
Способы представления данных в информационных системах.
Содержание:

Введение.
В данном курсовом проекте будет рассмотрено как представляются данные в информационных системах. Разберем классификацию информационных систем. Опишем типы и структуры данных. Данный курсовой проект должен помочь повысить знания в области системной информационной области.
Знание структур данных обязательно при проектирование информационных систем. Это ускорят разработку, повышает надежность информационных систем.
Также, в этом проекте будет уделено время терминологии для более правильного понимания информационных систем.
1. Информационные системы.
1.2 Основные понятия и определения.
Термин «информация», для которого семантически наиболее близки значения «осведомление», «представление» и «разъяснение». Информация должна поставлять сведения, но не внушать идеи мнения. Рифгат Абдеев – российский кибернетик, специалист по теории познания и философии информационного общества, доктор философских наук, кандидат технических наук, профессор. Подобное понимание информации, которое называет докибернетическим, сохранялось вплоть до середины ХХ века. Однако, развивающееся научное познание существенно углубило понятие информации, связав его с категорией отражения, что оказалось методологически плодотворным для проникновения в сущность изучаемого феномена. «Сегодня информация уже мыслится как важнейшая субстанция, или среда, питающая исследователей, разработчиков, которая ими же и создается и непрерывно обновляется. Это была фундаментальная и, вместе с тем, неожиданная идея. Совсем не просто было понять, что в различных системах (технических, биологических) циркулируют одинаковые потоки информации, что одна и та же информация может храниться в различных физических носителях и передаваться по каналам, чрезвычайно разным по своей природе. Встав в один ряд с такими категориями, как материя и энергия, информация превратилась в необычайно широкое понятие и продолжала раскрываться все шире и шире». (Р. Ф. Абдеев, 1994 г.). В зависимости от области знаний, в которой производится исследование, информация имеет множество определений.
Информация – обозначение некоторой формы связей, или зависимостей объектов, явлений, процессов, относящихся к определенному классу закономерностей материального мира и его отражения в человеческом сознании.
Информация – сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний.
Данные – сведения, зафиксированные в некоторой форме, пригодной для обработки, передаче, хранения, например, находящаяся в памяти ЭВМ или подготовленная для ввода в ЭВМ. Более подробно о типах и структурах данных, будет расписано во втором разделе данного курсового проекта.
Следующий термин, который проанализируем будет «система». Термин система является из самых распространенных, используемых при описании работ в разных научных дисциплинах. Этот термин перегружен и имеет различный смысл при различных обстоятельствах и для различных людей. Приведем определение слова «система», взятое из книги С. И. Ожегова «Словарь русского языка».
Система:
- Определенный порядок в расположении и связи частей чего-нибудь, в действиях;
- Форма организации чего-нибудь (избирательная система);
- Нечто целое, представляющее собой единство закономерно расположенных и находящихся во взаимосвязи частей (нервная система, грамматика русского языка);
- Совокупность организаций, однородных по своим задачам;
- Техническое устройство, конструкция.
Приведем еще толкование слова система – это совокупность связанных элементов, объединенных в одно целое для достижения определенной цели. Под целью понимается совокупность результатов, определяемых назначением системы. Элемент принадлежит системе, потому, что связан с другими ее элементами так, что множество элементов, составляющих систему, невозможно разбить на два или более несвязанных подмножества. Удаление из системы элемента или совокупности элементов непременно изменяет её свойства в направлении, отличном от цели. Более строгое и правильное определение, на мой взгляд, будет следующее:
Система – множество элементов, находящихся в отношения или связях друг с другом, образующих целостность или органическое единство.
Основные признаки систем:
- Системы имеют структуру. Структура характеризует организованность системы, устойчивую во времени упорядоченность элементов и связей;
- Системы созданы для каких-либо целей и выполнения функций;
- Элементы системы. Имеют связи друг с другом, соединены определенным образом;
- Подсистемы – относительно независимая часть системы, обладающая свойствами системы и имеющая подцель.
Архитектура системы – принципиальная организация системы, воплощенная в её элементах, их взаимоотношениях друг с другом и со средой, а также принципы, направляющие её проектирование и эволюцию.
Архитектура программного обеспечения – совокупность важнейших решений об организации программной системы.
Информационные ресурсы – совокупность данных, организованных для эффективного получения достоверной информации.
Пользователи информационной системы – лицо или группа лиц, или организация, пользующаяся ресурсами информационных систем, для получения информации в решении своих задач.
Информационная система – совокупность средств сбора, передачи, обработки и хранения информации, а также персонал, выполняющий подобные действия, организационно-упорядоченная совокупность информационных ресурсов и информационных технологий, реализующих информационные процессы.
1.2 Классификация информационных систем.
Классификация информационных систем (ИС) по уровню управления:
- информационные системы оперативного уровня – бухгалтерская, обработки заказов, регистрация билетов, выплаты зарплат;
- информационная система специалистов – офисная автоматизация, обработка знаний (сюда включаются экспертные системы);
- информационные системы тактического уровня – мониторинг, администрирование, принятие решений;
- стратегические информационные системы – формулирование целей, стратегическое планирование.
Теперь рассмотрим подробно эти уровни управления ИС.
Информационная система оперативного уровня поддерживает специалистов-исполнителей, обрабатывая данные о сделках и событиях (счета, накладные, зарплаты). Назначение ИС на этом уровне – это отвечать на запросы о текущем состоянии и отслеживать поток сделок в фирме. Чтобы с этим справиться, ИС должна быть доступной, непрерывно действующей и предоставлять точную информацию. Задачи и цели данной ИС на оперативном уровне заранее определенны и структурированы. ИС оперативного уровня является связующим звеном между организацией и внешней средой. Когда система работает плохо, то организация либо не получает информацию из вне, либо не выдает не точную информацию. Данная ИС – это основной поставщик информации для остальных типов ИС в организации, так как содержит оперативную и архивную информацию.
Информационные системы специалистов помогают специалистам, работающим с данными, повышают продуктивность работы инженеров и проектировщиков. Задача подобных систем – это интеграция новых сведений в организацию и помощь в обработке бумажных документов. Основная цель – обработка данных, упрощение канцелярского труда.
Информационные системы тактического уровня. Основные функции сравнение текущих показателей с прошлыми, составление отчетов за определенное время, доступ к архивной информации.
Системы поддержки принятия решений обслуживают частично структурированные задачи, результаты, которые трудно спрогнозировать. Информацию получают из управленческих и операционных ИС. Используют такие системы люди принимающие решения (ЛПР): менеджеры, аналитики, специалисты. Характеристика систем поддержки принятия решений:
- обеспечивают решение проблем, развитие которых трудно прогнозировать;
- оснащены сложными инструментальными средствами моделирования и анализа;
- позволяют легко менять постановки решаемых задач и входные данные;
- отличаются гибкостью и легко адаптируются к изменению условий несколько раз в день;
- имеют технологию, максимально ориентированную на пользователя.
Стратегические информационные системы. Развитие и успех любой организации определяются принятой в ней стратегией. Под стратегией понимается набор методов и средств решения перспективных долгосрочных задач. В этом контексте можно воспринимать и понятия стратегический метод, стратегическое средство, стратегическая система.
Стратегическая ИС – компьютерная ИС, обеспечивающая поддержку принятия решений по реализации перспективных стратегических целей развития организации. Известны ситуации, когда новое качество ИС заставляло изменять не только структуру, но и деятельность организации для их процветания.
Классификация ИС по степени автоматизации.
В зависимости от степени автоматизации информационных процессов в организации, ИС классифицируются на ручные, автоматические, автоматизированные.
Ручные информационные системы характеризуются технических средств обработки информации и выполнение всех операций человеком.
Автоматические информационные системы выполняют все операции по переработке информации без участия человека.
Автоматизированные информационные системы предполагают участие в процессе обработки информации человека и технических средств. Например, роль бухгалтера в ИС по расчету заработной платы заключается в задании исходных данных. ИС обрабатывает их по заданному алгоритму с выдачей результативной информации в виде ведомости, напечатанной на принтере.
Классификация ИС по характеру использования информации.
Информационно-поисковые системы производят ввод, систематизацию, хранение, выдачу информации по запросу пользователя без сложных преобразований данных (информационно-поисковая система в библиотеке, в железнодорожных и авиакассах).
Информационно-решающие системы осуществляют все операции переработки информации по определенному алгоритму. Среди них можно провести классификацию по степени воздействия выработанной результатной информации на процесс принятия решений и выделить два класса — управляющие и советующие системы.
Управляющие информационные системы вырабатывают информацию, на основании которой человек принимает решение. Для этих систем характерен тип задач расчетного характера и обработка больших объемов данных. Примером могут служить система оперативного планирования выпуска продукции, система бухгалтерского учета.
Советующие информационные системы вырабатывают информацию, которая принимается человеком к сведению и не превращается немедленно в серию конкретных действий. Эти системы обладают более высокой степенью интеллекта, так как для них характерна обработка знаний, а не данных. Например, существуют медицинские информационные системы для постановки диагноза больному и определения предполагаемой процедуры лечения. Врач может принять к сведению полученную информацию, но и предложить иное решение по сравнению с рекомендуемым системой.
Классификация ИС по сфере применения.
Информационные системы организационного управления предназначены для автоматизации функций управленческого персонала. Учитывая наиболее широкое применение и разнообразие этого класса систем, часто любые ИС понимают именно в данном толковании. К этому классу относятся ИС управления как промышленными фирмами, так и непромышленными объектами: гостиницами, банками, торговыми фирмами и др.
Информационные системы управления технологическими процессами служат для автоматизации функций производственного персонала. Они широко используются при организации поточных линий, изготовлении микросхем, на сборке, для поддержания технологического процесса в металлургической и машиностроительной промышленности.
Информационные системы автоматизированного проектирования
предназначены для автоматизации функций инженеров-проектировщиков, конструкторов, архитекторов, дизайнеров при создании новой техники или технологии. Основными функциями подобных систем являются: инженерные расчеты, создание графической документации (чертежей, схем, планов), создание проектной документации, моделирование проектируемых объектов.
Интегрированные (корпоративные) информационные системы используются для автоматизации всех функций фирмы и охватывают весь цикл работ от проектирования до сбыта продукции. Создание таких систем весьма затруднительно, поскольку требует системного подхода с позиций главной цели, например, для получения прибыли, завоевания рынка сбыта и т.д. Такой подход может привести к существенным изменениям в самой структуре фирмы, на что может решиться не каждый управляющий.
2. Данные.
2.1 Типы данных.
Тип данных – класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применимы. Тип определяет возможные значения и их смысл, операции, а также способы хранения значений типа.
Тины данных характеризуют одновременно множество допустимых значений, которые могут принимать данные и набор операций, которые можно осуществлять над данными.
Существуют различные классификации типов данных и правил их назначения. Типы данных делят на скалярные и нескалярные. Значение нескалярного типа имеет множество видимых пользователю компонентов, а значение скалярного типа не имеет такового. Примерами нескалярного типа являются массивы, списки, а примеры скалярного типа – целые, логические.
Рассмотрим распространенные типы данных.
Логически тип данных, или булевый тип – примитивный тип данных в информатике, принимающий два возможных значения, называемых – истиной (true) и ложью (false). Булев тип данных может быть реализован и храниться в памяти с использованием только одного бита.
Целочисленный тип данных (Integer) – простейший и самый распространенный тип данных, служит для представления целых чисел. Целые числа и вычисления с целыми числами в современных компьютерах имеют очень важное значение, потому что подавляющее количество приложений занимают меньше ресурсов процессора, чем арифметика с плавающей точкой. Вся адресная арифметика и операции с индексами массивов основаны на целочисленных операциях.
Числа с плавающей точкой – экспоненциальная форма представления вещественных чисел, в которой хранится в виде мантиссы и порядка (показателя степень). Число с плавающей точкой имеет фиксированную относительную точность и изменяющуюся абсолютную. Реализация математических операций с числами с плавающей точкой в вычислительных системах может быть, как аппаратная, так и программная.
Строковый тип (string) – тип данных, значениями которого является произвольная последовательность символов алфавита. Переменная такого типа (строковая переменная) может быть представлена фиксированным количеством байт, либо иметь произвольную длину.
Указатель (pointer) – переменная, диапазон значений, который состоит из адресов ячеек памяти или специального значения – нулевого адреса. Последнее используется для указания того, что в данный момент времени указатель не ссылается ни на одну из допустимых ячеек.
2.2 Структуры данных.
Структура данных это способ хранить и организовывать данные, для эффективного решения различных задач. Данные можно представить по-разному. В зависимости от того, что за данные и что мы собираемся делать, одно представление подойдет лучше других. Рассмотрим структуры данных.
Связный список является одной из самых основных структур данных. 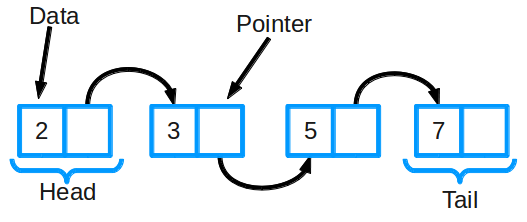
Связанный список состоит из группы узлов, которые представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся и могут быть представлены любим типом данных, и указатель на следующий узел в последовательности.
Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Стек – базовая структура данных, в которой можно только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если захотеть взглянуть на книгу в середине стека, то с начало необходимо взять книги, лежащие сверху. Это означает, что последний элемент, который добавлен в стек, это первый элемент, который из него выходит.

Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (push), удаление элемента из стека (pop) и отображение содержимого стека (pip).
Очередь. Стоящий первым будет обслужен первым.

Это означает, что после добавления нового элемента, все элементы, которые были добавлены до этого, должны быть удалены до того, как новы элемент будет удален. В очереди есть две основные операции: добавление элемента (enqueuer) в конец очереди и удаление элемента (dequeuer).
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
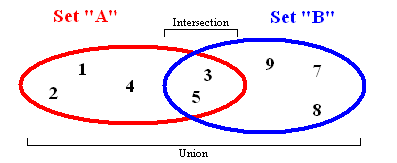
Union (объединение). Объединяет все элементы из двух разных множеств и возвращает результат, как новый набор без дубликатов.
Intersection (пересечение). Если заданы два множества, эта функция вернет другое множество, содержащее элементы, которые имеются и в первом и во втором множестве.
Difference (разница). Вернет список элементов, которые находятся в одном множестве, но не повторяются в другом.
Subset (подмножество) – возвращает булево значение, показывающее, содержит ли оно множество все элементы другого множества.
Map (мэп) – это структура данных, которая хранит данные в парах ключ/значение, где каждый ключ уникален.
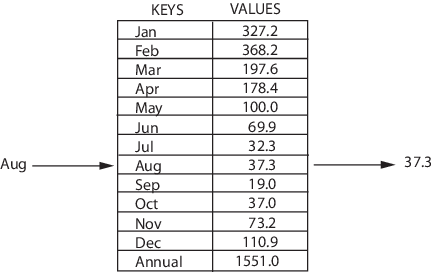
Map иногда называется ассоциативным массивом или словарем. Она часто используется для быстрого поиска данных. Map’ы позволяют делать следующее:
- добавление пары в коллекции;
- удаление пары из коллекции;
- изменение существующей пары;
- Поиск значения, связанного с определенным ключом.
Хеш-таблица – это структура данных, реализующая интерфейс map, который позволяет хранить пары ключ/значение. Она использует хеш-функцию для вычисления индекса в массиве, по которым можно найти желаемое значение.
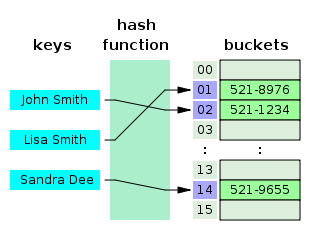
Хеш-функция обычно принимает строку и возвращает числовое значение. Хеш-функция всегда должна возвращать одинаковое число для одного и того же ввода. Когда два ввода хешируются с одним и тем же цифровым выходом, это коллизия. Суть в том, чтобы их было как можно меньше.
Поэтому, когда вы вводите пару ключ / значение в хеш-таблице, ключ проходит через хеш-функцию и превращается в число. Это числовое значение затем используется в качестве фактического ключа, в котором значение хранится. Когда вы снова попытаетесь получить доступ к тому же ключу, хеширующая функция обработает ключ и вернет тот же числовой результат. Затем число будет использовано для поиска связанного значения. Это обеспечивает очень эффективное время поиска O (1) в среднем.
Двоичное дерево поиска.
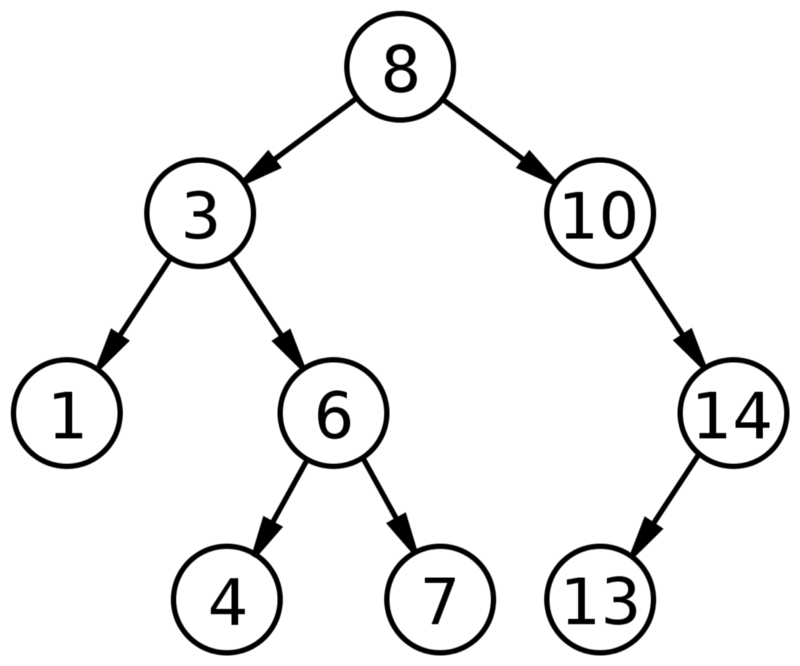
Дерево – это структура данных, состоящая из узлов. Она имеет следующие характеристики:
- каждое дерево имеет корневой узел (вверху);
- корневой узел имеет ноль или более дочерних узлов;
- каждый дочерний узел имеет ноль или более дочерних узлов.
Двоичное дерево поиска имеет еще две характеристики:
- каждый узел имеет до двух детей (потомков);
- для каждого узла его левые потомки меньше текущего узла, что меньше, чем у правых потомков.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Способ их настройки означает, что в среднем каждое сравнение позволяет операциям пропускать половину дерева, так что каждый поиск, вставка или удаление занимает время, пропорциональное логарифму количества элементов, хранящихся в дереве.
Префиксное дерево. Дерево префикса – это своего рода дерево поиска. Оно хранит данные в шагах, каждый из которых является его узлом. Префиксное дерево из-за быстрого поиска функции автоматического дописывания часто используют для хранения слов.
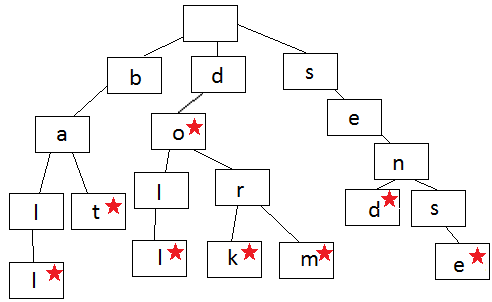
Каждый узел в префиксном дерево содержит одну букву слова. Следую ветвям дерева, чтобы записать слово, по одной букве за раз. Шаги начинают расходиться, когда порядок букв отличается от других слов в дереве или, когда заканчивается слово. Каждый узел содержит букву (данные) и логическое значение, указывающее, является ли узел последним узлом в слове.
Графы представляют собой совокупность узлов (вершина графа) и связей (ребро графа) между ними.
Одним из примеров графов, может служить социальная сеть. Узлы – это люди, а ребра – это связь между людьми или дружба.
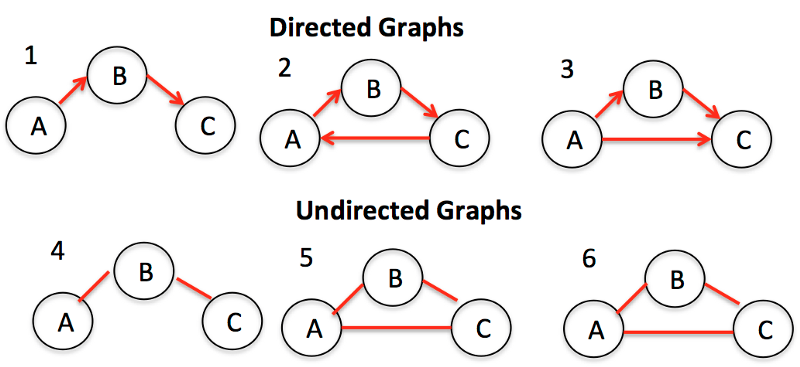
Существует два основных типов графов: ориентированный и неориентированный. Второй тип – граф без какого-либо направления на ребрах между узлами. Ориентированный графы, напротив, представляют собой графы с направление на них. Два частых способа представления графа – это список смежности и матрица смежности.
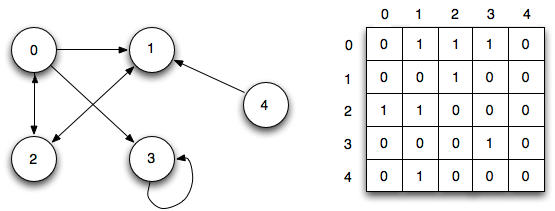
Список смежности может быть представлен как список, где левая сторона является узлом, а правая – списком всех других узлов, с которыми он соединен.
Матрица смежности представляет собой таблицу чисел, где каждая строка или столбец представляет собой другой узел на графе. На пересечении строки и столбца есть число, которое указывает на отношение. Нули означают, что нет ребер или отношений. Единицы означают, что есть отношения. Числа выше единицы могут использоваться для отображения разных весов.
Алгоритмы обхода – это алгоритмы для перемещения или посещения узлов в графе. Основными типами алгоритмов обхода являются поиск в ширину и поиск в глубину. Одно из применений заключается в определении того, насколько близко узлы расположены по отношению к корневому узлу.
Теперь перейдем к следующему разделу, в котором будет рассказано как эти структуры данных представляются в информационных системах.
3. Системы обработки данных.
Автоматизированная система обработки данных (СОД) – это комплекс взаимосвязанных методов и средств преобразования данных, необходимых пользователю. Данные понимаются как информация, представленная в формализованном виде и пригодном для автоматической обработки при участии человека.
В составе СОД можно выделить ряд подсистем. Основной из них является система обработки и хранения информации, реализующая все функции СОД, связанные с организацией, хранением, обработкой, поиском и выдачей информации. Центральной частью этой подсистемы является информационный фонд, состоящий из информационных массивов.
Информационный массив образуется совокупностью организованный единиц информации, описывающих соответствующий класс объектов. Объектом может быть человек, предмет, процесс, явление, документ, понятие.
Информационный массив является поставщиком сведений, содержащий информацию об объектах. Массив должен адекватно отражать отношения, существующие в реальной предметной области и обеспечивать информационные потребности определенного круга пользователей и приложений.
В процессе функционирования СОД элементы информационного массива подвергаются различным обрабатывающим процедурам. Массивы сортируются, перестраиваются, в них осуществляются поисковые процессы. Для отображения текущего состояния реальных объектов массивы должны постоянно актуализироваться: из них удаляется устаревшая информация, добавляется новая, элементы массива корректируются в соответствии с изменениями, происходящими в объектах. Структура массива не должна разрушаться или искажаться в результате выполнения процедур обработки и актуализации.
Информационные массивы размещаются в памяти ЭВМ. От того, насколько правильно выбраны устройства памяти, способы размещения и выборки массивов, зависят показатели качества функционирования системы обработки и хранения информации и всей СОД вцелом.
3.1 Представление данных в системах обработки данных.
Системы обработки данных (СОД) хранят и обрабатывают информацию об объектах реального мира. Информация описывающая конкретный объект, называют логической записью или просто записью. Совокупность записей, охватывающих множество объектов определенного класса, называют информационным массивом.
В реальном мире между объектами существуют определенные отношения и взаимосвязи различную по степени сложности. В процессе разработки в СОД эти отношения выявляются и отображаются путем структуризации записей и информационных массивов. Организация информационного массива, обеспечивающая определенные связи и отношения между данными, называется структурой данных.
Существует три уровня представления данных: логический, уровень хранения и физический.
На логическом уровне работают с логическими структурами данных, отражающими реальные отношения между объектами и их характеристиками. Единицей информации на этом уровне является логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определенными признаками, являющимися атрибутами записи. На логическом уровне устанавливается перечень признаков, полностью характеризующий описываемый класс объектов. Совокупность признаков и их взаимосвязь определяют внутреннюю структуры логической записи.
Логическая структура данных должна исчерпывающе характеризовать объекты, сведения о которых обрабатываются СОД, адекватно отражать реальные отношения между объектами и их характеристика, обеспечивать удовлетворение информационных потребностей пользователей системы.
На уровне хранения оперируют со структурами хранения – представление логической структуры данных в памяти ЭВМ. Структура хранения должна полностью отображать логическую структуру данных и поддерживать её в процессе функционирования СОД. Единице информации на этом уровне также является логическая запись. При разработке или выборе структуры хранения должны учитываться особенности организации памяти ЭВМ. При этом устанавливается тип и формат данных, определяется способ поддержания логической структуры.
Каждая структура хранения предоставляет определенный способ доступа к данным и определенные возможности манипулирования данными. От выбора структуры хранения непосредственно зависит эффективность обработки данных. Поддержание структуры хранения осуществляется программными средствами. Для реализации этой структуры требуются определенные языки программирования, возможности которых, следует учитывать при разработке или выборе структуры хранения.
На физическом уровне представления данных оперируют с физическими структурами данных. На этом уровне решается задача реализации структуры хранения непосредственно в конкретной памяти ЭВМ. Единицей информации является физическая запись, представляющая конкретный участок носителя, на котором размешается одна или несколько логических записей. При разработке структур памяти анализируются: тип и объем памяти, способ адресации, методы и время доступа. На этом уровне решаются задачи по организации обмена данными между оперативной и внешней памяти ЭВМ.
При разработке структур данных всех уровней должен обеспечиваться принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в техническом обеспечении системы не должны отражаться на логических структурах и прикладных программ. Логическая независимость данных означает, что изменения в структурах хранения не ложны вызывать изменений в логических структурах данных и в прикладных программах. Изменения, вносимые в логические структуры данных в связи с появление новых пользователей и новых запросов, не должны отражаться на прикладных программах других пользователей системы.
Соблюдение принципа независимости данных позволяет использовать особые виды данных: виртуальные и прозрачные.
Виртуальные данные существуют только на логическом уровне. Для программиста это как бы реально существующие данные, которыми он оперирует в программах. Каждый раз, при обращении к этим данным, операционная система определенным образом их генерирует на основании других данных, физически существующих в системе. Объявление некоторых данных виртуальными позволяет экономить машинную память.
Прозрачные данные представляются несуществующими на логическом уровне. Это позволяет скрыть от пользователя многие сложные механизмы, используемые при преобразовании логических структур данных в физические.
СОД имеют многоуровневую структуру данных состоящих из пяти уровней. Элементы каждого уровня имеют определенное название. Формирование элементов более высокого уровня осуществляется из элементов нижнего уровня в соответствии с определенными правилами.
Первый, самый нижний уровень составляют элементарные данные: числа, символы, логические данные, знаки. Эти данные не являются непосредственным объектом информационного поиска, но в ряде случаев к ним должен быть обеспечен доступ. Например, в процессе поиска может возникнуть необходимость сравнения отдельных символов в строках. Элементарные данные имеют определенную форму представления в оперативной памяти ЭВМ, для их хранения выделяется строго определенный объем памяти. Знание форматов хранения элементарных данных позволяет рассчитать объем памяти, необходимый для размещения массивов данных и программ.
Элементами второго уровня является поле записи. Это последовательность элементарных данных, имеющая определенный смысл, но не имеющая смысловой завершенности. Данные, образующие отдельное поле записи, описывают соответствующий признак объекта. Каждый признак объекта имеет наименование и значение. Так, для студентов, записи о которых хранятся в СОД, в качестве признаков могут использоваться: номер студенческого билета, ФИО, средний балл успеваемости. Каждый конкретный студент характеризуется определенными значениями этих признаков, например, наименование признака – средний бал, а значение признака – 4,7. Отдельные студенты отличаются значениями одноименных признаков. Отдельные студенты отличаются значениями одноименных признаков.
Число признаков, характеризующих объект, определяет количество полей в записи. В каждом поле помещается значение соответствующего признака. Поля записи именуются, причем имя поля может совпадать с наименованием признака.
Признак, используемый для идентификации записи в процессе обработки или поиска, называется ключевым или ключом записи. Поле записи, содержащее ключ, называется ключевым полем. Если каждое из возможных значений ключа идентифицирует единственную запись, то такой ключ называется уникальным. Так, номер студенческого билета является уникальным ключом каждой записи массива сведений о студентах данного вуза. В записи могут предусматриваться дополнительные поля для хранения служебной информации: меток, ссылок, указателей.
Поле записи может быть объектом информационного поиска в различных приложениях, а также в тех случаях, когда это поле ключевое. Однако поле записи само по себе не имеет смысловой завершенности. Например, поле средний балл может явиться объектом поиска, но информационную ценность значение этого поля будет иметь лишь в том случае, когда станут известными фамилия, имя и отчество студента.
Понятие поля записи не следует отождествлять с понятием поля машинной памяти. Эти понятия относятся к разным уровням представления данных. Для хранения поля записи могут использоваться единицы машинной памяти как фиксированной, так и переменной длины.
Поля записи объединяются в группу данных. Группа данных – элемент третьего уровня внутренней структуры записи – представляет собой поименованную совокупность элементов данных, рассматриваемую как единое целое. Например, группа данных, имеющая наименование адрес, состоит из элементов данных город, улица, номер дома, номер квартиры. В качестве элемента, группа может содержать в себе другую группу данных. Группа данных имеет определенный смысл и может быть объектом поиска, но не имеет смысловой завершенности. Например, адрес полезно знать лишь в том случае, если известно, кому он принадлежит.
Логическая запись представляет четвертый уровень структуры данных – это поименованная совокупность полей или групп данных. Запись является отдельной логической единицей и имеет смысловую завершенность. Каждая запись описывает индивидуальный объект или класс объектов. Логическая запись является непосредственным объектом информационного поиска и основной единицей обработки информации в СОД.
Перечень полей, последовательность их расположения и взаимосвязь между ними составляют внутреннюю структуру записи, которая в конечном итоге определяет тип записи. Поля записи могут располагаться последовательно друг за другом, в этом случае запись будет называться неструктурированной. Запись может быть структурированной, со сложными нелинейными связями между полями. Структуризация записи составляет одну из основных концепций баз данных.
Отдельные логические записи, описывающие определенный класс объектов, группируются в информационный массив, образующий последний, пятый уровень структуры данных. Массивы, хранящиеся во внешней памяти, называются файлами. Файл имеет имя и рассматривается как единое целое. Например, совокупность записей всех студентов учебной группы может рассматриваться как отдельный файл.
Заключение.
В этом курсовом проекте мы научились классифицировать информационные системы по видам и предъявляемым требованиям. Разобрали структуры данных, дали основные и важные термины. Также стало понятно, как данные представляются в информационных системах.
В заключении данного курсового проекта хочу сказать, что знание структур и способов представление данных, необходимо при проектирование информационных систем. В дополнении, разработчику будет проще выбрать алгоритм обработки данных в соответствии требованиями к информационной системы.
Список использованной литературы
1. Советов Б.Я., Яковлев С.А. Моделирование систем: Учебник для вузов. - М.: Высшая школа, 2001. - 320 с.
2. Кормен Т., Лейзерсон Ч., Ривест Р Алгоритмы: построение и анализ. М., «МЦНМО», 2000.
3. Брюхомицкий Ю. А. Введение в информационные системы. 2001.
4. И. Л. Чудинов, В. В. Осипова. Информационные системы и технологии. 2013.
5. Кумскова И.А. Базы данных. - М.: КноРус, 2012. - 488 с.

- Информация в материальном мире (История информации)
- Разработка регламента выполнения процесса «Обеспечение послепродажного обслуживания» на примере компании ООО «Блэкпринт»
- Сущность, функции, задачи и организация аукционов (Порядок проведения аукцион)
- Сущность, функции, задачи и организация аукционов (Понятие и формы аукционов)
- Анализ деятельности спортивной организации на примере «ФК Зебра» наименование темы
- Колористическая, цветовая и тональная организация живописного произведения Жан-Батист-Камиль-Коро «Первые листья»
- Особенности кадровой стратегии организаций реального сектора экономики (Анализ кадровой стратегии ООО «Авео»)
- Автоматизация продажи авиабилетов (Выбор комплекса задач автоматизации)
- Разработка сайта компании «Авто-тема»
- Автоматизация продажи театральных билетов в Российском академическом молодежном театре
- Понятие, содержание и виды маркетинговой деятельности
- Одаренные дети: проблемы, поиски, пути воспитания и обучения ( Понятие одаренности, ее признаки и виды )