
Алгоритмы сортировки данных
Содержание:

Введение
В этой работе рассматривается тема "Алгоритмы сортировки данных", которая является обязательной в курсе "Информатика и программирование".
Процессом сортировки называют действия по упорядочению некоторых данных по «ключу». Ключ сортировки – ключ, записанный в одном или нескольких полях файла. Использование ключей сортировки позволяет проводить упорядочение записей файла. Ключи могут быть разными. Например, преобразовать таблицу чисел по возрастанию или убыванию, таблицу имен - по алфавиту.
Очевидно, что с "отсортированными" данными работать легче и быстрее, чем с произвольно расположенными. Когда элементы "отсортированы", быстрее найти слово в словаре на 1000 страниц.
Важность темы "сортировки" определяется и особой ролью таблиц. Все применения ЭВМ основаны на их способности к быстрой и точной обработке больших объемов информации, а это возможно только когда информация однородна и отсортирована. Таким образом, таблицы как основное средство представления однородной информации неизбежно используются во всех компьютерных программах.
На табличном принципе основана и архитектура современных ЭВМ: память машины можно рассматривать как большой массив байтов, адреса которых располагаются по возрастанию. Следовательно, без понимания информационной сущности таблиц и основных алгоритмов их обработки невозможно формирование полноценных представлений о возможностях ЭВМ и принципах их работы. Отсюда вытекает необходимость темы "Сортировки " не только в общеобразовательном, но и в углубленном курсах информатики.
Глава 1. Основные понятия
Сортировка – это алгоритмический процесс перестановки объектов данного множества в определенном заданном порядке. Что же такое порядок или какое множество называется упорядоченным? Давайте дадим достаточно строгое определение:
Множество M называется упорядоченным, если между его элементами установлено некоторое отношение: a < b (a предшествует b), обладающее следующими свойствами: между любыми двумя элементами a и b существует одно и только одно из трех соотношений: a = b, a < b < a. Для любых трех элементов a, b и c из a < b < c следует a < c.
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Алгоритмы сортировок очень широко применяются в программировании, но иногда программисты даже не задумываются какой алгоритм работает лучше всех (под понятием «лучше всех» имеется ввиду сочетание быстродействия и сложности как написания, так и выполнения).
Алгоритмы сортировки оцениваются по скорости выполнения и эффективности использования памяти:
Время - основной параметр, характеризующий быстродействие алгоритма, называется также вычислительной сложностью. Для упорядочения важны худшее, среднее и лучшее поведение алгоритма в терминах мощности входного множества «А». Если на вход алгоритму подаётся множество «A», то обозначим n = |A|. Для типичного алгоритма хорошее поведение - это O(n log n) и плохое поведение - это O(n2). Идеальное поведение для упорядочения - O(n).
Память - ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. Как правило, эти алгоритмы требуют O(log n) памяти. При оценке не учитывается место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
Для построения сложных и содержательных программ необходимо уверенное владение общими принципами применения таблиц и базовыми приемами их обработки.
Различают некоторые свойства и классификации сортировок:
Устойчивость - устойчивая сортировка не меняет взаимного расположения элементов с одинаковыми ключами.
Естественность поведения - эффективность метода при обработке уже упорядоченных или частично упорядоченных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Использование операции сравнения. Алгоритмы, использующие для сортировки сравнение элементов между собой, называются основанными на сравнениях. Минимальная трудоемкость худшего случая для этих алгоритмов составляет O(n log n), но они отличаются гибкостью применения.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов упорядочения два:
1) Внутренняя сортировка - оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат. В современных архитектурах персональных компьютеров широко применяется подкачка и кэширование памяти. Алгоритм сортировки должен хорошо сочетаться с применяемыми алгоритмами кэширования и подкачки.
2) Внешняя сортировка - оперирует запоминающими устройствами большого объёма, но не с произвольным доступом, а последовательным (упорядочение файлов), т. е. в данный момент «виден» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам упорядочения, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным во внешней памяти производится намного медленнее, чем операции с оперативной памятью. Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим. Объём данных не позволяет им разместиться в ОЗУ.
Также алгоритмы классифицируются по:
- потребности в дополнительной памяти или её отсутствию
- потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, или отсутствию таковой.
Существует множество различных методов сортировки данных. Алгоритм сортировки условно можно разбить на три основные части:
- сравнение, определяющее упорядоченность пары элементов;
- перестановка, меняющая местами пару элементов;
- собственно сортирующий алгоритм, который осуществляет сравнение и перестановку элементов данных до тех пор, пока все элементы не будут упорядочены.
Глава 2. Методы сортировки данных
При решении олимпиадных задач часто необходима сортировка данных. Обычно данные представлены в виде массива из N элементов, где элементы - это чаще всего числа или строки. Для этого существует множество алгоритмов, которые с помощью замены значений элементов исходного массива приводят его к отсортированному виду.
Для лучшего понимания того, в каких случаях нужно применить тот или иной алгоритм необходимо знать, что понимают под показателем сложности алгоритма. Речь идет о том, как зависит число операций, которые нужно произвести согласно алгоритму от объема данных, в нашем случае от количества элементов массива N. Сложность задачи может быть логарифмической, линейной, квадратичной, экспоненциальной и т.д., где для решения задачи необходимо выполнение O(ln(N)), O(N), O(N2) и O(eN) операций соответственно. Например, квадратичный порядок сложности O(N2) означает, что задача может использовать N2 операций, а может и 100*N2, здесь коэффициент перед N2 не имеет значения: важен порядок, важно знать во сколько раз программа будет работать дольше, если число N увеличится вдвое, втрое или в 10 раз. В нашем случае независимо от этого коэффициента получим, что программа будет выполняться соответственно в 4, 9 и 100 раз дольше.
Наилучшие универсальные алгоритмы сортировки имеют порядок сложности O(n*ln(n)), что позволяет в олимпиадных задачах сортировать массивы для N ~ 300 000. В качестве примера подобных алгоритмов можно привести следующие сортировки: быстрая, пирамидальная, слиянием, бинарным деревом.
Простейшие алгоритмы сортировки имеют порядок O(N2), что позволяет решать задачу с сортировкой только для N <~ 5000. Несмотря на то, что квадратичные алгоритмы дают меньший эффект, их разумно использовать, когда скоростью сортировки данных можно пренебречь, повысив скорость реализации программы. Примеры подобных сортировок: выбором, пузырьком, вставками.
В частных случаях отсортировать данные возможно с линейным порядком сложности, когда есть некоторые ограничения на данные (например, массив уже частично отсортирован или диапазон элементов массива ограничен). С таким порядком сложности возможна сортировка массива, состоящего из 107 элементов. Например, следующие алгоритмы дают такой результат: цифровая и поразрядная сортировки.
Многие считают, что достаточно знания двух сортировок (например, "пузырьком" и "быстрой"), чтобы решать любые олимпиадные задачи. Но на самом деле это далеко не так. Далее, рассмотрим алгоритмы сортировки, наиболее часто используемые программистами.
2.1 Сортировка выбором
Сортировка выбором – возможно, самый простой в реализации алгоритм сортировки. Как и в большинстве других подобных алгоритмов, в его основе лежит операция сравнения. Сравнивая каждый элемент с каждым, и в случае необходимости производя обмен, метод приводит последовательность к необходимому упорядоченному виду.
Идея алгоритма очень проста. Пусть имеется массив A размером N, тогда сортировка выбором сводится к следующему:
- берем первый элемент последовательности A[i], здесь i – номер элемента, для первого i равен 1;
- находим минимальный (максимальный) элемент последовательности и запоминаем его номер в переменную k;
- если номер первого элемента и номер найденного элемента не совпадают, т. е. если k≠1, тогда два этих элемента обмениваются значениями, иначе никаких манипуляций не происходит;
- увеличиваем i на 1 и продолжаем сортировку оставшейся части массива, а именно с элемента с номером 2 по N, так как элемент A[1] уже занимает свою позицию;
С каждым последующим шагом размер подмассива, с которым работает алгоритм, уменьшается на 1, но на способ сортировки это не влияет, он одинаков для каждого шага.
Рассмотрим работу алгоритма на примере конкретной последовательности целых чисел. Дан массив, состоящий из пяти целых чисел 9, 1, 4, 7, 5. Требуется расположить его элементы по возрастанию, используя сортировку выбором. Начнем по порядку сравнивать элементы. Второй элемент меньше первого – запоминаем это (k=2). Далее мы видим, что он также меньше и всех остальных, а так как k≠1, меняем местами первый и второй элементы. Продолжим упорядочивание оставшейся части, пытаясь найти замену элементу со значением 9. Теперь в k будет занесена 3-ка, поскольку элемент с номером 3 имеет наименьшее значение. Как видно, k≠2, следовательно, меняем местами 2-ой и 3-ий элементы. Продолжаем расставлять на места элементы, пока на очередном шаге размер подмассива не станет равным 1-ому.
Код на С++:
|
int i, j; void SelectionSort(int A[], int n) { int count, k; for (i = 0; i<n - 1; i++) { count = A[i]; k = i; for (j = i + 1; j<n; j++) if (A[j]<A[k]) k = j; if (k != i) { A[i] = A[k]; A[k] = count; } } cout << "Отсортированный массив: "; for (i = 0; i<n; i++) cout << A[i] << " "; } |
Сортировка выбором проста в реализации, и в некоторых ситуациях стоит предпочесть ее наиболее сложным и совершенным методам. Но в большинстве случаев данный алгоритм уступает в эффективности последним.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n2) |
O(n2) |
O(n2) |
Сортировка пузырьком (обменная сортировка) – простой в реализации и малоэффективный алгоритм сортировки. Метод изучается одним из первых на курсе теории алгоритмов, в то время как на практике используется очень редко.
Идея алгоритма заключается в следующем.
Соседние элементы последовательности сравниваются между собой и, в случае необходимости, меняются местами. В качестве примера рассмотрим упорядочивание методом пузырьковой сортировки массива, количество элементов N которого равно 5: 9, 1, 4, 7, 5. В итоге должен получиться массив с элементами, располагающимися в порядке возрастания их значений.
Вначале сравниваются два первых элемента последовательности: 9 и 1. Так как значение первого элемента больше значения второго, т. е. 9>1, они меняются местами. Далее сравниваются второй и третий элементы: девятка больше четверки, следовательно, элементы снова обмениваются позициями.
Аналогично алгоритм продолжает выполняться до тех пор, пока все элементы массива не окажутся на своих местах. Всего для этого потребуется N*(N-1) сравнений. В частности, на данной последовательности произведено 20 сравнений и только 5 перестановок.
Код на С++:
|
int i, j, cnt, k; void BSort(int A[], int N) { for (i = 0; i<N; i++) { for (j = 0; j<N - 1; j++) { k = j + 1; cnt = A[k]; if (A[j]>A[k]) { A[k] = A[j]; A[j] = cnt; } }} cout << "Отсортированный массив: "; for (i = 0; i<N; i++) cout << A[i] << " "; } |
Приведенный код можно улучшить, а именно – вдвое уменьшить количество выполняемых сравнений. Для этого достаточно с каждым шагом i внешнего цикла на i уменьшать количество итераций внутреннего цикла.
|
void BSort(int A[], int N) { for (i = 0; i<N - 1; i++) { for (j = 0; j<N - (i + 1); j++) { k = j + 1; cnt = A[k]; if (A[j]>A[k]) { A[k] = A[j]; A[j] = cnt; } } } cout << "Отсортированный массив: "; for (i = 0; i<N; i++) cout << A[i] << " "; } |
Как отмечалось, алгоритм редко используется на практике, поскольку имеет низкую производительность.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n) |
O(n2) |
O(n2) |
2.3 Сортировка вставками
Сортировка вставками – простой алгоритм сортировки, преимущественно использующийся в учебном программировании. К положительной стороне метода относится простота реализации, а также его эффективность на частично упорядоченных последовательностях, и/или состоящих из небольшого числа элементов. Тем не менее, высокая вычислительная сложность не позволяет рекомендовать алгоритм в повсеместном использовании.
Рассмотрим алгоритм сортировки вставками на примере колоды игральных карт. Процесс их упорядочивания по возрастанию будет следующим. Обратим внимание на вторую карту, если ее значение меньше первой, то меняем эти карты местами, в противном случае карты сохраняют свои позиции, и алгоритм переходит к шагу 2. На 2-ом шаге смотрим на третью карту, здесь возможны четыре случая отношения значений карт:
- n1 < n3; n2 < n3;
- n1 > n3; n2 > n3;
- n1 < n3 < n2;
- n1 > n3; n2 < n3.
В первом случае не происходит никаких перестановок. Во втором – вторая карта смещается на место третьей, первая на место второй, а третья карта занимает позицию первой. В третьем случае первая карта остается на своем месте, в то время как вторая и третья меняются местами. Ну и наконец, последний случай требует рокировки лишь первой и третьей карт. Все последующие шаги полностью аналогичны расписанным выше.
Рассмотрим на примере числовой последовательности процесс сортировки методом вставок (Рисунок 1). Клетка, выделенная темно-серым цветом – активный на данном шаге элемент, ему также соответствует i-ый номер. Светло-серые клетки это те элементы, значения которых сравниваются с i-ым элементом. Все, что закрашено белым – не затрагиваемая на шаге часть последовательности.
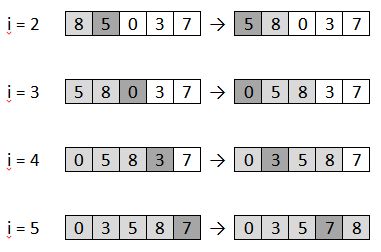
Рисунок 1
Таким образом, получается, что на каждом этапе выполнения алгоритма сортируется некоторая часть массива, размер которой с шагом увеличивается, и в конце сортируется весь массив целиком.
Код на С++:
|
int i, j, k = 0, tmp = 0; void InsertSort(int *mas, int n) { for (i = 0; i<n - 1; i++) { k = i + 1; tmp = mas[k]; for (j = i + 1; j>0; j--) { if (tmp<mas[j - 1]) { mas[j] = mas[j - 1]; k = j - 1; } } mas[k] = tmp; } cout << endl << "Отсортированный массив: "; for (i = 0; i<n; i++) cout << mas[i] << " "; } |
В основной части выполняются три операции: определение количества элементов в массиве, ввод этих элементов и вызов подпрограммы.
Подпрограмма состоит из алгоритма сортировки и цикла, выводящего результирующую упорядоченную последовательность. Алгоритм включает в себя классическую для многих алгоритмов сортировки структуру вложенных циклов. Количество итераций внешнего цикла не превышает n-1, где n – число элементов в массиве; внутренний цикл, начиная с шага i+1, заканчивает свое выполнение при j=0 (значение переменной-счетчика j уменьшается с каждым шагом на 1). Переменным k и tmp на i-ом шаге присваиваются значения, зависящие от шага и значения элемента массива mas на этом шаге. В переменной tmp храниться значение элемента массива mas[i+1], оно во внутреннем цикле сравнивается со значениями других элементов. Переменная k запоминает индекс элемента, который последним был больше tmp, и ему, по завершению работы внутреннего цикла, присваивается значение переменной tmp.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n) |
O(n2) |
O(n2) |
2.4 Быстрая сортировка
Выбирая алгоритм сортировки для практических целей, программист, вполне вероятно, остановиться на методе, называемом «Быстрая сортировка» (также «qsort» от англ. quick sort). Его разработал в 1960 году английский ученый Чарльз Хоар, занимавшийся тогда в МГУ машинным переводом.
Алгоритм, по принципу функционирования, входит в класс обменных сортировок, выделяясь при этом высокой скоростью работы.
Отличительной особенностью быстрой сортировки является операция разбиения массива на две части относительно опорного элемента. Например, если последовательность требуется упорядочить по возрастанию, то в левую часть будут помещены все элементы, значения которых меньше значения опорного элемента, а в правую элементы, чьи значения больше или равны опорному. Вне зависимости от того, какой элемент выбран в качестве опорного, массив будет отсортирован, но все же наиболее удачным считается ситуация, когда по обеим сторонам от опорного элемента оказывается примерно равное количество элементов. Если длина какой-то из получившихся в результате разбиения частей превышает один элемент, то для нее нужно рекурсивно выполнить упорядочивание, т. е. повторно запустить алгоритм на каждом из отрезков.
Таким образом, алгоритм быстрой сортировки включает в себя два основных этапа:
- разбиение массива относительно опорного элемента;
- рекурсивная сортировка каждой части массива.
Разбиение массива. Еще раз об опорном элементе. Его выбор не влияет на результат, и поэтому может пасть на произвольный элемент. Тем не менее, как было замечено выше, наибольшая эффективность алгоритма достигается при выборе опорного элемента, делящего последовательность на равные или примерно равные части. Но, как правило, из-за нехватки информации не представляется возможности наверняка определить такой элемент, поэтому зачастую приходиться выбирать опорный элемент случайным образом.
В следующих пунктах описана общая схема разбиения массива (сортировка по возрастанию):
- вводятся указатели frst и lst для обозначения начального и конечного элементов последовательности, а также опорный элемент mid;
- вычисляется значение опорного элемента (frst+lst)/2, и заноситься в переменную mid;
- указатель frst смещается с шагом в 1 элемент к концу массива до тех пор, пока Mas[frst]>mid. А указатель lst смещается от конца массива к его началу, пока Mas[lst]<mid;
- каждые два найденных элемента меняются местами;
- пункты 3 и 4 выполняются до тех пор, пока frst<lst.
После разбиения последовательности следует проверить условие на необходимость дальнейшего продолжения сортировки его частей. Этот этап будет рассмотрен позже, а сейчас на конкретном примере выполним разбиение массива.
Имеется массив целых чисел Mas [6 7 2 5 9 1 3 8], состоящий из 8 элементов Mas[1..8]. Начальным значением frst будет 1, а lst – 8.
В качестве опорного элемента возьмем элемент со значением 5, и индексом 4. Его мы вычислили, используя выражение (frst+lst)/2, отбросив дробную часть. Теперь mid=5.
Первый элемент левой части сравнивается с mid. Mas[1]>mid, следовательно frst остается равным 1. Далее, элементы правой части сравниваются с mid. Проверяется элемент с индексом 8 и значением 8. Mas[8]>mid, следовательно lst смещается на одну позицию влево. Mas[7]<mid, следовательно lst остается равным 7. На данный момент frst=1, а lst=7. Первый и седьмой элементы меняются местами. Оба указателя смещаются на одну позицию каждый в своем направлении - [3 7 2 5 9 1 6 8].
Алгоритм снова переходит к сравнению элементов. Второй элемент сравнивается с опорным: Mas[2]>mid, значит frst остается равным 2. Далее, элементы правой части сравниваются с mid. Проверяется элемент с индексом 6 и значением 1: Mas[6]<mid, значит lst не изменяет своей позиции. На данный момент frst=2, а lst=6. Второй и шестой элементы меняются местами. Оба указателя смещаются на одну позицию каждый в своем направлении – [3 1 2 5 9 7 6 8].
Алгоритм снова переходит к сравнению элементов. Третий элемент сравнивается с опорным: Mas[3]<mid, таким образом, frst смещается на одну позицию вправо. Далее, элементы правой части сравниваются с mid. Проверяется элемент с индексом 5 и значением 9: Mas[5]>mid, следовательно, lst смещается на одну позицию влево. Теперь frst=lst=4, а значит, условие frst<lst не выполняется, этап разбиения завершается –
[3 1 2 5 9 7 6 8].
На этом этап разбиения закончен. Массив разделен на две части относительно опорного элемента. Осталось произвести рекурсивное упорядочивание его частей.
Рекурсивная сортировка каждой части массива. Если в какой-то из получившихся в результате разбиения массива частей находиться больше одного элемента, то следует произвести рекурсивное упорядочивание этой части, то есть выполнить над ней операцию разбиения, описанную выше. Для проверки условия «количество элементов > 1», нужно действовать примерно по следующей схеме:
Имеется массив Mas[L..R], где L и R – индексы крайних элементов этого массива. По окончанию разбиения, указатели frst и lst оказались примерно в середине последовательности, тем самым образуя два отрезка: левый от L до lst и правый от frst до R. Выполнить рекурсивное упорядочивание левой части нужно в том случае, если выполняется условие L<lst. Для правой части условие аналогично: frst<R.
Код программы на C++:
|
const int n = 7; int frst, lst; void quicksort(int *mas, int frst, int lst) { int mid, count; int f = frst, l = lst; mid = mas[(f + l) / 2]; do { while (mas[f]<mid) f++; while (mas[l]>mid) l--; if (f <= l) { count = mas[f]; mas[f] = mas[l]; mas[l] = count; f++; l--; } } while (f<l); if (frst<l) quicksort(mas, frst, l); if (f<lst) quicksort(mas, f, lst); } |
Стоит отметить, что быстрая сортировка может оказаться малоэффективной на массивах, состоящих из небольшого числа элементов, поэтому при работе с ними разумнее отказаться от данного метода. В целом алгоритм неустойчив, а также использование рекурсии в неверно составленном коде может привести к переполнению стека. Но, несмотря на эти и некоторые другие минусы, быстрая сортировка все же является одним из самых эффективных и часто используемых методов.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n log n) |
O(n log n) |
O(n2) |
В 1959 году американский ученый Дональд Шелл опубликовал алгоритм сортировки, который впоследствии получил его имя – «Сортировка Шелла». Этот алгоритм может рассматриваться и как обобщение пузырьковой сортировки, так и сортировки вставками.
Идея метода заключается в сравнение разделенных на группы элементов последовательности, находящихся друг от друга на некотором расстоянии. Изначально это расстояние равно d или N/2, где N — общее число элементов. На первом шаге каждая группа включает в себя два элемента расположенных друг от друга на расстоянии N/2; они сравниваются между собой, и, в случае необходимости, меняются местами. На последующих шагах также происходят проверка и обмен, но расстояние d сокращается на d/2, и количество групп, соответственно, уменьшается. Постепенно расстояние между элементами уменьшается, и на d=1 проход по массиву происходит в последний раз.
Далее, на примере последовательности целых чисел, показан процесс сортировки массива методом Шелла (Рисунок 2). Для удобства и наглядности, элементы одной группы выделены одинаковым цветом.
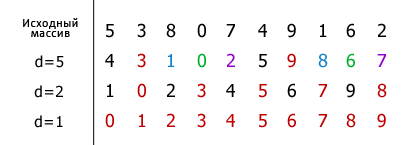
Рисунок 2
Первое значение, соответствующее расстоянию d равно 10/2=5. На каждом шаге оно уменьшается вдвое. Элементы, входящие в одну группу, сравниваются и если значение какого-либо элемента, стоящего левее того с которым он сравнивается, оказывается больше (сортировка по возрастанию), тогда они меняются местами. Так, элементы путем внутригрупповых перестановок постепенно становятся на свои позиции, и на последнем шаге (d=1) сортировка сводится к проходу по одной группе, включающей в себя все N элементов массива. При этом число требуемых обменов оказывается совсем небольшим.
Код на С++:
|
int i, j, n, d, cnt; void Shell(int A[], int n) { d = n; d = d / 2; while (d>0) { for (i = 0; i<n - d; i++) { j = i; while (j >= 0 && A[j]>A[j + d]) { cnt = A[j]; A[j] = A[j + d]; A[j + d] = cnt; j--; } } d = d / 2; } for (i = 0; i<n; i++) cout << A[i] << " "; } |
Сортировка Шелла уступает в эффективности быстрой сортировки, но выигрывает у сортировки вставками.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n log n) |
O(n2) |
Зависит от расстояния |
2.5 Шейкерная сортировка
Рассматриваемый алгоритм имеет несколько непохожих друг на друга названий. Среди них: сортировка перемешиванием, двунаправленная пузырьковая сортировка, шейкерная сортировка, пульсирующая сортировка (ripple sort), трансфертная сортировка (shuttle sort), и даже сортировка «счастливый час» (happy hour sort). Второй вариант (двунаправленная пузырьковая сортировка) наиболее точно описывает процесс работы алгоритма. Здесь, в его название, довольно-таки удачно включен термин «пузырьковая». Это действительно альтернативная версия известного метода, модификации в котором заключаются, по большей части, в реализации, упомянутой в названии, двунаправленности: алгоритм перемещается, ни как в обменной (пузырьковой) сортировке – строго снизу вверх (слева направо), а сначала снизу вверх, потом сверху вниз.
Перестановка элементов в шейкерной сортировке выполняется аналогично той же в пузырьковой сортировке, т. е. два соседних элемента, при необходимости, меняются местами. Пусть массив требуется упорядочить по возрастанию. Обозначим каждый пройденный путь от начала до конца последовательности через Wi, где i – номер пути; а обратный путь (от конца к началу) через -Wj, где j – номер пути. Тогда после выполнения Wi, один из неустановленных элементов будет помещен в позицию справа, как наибольший из еще неотсортированных элементов, а после выполнения -Wj, наименьший из неотсортированных, переместиться в некоторую позицию слева. Так, например, после выполнения W1 в конце массива окажется элемент, имеющий наибольшее значение, а после -W1 в начало отправиться элемент с наименьшим значением.
Анализируя метод пузырьковой сортировки можно отметить два обстоятельства.
- Если при движении по части массива перестановки не происходят, то эта часть массива уже отсортирована и, следовательно, ее можно исключить из рассмотрения.
- При движении от конца массива к началу минимальный элемент “всплывает” на первую позицию, а максимальный элемент сдвигается только на одну позицию вправо.
Эти две идеи приводят к следующим модификациям в методе пузырьковой сортировки. Границы рабочей части массива (т.е. части массива, где происходит движение) устанавливаются в месте последнего обмена на каждой итерации. Массив просматривается поочередно справа налево и слева направо.
Код на С++:
|
void Swap(int *Mas, int i) { int tmp; tmp = Mas[i]; Mas[i] = Mas[i - 1]; Mas[i - 1] = tmp; } void ShakerSrt(int *Mas, int Start, int N) { int L, R, i; L = Start; R = N - 1; while (L <= R) { for (i = R; i >= L; i--) if (Mas[i - 1]>Mas[i]) Swap(Mas, i); L++; for (i = L; i <= R; i++) if (Mas[i - 1]>Mas[i]) Swap(Mas, i); R--; } } |
Следующая таблица отражает временную сложность алгоритма шейкерной сортировки для трех случаев.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n) |
O(n2) |
O(n2) |
Приведенные временные показатели не позволяют рекомендовать алгоритм для использования его в практических целях. В обучении, ввиду своей относительной сложности, метод, несомненно, будет полезен.
2.6 Гномья сортировка
Гномья сортировка впервые была предложена 2 октября 2000 года Хамидом Сарбази-Азадом (Hamid Sarbazi-Azad). Он назвал ее «Глупая сортировка, простейший алгоритм сортировки всего с одним циклом…». И действительно, глупый этот метод или нет, но в нем задействован, никак в большинстве сортировок – два или более циклов, а только один.
Позже, голландский ученый Дик Грун, на страницах одной из своих книг, привел для гномьей сортировки следующую аналогию:
Гномья сортировка основана на технике, используемой обыкновенным голландским садовым гномом. Вот как садовый гном сортирует ряд цветочных горшков. По существу, он смотрит на два соседних цветочных горшка, если они находятся в правильном порядке, то он переходит на один горшок вперед, иначе он меняет их местами и возвращается на один горшок назад. Граничные условия: если позади нет ни одного горшка – он шагает вперед, а если нет следующего горшка, тогда он закончил.
Так описал основную идею алгоритма гномьей сортировки Дик Грун. Заменим гнома и горшки на более формальные объекты, например на указатель (номер текущего элемента) и элементы массива, и рассмотрим принцип работы алгоритма еще раз.
Вначале указатель ставиться на 1-ой элемент массива. Затем происходит сравнение двух соседних элементов A[i] и A[i-1], т. е. сравниваются первый элемент (i-1) и второй (i). Если те стоят на своих позициях, то сдвигаем указатель на позицию i+1 и продолжаем сравнение с нового положения. Иначе меняем элементы местами, и, поскольку в какой-то момент может оказаться, что элементы в левом подмассиве стоят не на своих местах, сдвигаем указатель на одну позицию влево, осуществляя следующее сравнение с новой позиции. Так алгоритм продолжает выполняться до тех пор, пока весь массив не будет упорядочен.
Здесь следует выделить два важных момента.
- процесс упорядочивания заканчивается, тогда когда не выполняется условие i<n, где n – размер массива
- как было сказано, указатель перемещается как вперед по списку, так и назад, и в том случае если он окажется над первым элементом, его сразу же следует сместить на одну позицию вправо, т. к. в противном случае придется сравнивать два элемента, одного из которых не существует.
Перейдем собственно к коду. На своем сайте Дик Грун выложил следующий листинг:
|
void gnomesort(int n, int ar[]) { int i = 0; while (i < n) { if (i == 0 || ar[i-1] <= ar[i]) i++; else {int tmp = ar[i]; ar[i] = ar[i-1]; ar[--i] = tmp;} } } |
Приведенный Груном код позволяет упорядочить массив, но все же он может быть немного улучшен. Оптимизация потребует небольшого редактирования, в частности, добавления одной вспомогательной переменной, что позволит избавиться от излишних сравнений.
Код на С++:
|
int n; void GnomeSrt(int i, int j, int *mas) { while (i<n) { if (mas[i - 1] <= mas[i]) { i = j; j++; } else { int t = mas[i]; mas[i] = mas[i - 1]; mas[i - 1] = t; i--; if (i == 0) { i = j; j++; } } } cout << "Отсортированный массив: "; for (i = 0; i<n; i++) cout << mas[i] << " "; } |
Кажется немного необычным, тот факт, что алгоритм сортировки использует всего один цикл. Плюс к этому, на практике гномья сортировка не уступает в скорости сортировки вставками.
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n2) |
O(n2) |
O(n2) |
2.7 Сортировка слиянием
Алгоритм сортировки слиянием был предложен праотцом современных компьютеров – Джоном фон Нейманом. Сам метод является устойчивым, т.е. он не меняет одинаковые по значению элементы в списке.
В основе сортировки слиянием лежит принцип «разделяй и властвуй». Список разделяется на равные или практически равные части, каждая из которых сортируется отдельно. После чего уже упорядоченные части сливаются воедино. Несколько детально этот процесс можно расписать так:
- Массив рекурсивно разбивается пополам, и каждая из половин делиться до тех пор, пока размер очередного подмассива не станет равным единице;
- Далее выполняется операция алгоритма, называемая слиянием. Два единичных массива сливаются в общий результирующий массив, при этом из каждого выбирается меньший элемент (сортировка по возрастанию) и записывается в свободную левую ячейку результирующего массива. После чего из двух результирующих массивов собирается третий общий отсортированный массив, и так далее. В случае если один из массивов закончиться, элементы другого дописываются в собираемый массив;
- В конце операции слияния, элементы перезаписываются из результирующего массива в исходный.
Основная подпрограмма MergeSort рекурсивно разбивает и сортирует массив, а Merge отвечает за его слияние. Эта подпрограмма выполняется только в том случае, если номер первого элемента меньше номера последнего. Перейдем к рассмотрению последней.
Работа Merge заключается в образовании упорядоченного результирующего массива путем слияния двух также отсортированных массивов меньших размеров.
Разберем алгоритм сортировки слиянием на следующем примере. Имеется неупорядоченная последовательность чисел: 2, 6, 7, 1, 3, 5, 0, 4. После разбивки данной последовательности на единичные массивы, процесс сортирующего слияния (по возрастанию) будет выглядеть так:

Рисунок 3
Массив был разделен на единичные массивы, которые алгоритм сливает попарно до тех пор, пока не получится один массив, все элементы которого стоят на своих позициях.
Код на С++:
|
void Merge(int *A, int frst, int lst) { int mid, start, final, j; int *mas = new int[100]; mid = (frst + lst) / 2; start = frst; final = mid + 1; for (j = frst; j <= lst; j++) if ((start <= mid) && ((final>lst) || (A[start]<A[final]))) { mas[j] = A[start]; start++; } else { mas[j] = A[final]; final++; } for (j = frst; j <= lst; j++) A[j] = mas[j]; delete[]mas; }; void MergeSort(int *A, int first, int last) { { if (first<last) { MergeSort(A, first, (first + last) / 2); MergeSort(A, (first + last) / 2 + 1, last); Merge(A, first, last); } } }; |
Недостатком сортировки слиянием является использование дополнительной памяти. Но когда работать приходиться с файлами или списками, доступ к которым осуществляется только последовательно, то очень удобно применять именно этот метод.
Также, к достоинствам алгоритма стоит отнести его устойчивость и неплохую скорость работы O(n*log n).
|
Лучший случай |
Средний случай |
Наихудший случай |
|
O(n*log n) |
O(n*log n) |
O(n*log n) |
Заключение
Тема, связанная с сортировкой данных богата и разнообразна в курсе информатики средней школы. Она вызывает интерес у учащихся, она содержит основы для компьютерного эксперимента и творчества молодых людей, она относится к обработке разного типа данных и, поэтому имеет огромное прикладное значение в различных сферах деятельности специалистов.
Конкретная методика изучения темы "Алгоритмы сортировки данных", как и вся методика преподавания информатики и программирования, зависит от многих параметров.
В работе изложен подход к изучению элементов сортировки, обращено внимание на особенности методических вопросов, возникающих на разных этапах обучения информатике при соприкосновением с сортировкой. Изучение темы сортировки не возможно без решения конкретных задач, данная работа сопровождается алгоритмами.
Тема сортировки неисчерпаема, на нее еще много раз будут обращать свое внимание специалисты из разных областей человеческой деятельности.
Казалось бы, к чему плодить много алгоритмов, давайте найдем один, самый оптимальный и успокоимся на этом. Это ошибочное мнение. Найти оптимальный алгоритм, не привязываясь при его выборе к условию задачи - это иллюзия.
В данном курсовом проекте при разработке программы были закреплены навыки объектно-ориентированного программирования на языке С++.
В приложении представлен код программы на языке С++, в которой пользователь может использовать любой вариант сортировки данных, представленных в данном курсовом проекте.
Библиография
- Дональд Э.Кнут. Искусство программирования, т.3. Сортировка и поиск 2-е изд.: – М.: Издательский дом «Вильямс», 2001. С. 824.
- Седжвик Роберт. Фундаментальные алгоритмы на С++. Анализ/Структуры данных/Сортировка/Поиск: Пер. с англ./Роберт Седжвик. - СПб.: ООО "ДиаСофтЮП", 2002.-688с
- Кормен Т., Лейзерсон Ч.И., Ривест Р.Л., Клиффорд Штайн Алгоритмы: построение и анализ. — 2-е изд. — М.: «Вильямс», 2006. — С. 1296.
- Кнут Д. Искусство программирования для ЭВМ. Т. 3. Сортировка и поиск. - М.: Мир, 1978.
- Златопольский Д.М. Методы сортировки массивов. - Информатика и образование, 1997, № 10,11,14,16,19,21,22.
- Шолмов Л.И. Руководство по турбо Си. М.: Наука, 1994. - 94-98с.
- Уинер Р. Язык Турбо Си: Пер. с англ. - М.: Мир, 1991. - 384 с.
- Керниган Б.В, Ричи Д. Си для профессионалов. М.: Энергия, 1996. -213 с.
- Грейд Д. Математическое программирование. М.: Наука, 1987.- 241 с.
- Либерман М. Алгоритмы сортировки массивов. М.: Наука, 1997. - 43-81с.
Приложение
Код основной программы на С++
#include "stdafx.h"
#include <iostream>
#include <ctime>
using namespace std;
int i, j, n, d, cnt, k = 0, tmp = 0, frst, lst;
const int nQS = 7;
void SelectionSort(int A[], int n1)
{
int count, k;
for (i = 0; i<n1 - 1; i++)
{
count = A[i]; k = i;
for (j = i + 1; j<n1; j++)
if (A[j]<A[k]) k = j;
if (k != i)
{
A[i] = A[k];
A[k] = count;
}
}
cout << "Отсортированный массив: ";
for (i = 0; i<n1; i++) cout << A[i] << " ";
}
void mainSelection()
{
setlocale(LC_ALL, "Rus");
int n1, A[1000];
cout << "Введите количество элементов -"; cin >> n1;
for (i = 0; i<n1; i++)
{
cout << " элемент № " << i + 1; cin >> A[i];
}
SelectionSort(A, n1);
system("pause >> void");
system("cls");
}
void BSort(int A[], int N)
{
for (i = 0; i<N - 1; i++)
{
for (j = 0; j<N - (i + 1); j++)
{
k = j + 1;
cnt = A[k];
if (A[j]>A[k])
{
A[k] = A[j];
A[j] = cnt;
}
}
}
cout << "Отсортированный массив: ";
for (i = 0; i<N; i++) cout << A[i] << " ";
}
void mainBSort()
{
setlocale(LC_ALL, "Rus");
int n; int A[1000];
cout << "Введите количество элементов - "; cin >> n;
for (i = 0; i<n; i++)
{
cout << " элемент № " << i + 1; cin >> A[i];
}
BSort(A, n);
system("pause >> void");
system("cls");
}
void InsertSort(int *mas, int n)
{
for (i = 0; i<n - 1; i++)
{
k = i + 1;
tmp = mas[k];
for (j = i + 1; j>0; j--)
{
if (tmp<mas[j - 1])
{
mas[j] = mas[j - 1];
k = j - 1;
}
}
mas[k] = tmp;
}
cout << endl << "Отсортированный массив: ";
for (i = 0; i<n; i++)
cout << mas[i] << " ";
}
void mainInsert()
{
setlocale(LC_ALL, "Rus");
int n;
cout << "Количество элементов в массиве - "; cin >> n;
int *mas = new int[n];
for (i = 0; i<n; i++)
{
cout << " элемент № " << i + 1; cin >> mas[i];
}
InsertSort(mas, n);
delete[] mas;
system("pause >> void");
system("cls");
}
void quicksort(int *mas, int frst, int lst)
{
int mid, count;
int f = frst, l = lst; mid = mas[(f + l) / 2];
do
{
while (mas[f]<mid) f++;
while (mas[l]>mid) l--;
if (f <= l)
{
count = mas[f];
mas[f] = mas[l];
mas[l] = count;
f++;
l--;
}
} while (f<l);
if (frst<l) quicksort(mas, frst, l);
if (f<lst) quicksort(mas, f, lst);
}
void mainQuick()
{
setlocale(LC_ALL, "Rus");
int *A = new int[nQS];
srand(time(NULL));
cout << "Исходный массив: ";
for (int i = 0; i<nQS; i++)
{
A[i] = rand() % 10;
cout << A[i] << " ";
}
frst = 0; lst = nQS - 1;
quicksort(A, frst, lst);
cout << endl << "Отсортированный массив: ";
for (int i = 0; i<nQS; i++) cout << A[i] << " ";
delete[]A;
system("pause >> void");
system("cls");
}
void Shell(int A[], int n)
{
d = n;
d = d / 2;
while (d>0)
{
for (i = 0; i<n - d; i++)
{
j = i;
while (j >= 0 && A[j]>A[j + d])
{
cnt = A[j];
A[j] = A[j + d];
A[j + d] = cnt;
j--;
}
}
d = d / 2;
}
for (i = 0; i<n; i++) cout << A[i] << " ";
}
void mainShell()
{
setlocale(LC_ALL, "Rus");
cout << "Размер массива - "; cin >> n;
int *A = new int[n];
for (i = 0; i<n; i++)
{
cout << " элемент № " << i + 1; cin >> A[i];
}
cout << "\nОтсортированный массив: ";
Shell(A, n);
delete[] A;
system("pause >> void");
system("cls");
}
void Swap(int *Mas, int i)
{
int tmp;
tmp = Mas[i];
Mas[i] = Mas[i - 1];
Mas[i - 1] = tmp;
}
void ShakerSrt(int *Mas, int Start, int N)
{
int L, R, i;
L = Start;
R = N - 1;
while (L <= R)
{
for (i = R; i >= L; i--)
if (Mas[i - 1]>Mas[i]) Swap(Mas, i);
L++;
for (i = L; i <= R; i++)
if (Mas[i - 1]>Mas[i]) Swap(Mas, i);
R--;
}
}
void mainShaker()
{
setlocale(LC_ALL, "Rus");
int n, k;
cout << "Размер массива - "; cin >> n;
int *A = new int[n];
for (k = 0; k<n; k++)
{
cout << " элемент № " << i + 1; cin >> A[k];
}
ShakerSrt(A, 1, n);
cout << "Отсортироанный массив: ";
for (k = 0; k<n; k++)cout << " " << A[k];
system("pause >> void");
system("cls");
}
void GnomeSrt(int i, int j, int *mas)
{
while (i<n)
{
if (mas[i - 1] <= mas[i]) { i = j; j++; }
else
{
int t = mas[i];
mas[i] = mas[i - 1]; mas[i - 1] = t;
i--;
if (i == 0) { i = j; j++; }
}
}
cout << "Отсортированный массив: ";
for (i = 0; i<n; i++)
cout << mas[i] << " ";
}
void mainGnome()
{
setlocale(LC_ALL, "Rus");
int m, k;
cout << "Размер массива - "; cin >> n;
int *a = new int[n];
for (k = 0; k<n; k++)
{
cout << " элемент № " << i + 1; cin >> a[k];
}
k = 1; m = 2;
GnomeSrt(k, m, a);
delete[]a;
system("pause >> void");
system("cls");
}
void Merge(int *A, int frst, int lst)
{
int mid, start, final, j;
int *mas = new int[100];
mid = (frst + lst) / 2;
start = frst;
final = mid + 1;
for (j = frst; j <= lst; j++)
if ((start <= mid) && ((final>lst) || (A[start]<A[final])))
{
mas[j] = A[start];
start++;
}
else
{
mas[j] = A[final];
final++;
}
for (j = frst; j <= lst; j++) A[j] = mas[j];
delete[]mas;
};
void MergeSort(int *A, int first, int last)
{
{
if (first<last)
{
MergeSort(A, first, (first + last) / 2);
MergeSort(A, (first + last) / 2 + 1, last);
Merge(A, first, last);
}
}
};
void mainMerge()
{
setlocale(LC_ALL, "Rus");
int i, n;
int *A = new int[100];
cout << "Размер массива - "; cin >> n;
for (i = 1; i <= n; i++)
{
cout << " элемент № " << i + 1; cin >> A[i];
}
MergeSort(A, 1, n);
cout << "Упорядоченный массив: ";
for (i = 1; i <= n; i++) cout << A[i] << " ";
delete[]A;
system("pause >> void");
system("cls");
}
int _tmain(int argc, _TCHAR* argv[])
{
setlocale(LC_ALL, "Rus");
int s;
cout << "1. Сортировка выбором\n2. Сортировка пузырьком\n3. Сортировка вставками\n4. Быстрая сортировка(Случайный массив)\n5. Сортировка Шелла\n6. Шейкерная сортировка\n7. Гномья сортировка\n8. Сортировка слиянием\n";
cout << "\nДля выхода введите 9!\n";
cout << "Выберите сортировку:"; cin >> s;
switch (s)
{
case 1:
system("cls");
mainSelection();
_tmain(argc, argv);
case 2:
system("cls");
mainBSort();
_tmain(argc, argv);
case 3:
system("cls");
mainInsert();
_tmain(argc, argv);
case 4:
system("cls");
mainQuick();
_tmain(argc, argv);
case 5:
system("cls");
mainShell();
_tmain(argc, argv);
case 6:
system("cls");
mainShaker();
_tmain(argc, argv);
case 7:
system("cls");
mainGnome();
_tmain(argc, argv);
case 8:
system("cls");
mainMerge();
_tmain(argc, argv);
case 9:
break;
default:
cout << "\nОшибка! Попробуйте еще раз!\n";
system("pause");
system("cls");
_tmain(argc, argv);
return 0; } }

- Проектирование реализации операций бизнес-процесса
- Проектирование организации (суши-бар «Такара»)
- МВФ: цели, функции, особенности
- Национальная, Мировая и региональная
- «Понятие предпринимательского договора
- Особенности функционирования мирового финансового рынка
- Разработка концепции проекта по реинженирингу организации.(Обоснование проекта)
- Первичные документы для целей налогового учета)
- Первичные документы для целей налогового учета
- Составляющие налогового учета и его документальное оформление
- ФИНАНСЫ КАК ИНСТРУМЕНТ РЕГУЛИРОВАНИЯ ЭКОНОМИКИ (СОВРЕМЕННЫЕ ПРОБЛЕМЫ И НАПРАВЛЕНИЯ ФИНАНСОВОГО РЕГУЛИРОВАНИЯ ЭКОНОМИКИ В РФ)
- Сетевая форма организации бизнеса (Анализ деятельности сетевой компании)