
Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования (Свойства и классификация)
Содержание:

Введение
Современные тенденции по развитию информационных технологий предполагают увеличение количества обрабатываемой информации. Стоит обратить внимание на то, что в основном удобно хранить или использовать данные, упорядоченные по одному или нескольким критериям. Процесс упорядочивания данных называется сортировкой.
Алгоритмы сортировок начинают появляться сразу после появления алгоритмов программирования высоко уровня. Тем не менее само понятие сортировки существовало и ранее: в конце 19ого века в США была создана первая перфокарточная машина, задачей которой было проведение сортировки данных, полученных в результате переписи населения. Тем не менее, в данной работе будут рассмотрены только компьютерные методы сортировки.
Заметим, что существует огромное множество алгоритмов сортировки и очень важно понимать их специфику для того, чтобы выбрать наиболее оптимальный алгоритм сортировки. При выборе метода сортировки стоит обратить внимание на объем и критерии сортировки, а также на специфику обрабатываемых данных.
Для большинства существующих языков программирования есть встроенные в них, или оформленные в виде подключаемой библиотеки, методы сортировки. Например, для языка С++ была реализована быстрая сортировка. То есть для большинства задач не требуется написания своего алгоритма сортировки, вместо этого можно использовать встроенные алгоритмы. Однако, в ряде случаев эти алгоритмы могут быть или слишком затратными по времени выполнения, или по другим параметрам. Например, в ряде случаев объемы сортируемых данных настолько велики, что не помещаются в оперативную память и требуют специальных механизмов сортировки.
Целью данной работы является анализ существующих методов сортировки. В рамках заданной цели были выделены следующие задачи:
- Анализ эволюции методов сортировки.
- Проведение классификации и сравнения методов сортировки.
- Подробное изучение и реализация некоторых алгоритмов на языке С++.
Глава 1. Эволюция и сравнение методов сортировки
В середине 1950-х годов с разработкой ЭВМ второго поколения началось активное развитие алгоритмов сортировки. Основными предпосылками для этого стали, во-первых, значительное упрощение и ускорение написания программ для компьютеров в результате разработки первых языков программирования высокого уровня (Фортран, Алгол, Кобол); во-вторых, значительное повышение доступности компьютеров в результате резкого уменьшения их габаритов и стоимости и, как следствие, достаточно широкое их распространение; в-третьих, увеличение производительности компьютеров до 30 тысяч операций в секунду.
В 1959 году Дональд Левис Шелл (Donald Lewis Shell) предложил метод сортировки с убывающим шагом (shellsort), в 1960 году Чарльз Энтони Ричард Хоар (Charles Antony Richard Hoare) — метод быстрой сортировки (quicksort), в 1964 году Дж. У. Дж. Уильямс (J. V. J. Williams) — метод пирамидальной сортировки (heapsort). Многие из разработанных в этот период алгоритмов (например, быстрая сортировка Хоара) широко используются до настоящего времени [3].
В целом, к началу 1970-х годов использовались следующие виды алгоритмов внутренней сортировки: сортировка посредством подсчета; сортировка путем вставок; обменная сортировка; сортировка посредством выбора; сортировка методом слияния; сортировка методом распределения.
Большинство методов использовали алгоритмы вставок, обменов или выбора для внутренних сортировок. Но не всегда объемы данных позволяли использовать внутреннюю сортировку, что привело к развитию алгоритмов внешних сортировок, позволяющих сортировать данные лишь частично подгруженные в оперативную память [4].
Очередной всплеск интереса к алгоритмам сортировки произошел в середине 1970-х годов, когда элементной базой компьютеров стали большие интегральные схемы и появилась возможность объединения мощности вычислительных машин путем создания единых вычислительных центров, позволяющих работать с разделением времени. В период с середины 1970-х до 1990-х годов были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. К примеру, нидерландский учёный Эдсгер Вибе Дейкстра (Edsger Wybe Dijkstra) в 1981 году предложил алгоритм плавной сортировки (Smoothsort), который является развитием пирамидальной сортировки (Heapsort).
Следующее направление исследований были направлены на сокращение времени работ алгоритмов сортировки. В частности, для этого стали использовать параллельные алгоритмы, как разработанные на основе существующих алгоритмов сортировки, так и совершенно новые, специально приспособленные к разделению на потоки. Развитие данного направления стимулировалось и все более широким использованием сортирующих сетей, а также многомерных вычислительных решеток. Современные алгоритмы сортировки используются повсеместно для сортировки больших объемов данных. Появились специальные возможности для работы с такими данными. Сортируются не только данные в рамках специальных алгоритмов, но и так же хранящиеся в базах данных.
В своих работах Дупленко А. Г выделил пять этапов развития процесса сортировки [6].
Первый этап начался в 1870 году и длился до начала 1940-х годов. В это время появляются первые механизмы машинной сортировки данных, однако они основаны на простых перфокарточных машинах.
Второй этап — с начала 1940-х годов до середины 1950-х. Этот этап характеризуется появлением первых ЭВМ и соответственно первых алгоритмов сортировки для этих ЭВМ. Появилась классификация сортировок на внешние и внутренние. Наиболее распространенными в этот период были модификации сортировки слиянием и вставками сложности O (n log n).
Третий этап начался в середине 1950-х годов и продолжался до середины 1970-х. Этот этап характеризуется появлением первых языков программирования высокого уровня. Появляется большое количество алгоритмов сортировки для этих языков программирования, появляется классификация этих алгоритмов на устойчивые и неустойчивые. Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок, обменной сортировке и сортировке посредством выбора.
Четвертый этап продолжался с середины 1970-х до середины 1990-х годов. Появляются первые вычислительные центры с объединенными в сети персональными компьютерами, что дало возможность использовать сразу несколько процессоров для решения одной задачи. Появляются первые распределённые алгоритмы. Одновременно происходил поиск оптимальных входных последовательностей для разных методов сортировки, что позволяло значительно сократить ее время.
Пятый этап начался с середины 1990-х годов и продолжается по настоящее время. Он характеризуется использованием параллельных алгоритмов, а же сортировочных сетей для достижения максимально быстрых результатов. Актуальность данных методов поддерживается за счет современного развития науки и техники, позволяющего создавать современные многоядерные процессоры и быстрые способы обмена информацией по сети.
Таким образом, прослеживаются основные тенденции развития алгоритмов сортировки: уменьшение времени работы алгоритма за счет совершенствования самого алгоритма, или использования параллельных алгоритмов. Совершенствование алгоритмов достигается в том числе и за счет обнаружения частично упорядоченных подмножеств в множестве использованных данных. Работа алгоритмов также ускоряется за счёт появления мощных дата центров.
1.1 Свойства и классификация
- Устойчивость (англ. stability) — устойчивая сортировка не меняет взаимного расположения элементов с одинаковыми ключами.
- Естественность поведения — эффективность метода при обработке уже упорядоченных или частично упорядоченных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
- Использование операции сравнения. Алгоритмы, использующие для сортировки сравнение элементов между собой, называются основанными на сравнениях. Минимальная трудоемкость худшего случая для этих алгоритмов составляет O(n log n), но они отличаются гибкостью применения. Для специальных случаев (типов данных) существуют более эффективные алгоритмы.
По сфере применения сортировки делят на следующие группы:
- Внутренняя сортировка оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат.
- Внешняя сортировка оперирует запоминающими устройствами большого объёма, но не с произвольным доступом, а последовательным (упорядочение файлов), т. е. в данный момент «виден» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам упорядочения, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным во внешней памяти производится намного медленнее, чем операции с оперативной памятью.
- Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
- Объём данных не позволяет им разместиться в ОЗУ. Также алгоритмы классифицируются по:
- потребности в дополнительной памяти или её отсутствию
- потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, или отсутствию таковой
Одним из основных критичных ресурсов является время выполнения алгоритма. Оценим время выполнения нескольких сортировок, рассмотрев их поподробнее. Время выполнения будем рассматривать как функцию временной сложности алгоритма, зависящую от размера входных данных n.
Рассмотрим основные сортировки:
Сортировка выбором (Selection sort). Может быть реализован и как устойчивый, и как неустойчивый алгоритм. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае О(n2), предполагая, что сравнения делаются за постоянное время.
Наихудший случай:
- Число сравнений в теле цикла равно (N-1)*N/2.
- Число сравнений в заголовках циклов (N-1)*N/2.
- Число сравнений перед операцией обмена N-1.
- Суммарное число сравнений N2−1.
- Число обменов N-1.
Сортировка простыми обменами, сортировка пузырьком (bubble sort). Сложность алгоритма: O(n²).
Наихудший случай:
- Число сравнений в теле цикла равно (N-1)*N/2.
- Число сравнений в заголовках циклов (N-1)*N/2.
- Суммарное число сравнений равно (N-1)*N.
- Число присваиваний в заголовках циклов равно (N-1)*N/2.
- Число обменов равно (N-1)*N/2.
Наилучший случай:
- Число сравнений в теле цикла равно (N-1).
- Число сравнений в заголовках циклов (N-1).
- Суммарное число сравнений равно 2*(N-1).
- Число обменов равно 0.
Быстрая сортировка (англ. quicksort), часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром в МГУ в 1960 году. Один из быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов), хотя и имеющий ряд недостатков.
Наихудший случай:
- Число разбиений: N.
- Сложность алгоритма: O(N2).
Поскольку в каждой итерации (на каждом следующем уровне рекурсии) длина обрабатываемого отрезка массива уменьшается, по меньшей мере, на единицу, терминальная ветвь рекурсии будет достигнута всегда и обработка гарантированно завершится.
Лучше всего время выполнения сортировок представляются на следующих таблицах. В них указываются результаты проведения экспериментальных вычислений, в которых сортировались одинаковые наборы данных с помощью разных сортировок. Так как данные были использованы одни и те же, а также эксперимент проводился на одном и том же оборудовании, то приведенные данные могут характеризовать время выполнения алгоритмов.
В приведенных таблицах используются следующие сортировки:
- Selection sort – сортировка выбором.
- Bubble sort – сортировка пузырьком.
- Insertion sort – сортировка вставками.
- Quick sort – быстрая сортировка.
Полностью неотсортированный массив:
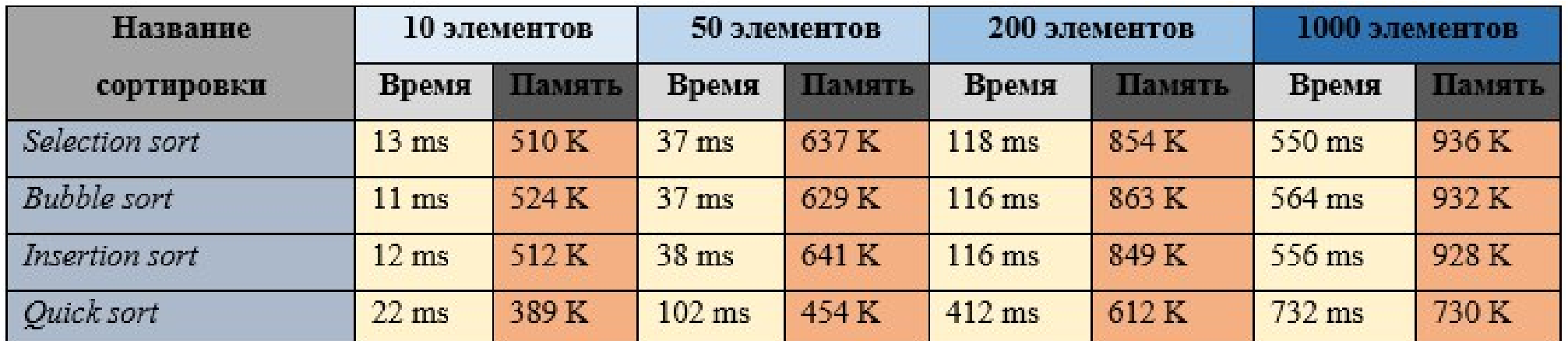
Рисунок 1. Результат эксперимента.
Частично отсортированный массив (половина элементов упорядочена):
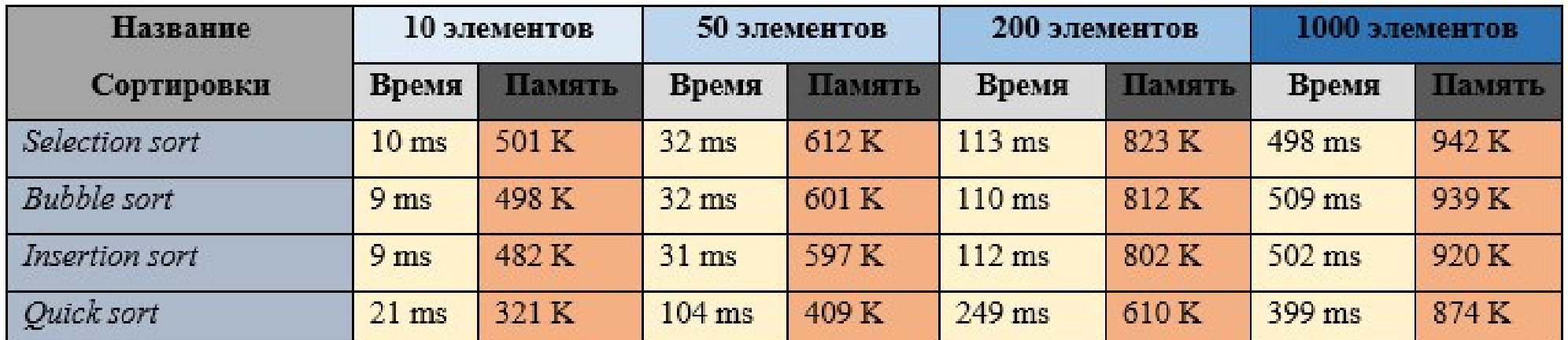
Рисунок 2. Результат эксперимента.
Таким образом, видно, что самым эффективным по времени алгоритмом является быстрая сортировка. Заметим, что реальный выигрыш во времени будет заметен только при больших объемах данных, если объем данных небольшой, то время выполнения всех алгоритмов будет схожее.
При этом реализация быстрой сортировки сложнее, чем другие представленные сортировки. Теоретически для небольших объемов данных можно выбирать более простые сортировки, так как для их написания требуется меньше времени. Однако, так как быстрая сортировка встроена, например, в язык программирования С++, то следует заметить, что быстрее будет использовать готовый алгоритм сортировки. Особенно при условии, что он эффективен и по занимаемой памяти, и по времени выполнения.
Глава 2. Примеры сортировок
2.1 Простой обмен (метод пузырька)
В простейшем случае задача сортировки заключается в следующем: задан список целых чисел (простейший случай) В={K1, K2,..., Kn}. Требуется переставить элементы списка В так, чтобы получить упорядоченный список B'={K'1, K'2,...,K'n}, в котором для любого 1<=i<=n элемент K'i <= K'i+1.
Основной принцип пузырьковой сортировки - систематический обмен соседних элементов с неправильным порядком при просмотре всего списка слева направо. При этом максимальные элементы «выталкиваются», «всплывают» в конце списка. Если сравнить сортируемые элементы с пузырьками воздуха в воде, то возникает аналогия – максимальные значения «всплывают» на поверхность подобно пузырькам воздуха. Благодаря такой аналогии сортировка простым обменом получила название пузырьковой сортировки.
Работа алгоритма пузырьковой сортировки происходит по следующим шагам:
- Сравниваются 2 соседних элемента. Если они не являются упорядоченными, то происходит их обмен.
- Происходит переход к следующей паре элементов до тех пор, пока не дойдем до конца массива.
- Алгоритм совершает n-1 проходов по массиву, где n – количество элементов массива.
Пример: пусть задан исходный список B=<20,-5,10,8,7>. В результате «первого прохода» алгоритма число 20 переместится в конец списка:
|
Первый проход |
-5 20 10 8 7 |
|
-5 10 20 8 7 |
|
|
-5 10 8 20 7 |
|
|
-5 10 8 7 20 |
|
|
Второй проход |
-5 10 8 7 20 |
|
-5 8 10 7 20 |
|
|
-5 8 7 10 20 |
|
|
Третий проход |
-5 8 7 10 20 |
|
-5 7 8 10 20 |
|
|
Четвертый проход |
-5 7 8 10 20 |
Таблица 1. Пример работы сортировки пузырьком.
Блок-схема алгоритма пузырьковой сортировки выглядит следующим образом:
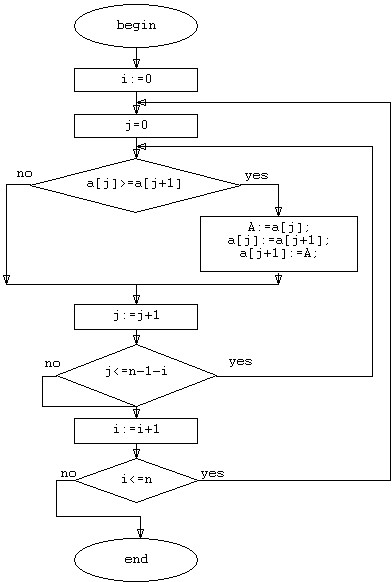
Рисунок 3. Блок-схема сортировки пузырьком.
Приведем код сортировки на языке С++:
#define SWAP(A, B) { int t = A; A = B; B = t; } // зададим функцию обмена
void bubblesort(int *a, int n) //сортировка пузырьком
{ int j, nn;
do {
nn = 0;
for (j = 1; j < n; ++j)
if (a[j - 1] > a[j]) {// если 2 соседних элемента не упорядочены
SWAP(a[j - 1], a[j]); // меняем их местами nn = j;
}
n = nn;
} while (n);
}
2.2 Простой выбор
Это наиболее естественный алгоритм упорядочивания. Допустим, что элементы K0 , ..., Ki-1 уже упорядочены, тогда среди оставшихся Ki , ..., Kn1 находим минимальный элемент и меняем его местами с i-тым элементом. И так далее, пока массив не будет полностью упорядочен. То есть сортировка выбором состоит в разделении исходного массива на две части, отсортированную и не отсортированную. Изначально отсортированная часть пуста. На каждой итерации алгоритма в неотсортированной части находится наименьший элемент, после чего он обменивается местами с первым элементом неотсортированой части, и этот первый элемент присоединяется к отсортированной части массива.
Пример: пусть задан исходный список B=<4,17,25,1,21,13,2>.
|
Первый проход |
1 17 25 4 21 13 2 |
|
Второй проход |
1 2 25 4 21 13 17 |
|
Третий проход |
1 2 4 25 21 13 17 |
|
Четвертый проход |
1 2 4 13 21 25 17 |
|
Пятый проход |
1 2 4 13 17 25 21 |
|
Шестой проход |
1 2 4 13 17 21 25 |
Таблица 2. Пример работы сортировки простым выбором.
Блок-схема алгоритма сортировки простым выбором выглядит следующим образом:
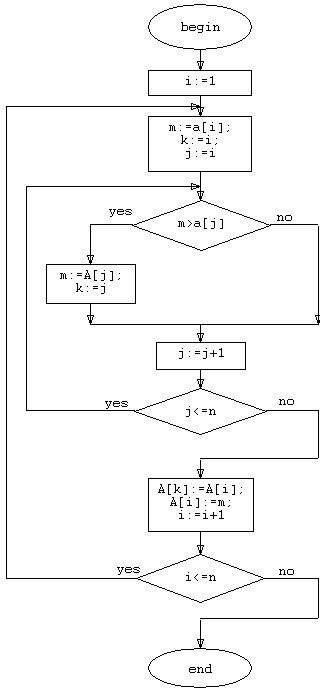
Рисунок 4. Блок-схема сортировки простым выбором.
Приведем код сортировки на языке С++:
void insertionSort(int *arrayPtr, int length) // сортировка вставками
{
int temp, // временная переменная для хранения значения элемента сортируемого
массива item; // индекс предыдущего элемента for (int counter = 1; counter < length; counter++) {
temp = arrayPtr[counter]; // инициализируем временную переменную текущим
значением элемента массива item = counter - 1; // запоминаем индекс предыдущего элемента массива while (item >= 0 && arrayPtr[item] > temp) // пока индекс не равен 0 и
предыдущий элемент массива больше текущего
|
{ |
||
|
массива |
arrayPtr[item + 1] = arrayPtr[item]; // перестановка элементов |
|
|
arrayPtr[item] = temp; |
||
|
item--; |
||
|
} } |
} |
|
2.3 Сортировка вставкой
Пусть 1 < j ≤ N и записи R1, ..., Rj-1 уже размещены так, что K1 ≤ K2 ≤...≤ Kj-1. Будем сравнивать по очереди Kj с Kj-1, Kj-2, ..., K1 до тех пор, пока не обнаружим, что запись Rj следует вставить между Ri, и Ri+1. Тогда подвинем записи Ri+1, ... Rj-1 на одно место вверх и поместим новую запись в позицию i+1.
Сортировка вставками основана на том, что она сортирует список, формируя его заново – вставляя очередной элемент в нужное место уже отсортированного списка.
Пример: пусть задан исходный список B=<4,17,25,1,21,13,2>.
|
Первый проход |
4 17 25 1 21 13 2 |
|
Второй проход |
4 17 25 1 21 13 2 |
|
Третий проход |
1 4 17 25 21 13 2 |
|
Четвертый проход |
1 4 17 21 25 13 2 |
|
Пятый проход |
1 4 13 17 21 25 2 |
|
Шестой проход |
1 2 4 13 17 21 25 |
Таблица 3. Пример работы сортировки вставками.
Блок-схема алгоритма сортировки простым выбором выглядит следующим образом:
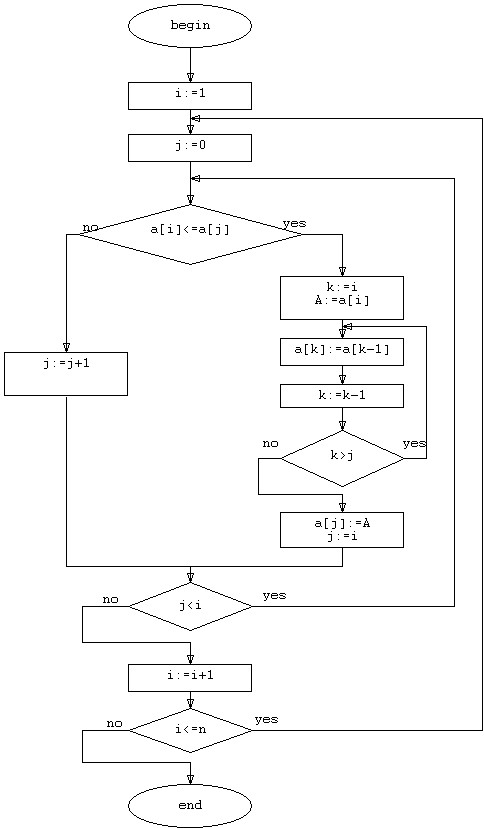
Рисунок 5. Блок-схема сортировки вставками.
Приведем код сортировки на языке С++:
void insertionSort(int *arrayPtr, int length) // сортировка вставками
{
int temp, // временная переменная для хранения значения элемента сортируемого
массива item; // индекс предыдущего элемента
for (int counter = 1; counter < length; counter++)
{
temp = arrayPtr[counter]; // инициализируем временную переменную текущим
значением элемента массива item = counter - 1; // запоминаем индекс предыдущего элемента массива while (item >= 0 && arrayPtr[item] > temp) // пока индекс не равен 0 и
предыдущий элемент массива больше текущего
|
{ |
||
|
массива |
arrayPtr[item + 1] = arrayPtr[item]; // перестановка элементов |
|
|
arrayPtr[item] = temp; |
||
|
item--; |
||
|
} |
} |
} |
2.4 Сортировка методом Шелла
Сортировка Шелла является усовершенствованным методом алгоритма сортировки простыми вставками. Характерным для данного метода является то, что сначала рассматриваются отдаленные, а затем близко расположенные элементы. Каждый проход в этом случае характеризуется некоторым смещением h для сортируемых элементов – это интервал, который разделяет сравниваемые элементы. Другими словами, каждый элемент отстоит от предыдущего на h позиций. Затем расстояние между сортируемыми элементами уменьшается. Для h часто используют последовательность 8,4,2,1. Однако это не единственно возможный вариант. Таким образом, единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.[8,9]
В качестве примера рассмотрим алгоритм сортировки массива a[0].. a[15].
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
Таблица 4. Исходный массив для сортировки Шелла.
Сначала сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
||||||||||||||
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
||||||||||||||
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
||||||||||||||
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
||||||||||||||
|
2 |
5 |
2 |
7 |
2 |
1 |
3 |
5 |
1 |
2 |
||||||||||||||
|
Таблица 4. Первый этап обработки данных. В результате получаем: |
|||||||||||||||||||||||
|
5 |
2 |
7 |
2 |
1 |
2 |
3 |
5 |
1 |
2 |
||||||||||||||
Таблица 5. Результат первого этапа.
Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]).
|
5 |
2 |
7 |
2 |
1 |
2 |
3 |
5 |
1 |
2 |
||||||
|
5 |
2 |
7 |
2 |
1 |
2 |
3 |
5 |
1 |
2 |
||||||
|
5 |
2 |
7 |
2 |
1 |
2 |
3 |
5 |
1 |
2 |
||||||
|
5 |
2 |
7 |
2 |
1 |
2 |
3 |
5 |
1 |
2 |
Таблица 6. Второй этап обработки данных.
В результате получаем:
|
2 |
5 |
1 |
1 |
2 |
2 |
5 |
2 |
7 |
3 |
Таблица 7. Результат второго этапа.
Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).
|
2 |
5 |
1 |
1 |
2 |
2 |
5 |
2 |
7 |
3 |
||||||
|
2 |
5 |
1 |
1 |
2 |
2 |
5 |
2 |
7 |
3 |
Таблица 8. Третий этап обработки данных.
В результате получаем:
|
1 |
5 |
2 |
2 |
2 |
1 |
5 |
2 |
7 |
3 |
||||||
|
Таблица 9. Результат третьего этапа. На последнем шаге сортируем вставками все 16 элементов: |
|||||||||||||||
|
1 |
2 |
2 |
5 |
2 |
1 |
2 |
3 |
5 |
7 |
||||||
Таблица 10. Итоговый результат сортировки Шелла.
Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Но на самом деле предыдущие проходы продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. Последовательность и так почти отсортирована. Ускорение подтверждено многочисленными исследованиями и на практике оказывается довольно существенным.
Блок-схема алгоритма сортировки простым выбором выглядит следующим образом:
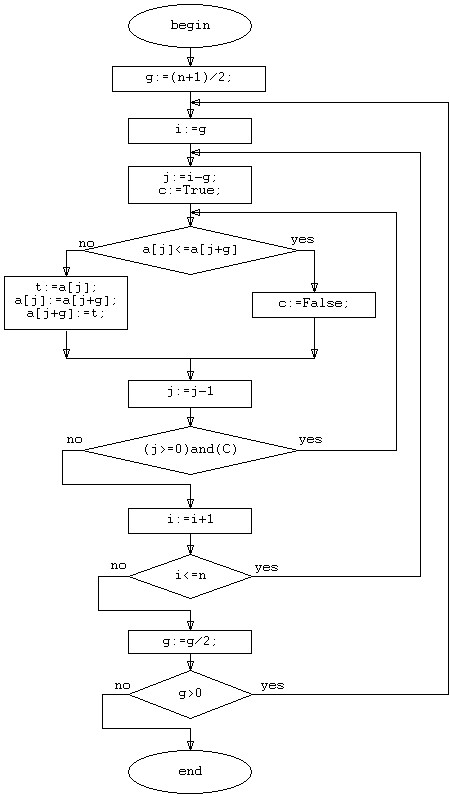
Рисунок 6. Блок-схема сортировки Шелла.
Приведем код сортировки на языке С++:
void ShellSort(int array[], int size) // * ∆k = (b∆k−1)/2 ∆0 = N
{
int step, i, j, temp;
for (step = size / 2; step > 0; step /= 2) { // разбиение на шаг for (i = step; i < size; i++) { // кол-во пар, которые надо
проверить for (j = 0; j < i; j++) { // проверка каждой пары if (array[j] > array[i]) { // если первое число в
паре больше второго, то поменять местами
temp = array[j]; array[j] = array[i];
array[i] = temp;
}
}
}
}
}
2.5 Быстрая сортировка
Шаги алгоритма:
- В алгоритме выбирается опорный элемент - некоторый элемент массива, относительно которого будет происходить разделение массива на части. Теоретически, то может быть любой элемент массива. Существуют разные стратегии выбора опорного элемента – например каждый раз выбирать средний элемент, или последний.
- Массив разделяется на 2 части – в одну часть идут все элементы меньшие или равные опорного, в другу часть все элементы большие опорного.
- Далее каждую из получившихся частей подвергаем быстрой сортировки. Таким образом, эта сортировка является рекурсивной. Условием выхода из рекурсии является получение на вход массива длиной в один или два элемента
- После окончания действия алгоритма массив будет отсортирован.
Заметим, что выбор опорного элемента может влиять на скорость выполнения алгоритма. Также данная сортировка является одной из самых популярных и используемых, и часто является встроенной для различных языков программирования.
Пример работы быстрой сортировки приведен на рисунке 6.

Рисунок 7. Пример работы быстрой сортировки.
Приведем код сортировки на языке С++:
void quickSortR(int* a, long N) {
// На входе - массив a[], a[N] - его последний элемент.
|
long i = 0, j = N - 1; T temp, p; |
// поставить указатели на исходные места |
|
p = a[N >> 1]; // процедура разделения do { |
// центральный элемент |
while (a[i] < p) i++; while (a[j] > p) j--; if (i <= j) {
temp = a[i]; a[i] = a[j]; a[j] = temp; i++; j--;
}
} while (i <= j);
// рекурсивные вызовы, если есть, что сортировать if (j > 0) quickSortR(a, j); if (N > i) quickSortR(a + i, N - i);
}
Заключение
В данной работы были рассмотрены различные алгоритмы сортировок. Был проведен анализ процесса эволюции этих алгоритмов. Были приведены основные методы классификации алгоритмов сортировок. Было проведено сравнение сортировок пузырьком, вставками и быстрой по времени их выполнения. Были приведены подробное описание и пример реализации алгоритмов этих сортировок, а также сортировки Шелла и простым выбором. Таким образом, были выполнены основные цели и задачи курсовой работы, то есть:
- Проанализирована эволюция методов сортировки.
- Проведена классификации и сравнение методов сортировки.
- Подробно изучены и реализованы на языке С++ некоторые алгоритмы.
Список использованных источников
- United States Census // Sources of U. S. Census Data, from MIT Libraries, 2011. URL: http://libraries.mit.edu/guides/types/census/sources.html (дата обращения: 09.06.2019)
- Г. В. Электрическая машина Голлерита для подсчета статистических данных // В. О. Ф.Э.М. — 1895. — № 225. — С. 193–201.
- Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — № 8. — С. 50–53.
- Кнут Д. Э. Искусство программирования, т.3. Сортировка и поиск. — М.: Издательский дом «Вильямс», 2010.
- Никитин Ю. Б. Сложность алгоритмов сортировки на частично упорядоченных множествах: автореферат дис. … канд. физ.-мат. наук: 01.01.09 / Никитин Юрий Борисович. — Москва, 2001. — 80 с.
- Дупленко А. Г. Эволюция способов и алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №9. — С. 17-19. — URL https://moluch.ru/archive/56/7702/ (дата обращения: 09.06.2019).
- Овчинникова И. Г., Сахнова Т. Н. Алгоритмы сортировки при решении задач по программированию // Информатика и образование. — 2011. — № 2. — С. 53–56.
- Антонова И. И., Карих О. А. Оценка эффективности параллельных алгоритмов задачи сортировки данных // Промышленные АСУ и контроллеры. — 2010. — № 3. — С. 23–25.
- Мартынов В. А., Миронов В. В. Параллельные алгоритмы сортировки данных с использованием технологии MPI // Вестник Сыктывкарского университета. Серия 1: Математика. Механика.
Информатика. — 2012. — № 16. — С. 130–135.
- Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №8. — С. 50-53. — URL https://moluch.ru/archive/55/7474/ (дата обращения: 10.06.2019).
- Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Глава 7. Быстрая сортировка // Алгоритмы: построение и анализ = Introduction to Algorithms / Под ред. И. В. Красикова. — 2-е изд. — М.: Вильямс, 2005. — С. 198219. — ISBN 5-8459-0857-4.

- Перевод реалий
- СУФФИКСАЛЬНАЯ СИСТЕМА СОВРЕМЕННОГО АНГЛИЙСКОГО ЯЗЫКА
- Современные технологии планирования и прогнозирования социально-экономического развития территорий. Особенности управления региональным рынком труда
- Особенности коммуникаций в организации(Коммуникационный процесс: понятие, основные элементы, этапы, их характеристика)
- Презумпции и фикции в праве.
- Обеспечения законности и правопорядка в России
- Тенденции развития международной валютной системы в государстве
- История акционерных обществ России
- Методы управления инновационными проектами (Понятие и сущность инновационного проекта)
- Современные политические режимы (Понятие и классификация современных политических режимов)
- сновы программирования на языке Pascal
- Разработка регламента выполнения процесса «Управление документооборотом.