в конце блока на свободном участке памяти. Если количество новых записей окажется больше, чем число свободных ячеек в зарезервированном блоке, то эти записи не удастся разместить в памяти. Если же записей окажется меньше, чем предполагалось, то память останется неиспользованной.
В процессе ведения информационного массива записи добавляются и удаляются. Вновь пришедшие записи добавляются в конец списка. Так, запись (N + 1)-я будет размещена в ячейке с адресом 100 + (N + 1). При удалении записей в памяти остаются свободные ячейки. На рис. 1.7,б добавлена запись (N + 1)-я и удалены две записи: Зап. А и Зап. F, Ячейки 102 и 103 оказались свободными. Список, содержащий свободные ячейки памяти, будет свободным. Со временем значительное количество клеток может стать свободным. Чтобы эти разделы памяти не были пустыми, время от времени весь массив данных перезаписывается, а все записи перемещаются, как показано на рис. 1.7, б. Перезапись массива требует дополнительного компьютерного времени. В процессе обновления массива обновляемые записи считываются из памяти и в них вносятся необходимые изменения. Исправленные записи записываются обратно в конец списка в свободных ячейках.
Последовательное представление данных обычно используется для реализации линейных структур данных в случаях, когда можно предсказать максимальный размер массива.
Приложения AИС часто имеют дело с данными, которые постоянно обновляются, исправляются, и представление данных в виде последовательного списка приводит к неэффективному использованию памяти, потере компьютерного времени для перезаписи массива. Для ряда задач последовательное представление данных обычно не применимо. В таких случаях связанное представление используется для организации структуры данных.
|
А) |
|
Б) |
|
В) |
|
||||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|||||
|
|
|
|
|||||||
|
|
|||||||||
Рис. 1.7. Последовательное представление данных в памяти ЭВМ. Блок ячеек памяти:
А) после создания массива;
Б) после удаления и добавления записей;
В) после перезаписи массива.
В связанном представлении дополнительное поле предоставляется в каждой записи, в которой находится указатель (ссылка). Физический порядок записей в этом случае может не соответствовать логическому порядку. В памяти компьютера записи расположены в любых свободных ячейках и связаны друг с другом указателями, указывающими местоположение записи, логически следующие за данной записью. Указатель часто интерпретируется как адрес ячейки памяти, в которой хранится следующая запись.
Структуры хранения, основанные на связанном представлении данных, называются связанными списками. Если каждая запись содержит только один указатель, то список просто связан, с большим количеством указателей, список является многократным.
Пусть структура данных отображает следующую логическую последовательность записей: Зап. А, Зап. В, Зап. С, Зап. F. Записи размещены в ячейках памяти с адресами 01, 03, 05, 10. В поле указателя каждой записи размещается адрес связи (АС), определяющий адрес ячейки с логически следующей записью. Структура хранения массива представлена на рис. 1.8,a.
На этом рисунке стрелками показан порядок чтения записей.
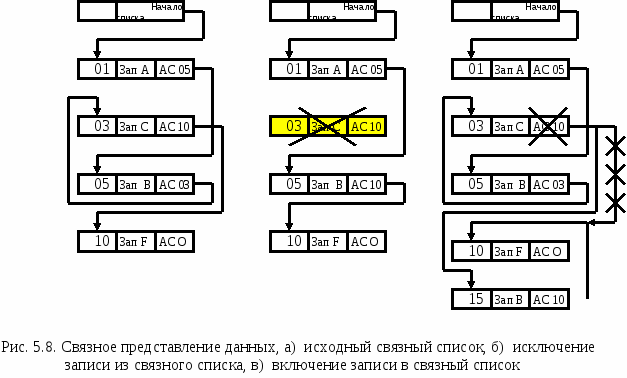
Рис. 1.8. Структура хранения массива
Одна из ячеек – головная – содержит указатель на ячейку с первой записью списка. В соответствии с указателями первым будет прочитано содержимое ячейки 01 (Зап. А), затем содержимое ячеек 05 (Зап. В), 03 (Зап. С), 10 (Зап. F). Символ АС О, помещенный в поле указателя последней записи списка, означает конец списка. Вместо символа АС О может быть использован любой другой элемент данных, который не воспримется системой как указатель.
Связанное представление обеспечивает широкие возможности манипулирования данными и большую гибкость структуры хранения. Удаление и добавление новых записей в процессе ведения связанного списка не требует перезаписи элементов массива, но заменяет соответствующие указатели, чтобы не нарушать логический порядок записей.
Рассмотрим процедуру смены указателей в процессе ведения односвязного списка.
Во время операции удаления исключенная запись удаляется из массива вместе со всеми его полями, включая поле указателя. В этом случае цепочка указателей нарушается, и доступ к следующим элементам списка становится невозможным. Указатель на запись, которая логически предшествует удаляемой записи, называется «зависанием», поскольку он указывает на несуществующую запись, и цепочка записей в списке в ней заканчивается. Чтобы логическая цепочка следования за записями не разрушалась, перед исключением записи указатели должны быть заменены. В этом случае значение указателя исключенной записи вводится в поле указателя логически предшествующей записи.
Исключим из списка (рис. 1.8,а) запись С, хранящуюся в ячейке с адресом 03 и имеющую адрес связи АС10. Для этого значение указателя предшествующей записи (Зап. В) изменим на АС10. Теперь доступ к записи С стал невозможен и запись С оказалась исключенной из списка (рис. 1.8,б). Освободившаяся ячейка с помощью указателей включается в связанный список свободных ячеек.
Возможен и другой способ удаления записей, когда исключаемая запись помечается специальным символом исключения, физически оставаясь в списке. В этом случае возможен доступ к полю указателя, цепочка записей не разрушается и замена указателей не требуется.
Для включения в односвязный список новой записи из списка свободных ячеек берется первая ячейка, в информационном поле которой размещается новая запись, а в поле указателя заносится адрес хранения логически следующей записи. Адрес ячейки с новой записью становится указателем логически предшествующей записи. Так как для размещения новых записей могут использоваться любые свободные ячейки, список может расти неограниченно и предварительного резервирования памяти не требуется.
На рис. 1.8, в изображен связанный список с вновь включенной записью D, логически следующей за записью С. Запись D размещается в ячейке с адресом 15. После замены указателей устанавливается порядок чтения ячеек памяти 01, 05, 03, 15, 10, обеспечивающий логическую последовательность записей: Зап. А, Зап. В, Зап. С, Зап.D Зап. F.
Односвязный список может быть организован в виде замкнутого кольца (рис. 1.9). В этом случае указатель на последнюю запись будет адресом первой. Этот список также называется циклическим. Вы можете начать просмотр кругового списка из любой ячейки. Условием окончания просмотра может быть либо совпадение количества просмотренных записей с общим количеством записей в списке, либо совпадение указателя с адресом первой прочитанной ячейки. В последнем случае адрес первой считанной ячейки должен быть запомнен и сравниваться каждый раз, когда следующая запись читается с указателем.
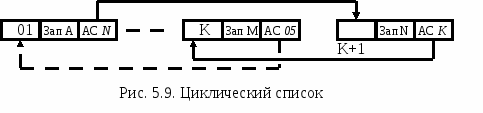
Рис. 1.9. Циклический список
Соответствующее представление данных используется для хранения нелинейных структур данных, а также для реализации линейных структур в случаях, когда предельный размер информационного массива заранее не известен (поэтому требования к размеру памяти непредсказуемы); информационный массив часто подвергается изменениям, и с данными выполняются многочисленные операции добавления и удаления. Принимая решение о выборе представления данных в памяти компьютера, следует помнить, что связанное представление приводит к дополнительному потреблению памяти компьютера под указателями.
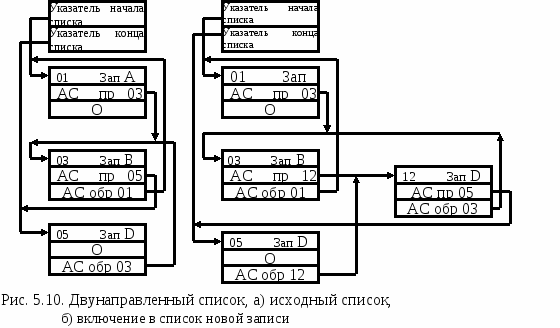
Рис. 1.10. Двунаправленный список:
а) исходный список;
б) включение в список новой записи.
В ряде задач необходимо иметь возможность перемещаться по связанному списку в обоих направлениях. Для этого в каждый элемент списка вводится дополнительный указатель, который указывает прогресс в списке в обратном направлении. Такой список называется двунаправленным. Адрес ячейки с записью, которая логически предшествует этой записи, вводится в поле указателя (рис. 1.10, а). В этом случае ячейка head содержит указатели на первую и последнюю ячейки списка. Поиск в двунаправленном списке возможен как с начала, так и с конца списка. В процессе добавления (удаления) записи в двусвязный список прямые и обратные указатели меняются, как показано на рис. 1.10, б. Наличие обратного указателя позволяет упростить алгоритм изменения указателей, поскольку обратный указатель удаленной записи хранит адрес ячейки с логической предшествующей записью.
В односвязном списке этот адрес должен быть определен с использованием дополнительных процедур. Использование двунаправленного списка ускоряет поиск и поддержание информационного массива, однако увеличивается потребление памяти для указателей.
Для реализации связанного представления данных язык программирования должен иметь определенные средства, а именно, иметь данные типа «указатель». При работе с языками программирования, которые не имеют данных «указателя», связанное представление моделируется с использованием структуры массива.
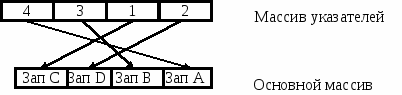
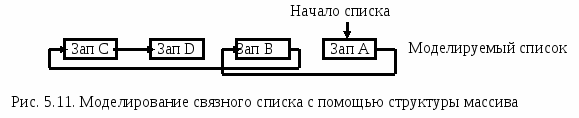
Рис. 1.11. Моделирование связного списка с помощью структуры массива
Пусть структура данных определена как массив М(I). Для определения порядка чтения элементов массива, не совпадающего с физическим порядком их следования, можно организовать вспомогательный вектор указателей N(J), элементы которого — целые числа - определяют порядковые номера (индексы) записей основного массива. На рис. 1.11 изображены два одномерных массива: массив указателей N(J) и основной массив записей М(I), а также моделируемый список. Процедура чтения основного массива организуется с учетом того, что I = N(J). Таким образом, вектор N(J) при изменении значения J от 1 до 4 задает следующий порядок чтения записей основного массива: Зап. А, Зап. В, Зап. С, Зап. D. Можно использовать другой способ моделирования связанного представления данных с помощью структуры массива. При этом каждый элемент массива должен состоять из нескольких (минимум двух) полей. Последнее поле отводится под указатель. Значение этого поля (целое число) представляет собой индекс или номер элемента массива, являющегося следующим элементом связанного списка.
1.5 Элементарные данные
Элементарные данные (числа, символы, логические данные, ссылки) имеют конкретное машинное представление и занимают четко определенные единицы компьютерной памяти. Это позволяет рассчитать объем памяти, необходимый для размещения информационных массивов.
Числовые данные доступны на всех языках программирования. К ним относятся целые, действительные и комплексные числа.
Целые числа могут быть представлены в двоичном и десятичном виде. При хранении целых чисел в двоичной форме одно машинное слово выделяется для одного числа. Крайний левый бит размещается под знаком. Плюс кодируется 0, минус - 1. Позиции под номером перемещаются справа налево, остальные позиции, не занятые номером, заполняются нулями. Отрицательные числа обычно представлены в дополнительном коде.
При хранении целых чисел в десятичной форме каждая десятичная цифра числа кодируется четырехзначным двоичным кодом, то есть две десятичные цифры хранятся в байте. Эта форма хранения называется упакованной десятичной формой. Самый правый клев зарезервирован для знака, плюс имеет код 1100, минус - 1101. Например, число +9613, представленное в упакованном десятичном виде, записывается следующим образом: 1001 0110 0001 0011 1100.
Действительные числа могут быть представлены в виде фиксированной и плавающей запятой. Вещественные числа с фиксированной запятой (точка) хранятся так же, как и целые числа. Положение точки в структуре хранилища не отображается, она фиксируется переводчиком.
Числа с большей битовой глубиной обычно представлены в форме с плавающей запятой. Они состоят из двух частей: мужской и порядковой. Для хранения обеих частей обычно выделяется компьютерное слово, а в некоторых компьютерах - двойное слово. Далее сохраняется порядок - в верхнем левом байте левый бит этого байта используется для хранения знака мантиссы (рис. 1.13). Мантисса числа может иметь двоичное, восьмеричное или шестнадцатеричное представление. Многие компьютеры имеют возможность представлять числа с плавающей запятой двойной точности. Объем выделяемой им памяти удваивается..
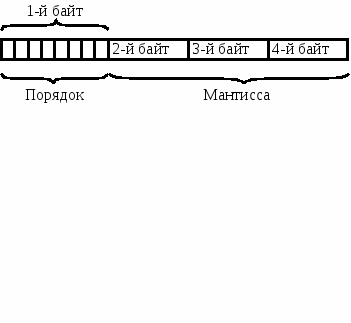
Рис. 1.13. Машинное представление чисел с плавающей точкой
Символьные данные включают буквы латинского и кириллического алфавита, строчные и заглавные буквы, цифры, знаки операций и специальные символы, управляющие символы. Латинские и русские буквы, цифры, знаки операций и специальные символы используются для выполнения задач обработки данных, формирования текста, написания программ. Управляющие символы используются для структурирования данных, передачи информации, организации файлов.
Разные компьютеры работают с разными наборами символов и используют разные коды символов. Обычно символы кодируются трехзначным восьмеричным ASCII-кодом. Для сохранения в памяти восьмеричный код каждого символа преобразуется в двоичный код, и для него выделяется один байт. Крайний левый бит байта используется для контрольной цифры.
Логические данные принимают только два значения: «истина» или «ложь». Над логическими данными выполняются различные операции булевой алгебры: OR, AND, N0T - инверсия и т. д.
Представление логических значений в машинной памяти зависит от переводчика, обрабатывающего программу, и от типа компьютера. Для хранения логических данных можно использовать один бит, значение которого равно 1, если истина, и 0, если ложно, но большинство машин не имеют доступа к одному биту памяти. В другом способе хранения машинное слово выделяется для представления логического элемента. В этом случае значения -TRUE- и -FALSE- представлены восемью одиночными и восемью нулевыми битами, соответственно, в крайнем левом байте машинного слова. Этот способ представления логических значений неэффективно использует компьютерную память. Однако это обеспечивает быстрый доступ к логической информации, поскольку при выполнении машинных инструкций машинное слово является основной единицей обмена между OP и процессором.
1 байт может использоваться для представления логического значения. Значение «истина» кодируется последовательностью битов, состоящей из нулей и одной единицы в крайнем правом бите. Значение «ложь» кодируется последовательностью битов, состоящей из нулей. Такая презентация наиболее эффективна, поскольку обеспечивает быстрый доступ и экономно использует машинную память.
В программах, которые реализуют нечисловые операции, более полезным типом данных является не один символ, а строка символов, сформированная из отдельных символов в результате операции конкатенации (конкатенации). Некоторые операции возможны над строками: конкатенация, поиск и замена подстроки, проверка идентичности строк, определение длины строки.
Символы, составляющие строку, хранятся в последовательных байтах памяти. При кодировании символов в ASCII для каждого символа выделяется 1 байт, поэтому целое число символов помещается в машинное слово. Объем памяти, необходимый для размещения строки фиксированной длины, резервируется переводчиком в соответствии с декларацией. Для строки переменной длины, максимальный размер которой объявлен в программе, память выделяется для максимальной длины строки.
Строка битов - это специальный тип символьной строки, содержащий только символы «0» и «1». Для запоминания битовой строки для каждого элемента выделяется одна двоичная цифра. Например, в машинное слово может помещаться битовая строка длиной 32 бита. Вы можете выполнять те же действия над битовыми строками, что и над символьными строками.
Указатель (ссылка) - это элемент данных фиксированного размера. Он используется для реализации связанного представления данных в машинной памяти. Указатель может быть абсолютным адресом данного или его относительным адресом. Относительный указатель содержит значение смещения в области памяти относительно некоторого базового адреса этой области. Поскольку указатель является адресом, он хранится так же, как и адрес. В большинстве компьютеров слово или половинное слово используется для хранения адреса в памяти.
2. СПООБЫ ПРЕДСТАВЛЕНИЯ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
2.1 Формы с плавающей и фиксированной точкой
Существует 2 способа предcтавления чисел: с плавающей и фиксированной точкой.
|
Общий вид представления числа с фиксированной точкой:
|
Зн |
2-1 |
... |
2-n |
|
Зн |
2-1 |
... |
2-15 |
|
< 2 байта, 16 разрядов > |
|
Зн |
2-1 |
... |
2-31 |
|
< 4 байта, 32 разрядa > |
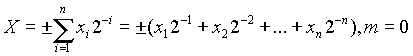
В общем случае неподвижная точка (естественная форма представления чисел) характеризуется значением m (m = соnst). В этом случае для всех чисел, с которыми работает машина, положение точки является постоянным. Вы можете видеть, что когда m = 0, все числа, с которыми работает машина, меньше 1 и представлены как регулярные дроби
В формате с фиксированной запятой битовая сетка имеет n + 1 бит:
xmax0.111...1 - 2n
xmin0.000...1 * 2n
0 x2n
При использовании чисел с фиксированной точкой может возникнуть переполнение.
|
Такое представление числа соответствует нормальной форме записи:
¦ (x1p-1 + x2p-2 + ... + xnp-n)
Здесь p-n - мантисса, pm - порядок.
Пример:
133,21 = 102*1.3321, 102- порядок, 1.3321- мантисса.
1332.1 = 103*1.3321
0.13321 = 10-1*1.3321
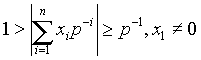
При использовании формата с плавающей запятой используется концепция нормализованного представления чисел.
Нормализованное число - это число, мантисса которого удовлетворяет следующим неравенствам:
Пример:
0,00121 = 10-2*0.121
0.0010 = 2-2*0.101
101.10 = 23 *0.10110
|
Зн.п |
2ln-2 |
... |
20 |
Зн.m |
2-1 |
2lm |
|
< Код порядка > |
< Код мантиссы > |
||
|
< Длина поля порядка > |
< Длина поля мантиссы > |
||
Kn - код порядка
Km - код мантиссы
ln - длина поля порядка
lm - длина поля мантиссы
Знак '-' кодируется единицей, знак '+' - нулем.
Диапазон представления чисел (максимальное число) зависит от того, как велики поля порядка и мантиссы.
Пример:
25*0.110101
|
0 |
101 |
0 |
110101 |
Основной операцией в компьютере является операция сложения. При расчете суммы на компьютере возможны 2 случая: либо термины имеют разные знаки, либо совпадают.
• Алгоритмы получения суммы 2 чисел с общими знаками:
1-й алгоритм
1. Добавьте два числа
2. Назначьте знак одного из дополнений
2-й алгоритм
1. Сравните условия компонентов. Если они одинаковые, то выполните сложение по 1-му алгоритму.
2. Добавьте термины в абсолютном значении, если знаки предметов отличаются.
3. При необходимости переставьте числа местами, чтобы вычесть меньшее из большего.
4. Выполните вычитание.
5. Результат, чтобы назначить знак большего дополнения.
S = A + (-B)
2.2 Формы представления чисел со знаками
Распространенными формами представления чисел со знаками являются их представление в прямом, обратном и дополнительном кодах.
Прямой код числа формируется путем кодирования знака числа нулем, если число положительное, и единицей, если число отрицательное (для двоичной системы).
Для общего случая (q - 1), если число отрицательное, и 0, если число положительное. q - основа системы счисления.
Код знака записывается перед самой старшей цифрой числа и отделяется от нее точкой:
-1.01 = 1.101
Прямой, обратный и дополнительный коды положительных чисел совпадают.
Обратный код отрицательного числа формируется из прямого кода, заменяя его цифры их добавлениями к значению q-1. Код знака сохраняется без изменений.
Пример :
+12310 = 0.123пр. = 0.123об.
-12310 = 9.123пр = 9.876об.
+3А7С0016 = 0.3А7С00пр = 0.3А7С00об.
-3А7С0016 = F.3А7С00пр = F.C583FFоб.
-1012 = 1.101пр = 1.010об.
Замена цифр их дополнениями для двоичной системы совпадает с операцией инверсии, то есть нули заменяются единицами, единицы - нулями. Знак принимает значение, равное единице.
Дополнительный код отрицательного числа формируется из обратного увеличения на 1 его младшего разряда. В этом случае передача от знакового бита игнорируется.
Пример:
+23610 = 0.236пр.= 0.236об.= 0.236доп.
-23610 = 9.236пр.= 9.763об.= 9.764доп.
-1012 = 1.101пр.= 1.010об.= 1.011доп.
-3А7С16 = F.3А7Спр.= F.C583об.= F.C584доп.
Правила перехода из прямого кода в обратный и из обратного в прямой, а также из прямого в дополнительный и из дополнительного в прямой совпадают друг с другом.
2.3 Форматы чисел в ЭВМ
Рассмотрим представление формата в ЭВМ на примерах форматов, используемых в IBM 360/370 и ПЭВМ.
Как упоминалось ранее, в компьютере информация, представленная с использованием нескольких двоичных цифр, называется его битовой сеткой. Количество этих цифр определяет длину разрядной сетки. Для чисел в данном диапазоне используется битовая сетка с заранее определенной длиной и целью разряда, которая называется указанием числа в определенном формате. Задание диапазона включает в себя выбор системы счисления, кода и разрядности чисел, что отражается в написании формата.
Помимо бита и байта, слово используется для указания длины формата, его производных - полуслова, двойного слова. Двойное слово и полуслово определяются по-разному для разных компьютерных систем. Кроме того, используется понятие тетрада - 4 двоичные цифры, которые можно кодировать, например, одна двоичная цифра.
Назначение разряда в формате структурирует битовую сетку, то есть делит ее на поля, объединяющие разряды аналогичного назначения. Например, разряды мантиссы или ордена. Числовые форматы IBM 360/370 состоят из полуслов, слов и двоичных слов, содержащих 2,4 и 8 байтов соответственно.
Двоичные разряды в форматах формируются слева направо (начиная с нулевого разряда).
|
0 |
1 |
15 |
|
H |
Зн |
Разряды числа |
|
0 |
1 |
31 |
|
F |
Зн |
Разряды числа |
|
0 |
1 |
7 |
31 |
|
E |
Зн |
Характеристика |
Мантисса числа |
|
0 |
1 |
7 |
63 |
|
D |
Зн |
Характеристика |
Мантисса числа |
|
< байт > |
< байт > |
< байт > |
|
Z |
Зона |
Ст.цифра |
Зона |
Цифра |
... |
Зона |
Цифра |
Знак |
Мл.цифра |
|
< байт > |
< байт > |
|
P |
Ст.цифра |
Цифра |
... |
Мл.цифра |
Знак |
Форматы H и F используются для представления двоичных чисел с фиксированной точкой, а E и D - с плавающей. Для представления десятичных чисел требуются форматы Z и P.
В формате H и F записывают целые двоичные числа, представленные в дополнительном коде и имеющие длину соответственно полуслова (короткий формат H) и слова (длинный формат F). Нулевой дволичный разряд является знаком. Формат H позволяет представить числа в диапазоне от -215 до 215-1, формат F - от -231 до 231-1. Форматы E и D служат для представления двоичных чисел с плавающей точкой и имеют длину соответственно слова и двойного слова. В нулевом разряде указывается код знака мантиссы (Зн). В семи следующих разрядах первого байта записывается характеристика (Х), представляющая собой порядок (П), в виде положительного числа . В последующих байтах записывается мантисса.
Форматы E и D описывают двоичные числа в двоично-кодированной шестнадцатеричной системе счисления. Порядок чисел изменяется от -64 до +63.
Характеристика (Х) изменяется от 0 до 127,
Х = Р + 64, то есть смещает порядок в область положительных чисел.
Формат D за счёт большей длины, используемой для увеличения разрядности мантиссы, обеспечивает представление чисел с большей точностью.
Диапазон абсолютных значений чисел в форматах E и D составляет величины от 16-64 до 1663 , что эквивалентно пределам от 10-77 до 1076.
Для представления чисел в формате E и D необходимо перевести число в 16-ричную систему счисления, представить его в форме с плавающей точкой, определить характеристику и занести код знак мантиссы, характеристику и мантиссу в соответствующие поля формата.
Пример:
30010 = 12С16 = 0.12С16*163 = 4312С000E = 43.12С00000000000D
-8010 = -5016 = -0.5016*162 = С2500000E = С250000000000000D
Для положительных чисел при переводе в формат Е впереди пишется 4, для отрицательных - С.
|
Зн |
26 |
25 |
24 |
23 |
22 |
21 |
20 |
|
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
Для положительного числа:
|
0 |
100 |
0001 |
Для отрицательного числа:
|
1 |
100 |
0001 |
210 = 216 = 0.216*161 = 41200000Е = 4120000000000000D
|
0 |
100 |
0001 |
0010 |
0000 |
0000 |
... |
0000 |
Форматы Z и P (зонный и упакованный) используют двоично-десятичную систему исчисления с весами 8421. Каждая десятичная цифра кодируется тетрадой.
Пример:
1510 = 0001 01012-10
Знак числа: если число положительное, то оно кодируется символами A, C, E, F , если же число отрицательное- то символами B и D.
Формат Z (формат зоны) используется для ввода и вывода. Для каждой цифры выделяется 1 байт, и правая тетрада кодирует цифру, а левая зона принимает значение F, если цифра кодируется, и это отличает цифру от кодов других символов в другой информации. Крайний правый байт, кодирующий нижнюю цифру вместо зоны, имеет код символа.
Формат P называется упакованным и используется при выполнении операций с числами. Он получается из зоны путем удаления зон и переноса кода знака в место справа от тетрады, кодирующей нижнюю цифру. Формат имеет целое число байтов, а предварительное требование дополняется слева от нижней цифры нулевой записной книжкой. Форматы Z и P могут иметь длину от 1 до 16 байтов.
Пример:
+3010 = 1Е16 = 001ЕH = 0000001ЕF
-3010 = 1Е16 = FFE2H = FFFFFFE2F
+3010 = 1Е16 = 0.1Е16*162 = 421E0000E = 421E000000000000D
-3010 = 1Е16 = -0.1Е16*162 = C21E0000E = C21E000000000000D
+3010 = F3AOZ = 030AP
-3010 = F3BOZ = 030BP
+32510 = F3F2A5Z = 325AP
ЗАКЛЮЧЕНИЕ
В ходе анализа можно сделать вывод, что в своей работе компьютер может работать с различными данными, которые в зависимости от режима работы и полученных команд могут быть представлены в нескольких различных форматах. Компьютеры хранят и передают информацию, используя системы кодирования для хранения и передачи информации. Методы кодирования разнообразны и зависят от цели. Формы представления данных определяются типами (форматами) данных.
Таким образом, целью работы является рассмотрение способов представления и достижения данных в информационных системах.
Решены следующие задачи:
- Рассмотрены уровни представления данных и их внутреннюю структуру;
- Рассмотрены классификацию структур данных;
- Проанализированы способы представления данных;
- Рассмотрены элементарные данные.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Алексеева Т. В., Амириди Ю. В., Дик В. В. Информационные аналитические системы; Университет - Москва, 2013. - 384 c.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2013. - 528 c.
- Гвоздева, В.А. Информатика, автоматизированные информационные технологии и системы: Учебник / В.А. Гвоздева. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 544 c.
- Емельянов, С.В. Информационные технологии и вычислительные системы / С.В. Емельянов. - М.: Ленанд, 2011. - 84 c.
- Краус М., Вошни Э. Измерительные информационные системы; Мир - Москва, 2010. - 310 c.
- Криницкий Н. А., Миронов Г. А., Фролов Г. Д. Автоматизированные информационные системы; Главная редакция физико-математической литературы издательства "Наука" - Москва, 2010. - 380 c.
- Мезенцев К. Н. Автоматизированные информационные системы; Академия - Москва, 2012. – 174 с.
- Под редакцией Хубаева Г. Н. Информатика. Информационные системы. Информационные технологии. Тестирование. Подготовка к Интернет-экзамену; МарТ, Феникс - Москва, 2011. - 368 c.
- Федорова Г. Н. Информационные системы; Академия - Москва, 2013. - 208 c.
- Шафрин Ю. Информационные технологии. В 2 частях. Часть 2. Офисная технология и информационные системы; Бином. Лаборатория знаний - Москва, 2013. - 336 c.

- Процессор персонального компьютера. Назначение, функции, классификация процессора
- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы
- Курсовая работа
- Налоговой контроль и налоговые проверки
- Особенности употребления пословиц в современном английском языке
- Ложные друзья переводчика
- Шекспиризмы вчера и сегодня
- Содержание и специфические особенности предпринимательской деятельности в сфере строительства
- Современные языки программирования
- Проектирование реализации операций бизнес-процесса «Реализация билетов через розничные кассы»
- Современные языки программирования»
- Виды и состав угроз информационной безопасности