
Операции, производимые над данными
Содержание:

ВВЕДЕНИЕ
В ходе изучения дисциплин связанных с информационными технологиями, нередко приходится сталкиваться с таким понятием как «данные». Так или иначе, но на сегодняшний день информационные технологии задействованы практически в каждой научной или практически-значимой сфере общества, что безусловно накладывает отпечаток ответственности при обработке данных. Самими же данными выступают практически-применимые разносторонние сведения об окружающем мире, которые могут быть задействованы в контексте заданной сферы. Методы обработки данных, их внутреннее представление и способы их ввода и вывода – основополагающие моменты в понимании не только элементарных составляющих информационных наук в целом, но и ключ к созданию таких сложных и инновационных моделей, как компьютерное обучение, нейросети, Data mining, серверные структуры взаимодействия и многие другие вещи, без которых уже не функционирует практически ни одно серьёзное предприятие. Поэтому, изучение общих положений по обработке данных – является приоритетной целью для каждого, кто хотел бы изучить любую сферу информационных технологий на продвинутом уровне. Исходя из этого, может быть сформулирована цель курсовой работы – изучение принципов работы с данными в информационных технологиях в простейшем случае. Для достижения этой цели понадобится выполнить следующие задачи:
- Изучить способоы представления данных в информационных технологиях
- Изучить основные приёмы работы с данными
- Выявить практическую значимость и область применения этих приёмов работы
- Проанализировать современные технологические решения с позиции полученных сведений об представлении и обработке данных
Поставленные задачи иллюстрируют актуальность указанной темы – а именно, в ходе курсовой работы будут рассмотрены современные и крайне востребованные на сегодняшний день технологии, которые уже доказали свою практическую значимость, с точки зрения обработки данных. На основании этого, можно выдвинуть гипотезу о том, что способы обработки данных являются основополагающей областью для изучения любой современной технологии.
Объект исследования – это вся область знаний информационных технологий.
Предметом исследования являются сами данные, операции над ними, Datascience и стек актуальных технологий, связанных с Datascience.
Методами исследования будут выступать различные учебные пособия и приёмы построения архитектуры данных, описанные в них.
ГЛАВА 1. ИНФОРМАЦИЯ И ЕЁ ПРЕДСТАВЛЕНИЕ
1.1. ИНФОРМАЦИЯ И ЕЁ ОБРАБОТКА
Информацией называются различные сведения, отражающие реальный мир. В информатике этот термин неразрывно связан с понятием «данные». Под данными подразумевают отрывочные разрозненные сведения. [3]
Одним из возможных способов достижения какой-то цели в сфере информационных технологий является обработка поступающих данных. В качестве теоретических стадий обработки информации можно выделить:
Стадия формирования первичных данных. Т.е. стадия получения цепочки сведений в каком-либо виде (сообщения об операциях, различные нормативные и юридические акты, параметры автомобиля и т.д) [1]
Стадия накопления и систематизации данных, т.е сбор различного рода сведений, отбор необходимых для решения поставленной задачи и организация удобной системы навигации в этих структурах.
Стадия обработки информации – другим словами, создание нового набора данных на основе предыдущих. Обычно такие данные являются обобщающими, аналитическими, рекомендательными, прогнозными и т.д. Такие данные в последствии могут быть подвергнуты дополнительной обработке для получения более глубоких выводов. [2]
Вывод результатов в удобном для человека формате. Таким форматом, в частности, может быть графическое изображение, звук, текст и т.д.
Сведения, появляющиеся на первом этапе могут иметь различный формат: бумажный документ, данные на цифровом носителе, видеозапись, звук. Причём, как правило, сведения, содержащиеся на физических носителях, полученные от аналоговых устройств оказываются менее долговечными, чем прочие. Современные способы хранения информации включают в себя совершенно другие подходы – в частности дискретные методы представления. [1] Такие дискретные данные могут быть преобразованы в машинный код средствами ЭВМ. Обработка данных в таком виде сопряжена с некоторого рода проблемами, одной из таких проблем является точность и корректность записи и отображения разных видов данных. Под точностью понимают отсутствие погрешностей или ошибок при выполнении задачи. Корректность же означает частоту появления ошибок в данных, которые могут возникать при сборе, наблюдении или измерении. [1]
Точность определяется степенью детализации. Для примера можно взять измерение веса на весах. Вес тела, измеренный на весах с разным уровнем детализации может иметь разные значения (например, на одних менее точных весах вес объекта составит 75 кг, а на других, более точных вес составит 75.12 кг).
Данные сами по себе – это диалектическая составная часть информации. Они представимы в виде зарегистрированных сигналов. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и прочие. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях разных видов. [1]
1.2 НОСИТЕЛИ ДАННЫХ
Наиболее популярным носителем данных, но не наиболее экономным считается бумага. На бумаге данные регистрируются методом отображения оптических данных на её плоскости. Изменение оптических качеств (изменение коэффициента отблеска плоскости в конкретном спектре длин волн) применяется еще в устройствах, осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием ( CDROM ). [2] В качестве носителей, использующих перепады магнитных качеств, можно выделить магнитные ленты и диски. Регистрация данных методом корреляции химического состава поверхностного состава носителя обширно применяется в фотографии. На биохимическом уровне можно наблюдать скопление и предоставление данных в живой природе. [2]
Носители данных привлекают наше внимание не в качестве отдельной составляющей, а потому что качества информации очень плотно связаны с качествами ее носителей. Всякий носитель возможно охарактеризовать параметром разрешающей возможности (количеством данных, записанных в принятой для носителя единице измерения) и динамическим спектром (логарифмическим отношением интенсивности амплитуд предельного и малого регистрируемого сигналов). От данных качеств носителя зачастую зависимы такие качества информации, как полнота, доступность и достоверность. [2] Так, мы можем рассчитывать, что в базе данных, размещаемой на компакт-дисках, легче будет гарантировать полноту информации, чем в схожем образом сконструированной версии этой базы данных, размещенной на гибком магнитном диске, потому что в первом случае плотность записи данных на единице длины дорожки гораздо больше. Для простого покупателя доступность информации в бумажном носителе ниже, чем та же информация на компакт-диске, потому что не вся информация может быть представлена в бумажном варианте. И, в конце концов, ясно, что зрительный эффект от просмотра слайдов на проекторе гораздо выше, чем от просмотра подобной картинки, написанной на бумаге. [3]
Задача переустройства данных с целью замены носителя относится к одной из наиглавнейших задач информатики. В контексте цены вычислительных систем устройства для ввода и вывода данных, работающие с носителями информации, могут достигать до пятидесяти процентов цены всех прочих аппаратных средств. [3]
Одним из примеров восхитительного запоминающего устройства и носителя данных можно назвать человеческий мозг, имеющий в пределах (10—15)*109 нейронов — ячеек, совмещающих функции памяти и логической обработки информации.
Объём мозга в среднем ., масса -1,2 кг, потребляемая мощность в пределах 2,5 Вт. Самые технологичные современные электронные запоминающие устройства при схожей ёмкости занимают объём всего пару . при массе в десятки и сотни кг, а потребляемая мощность достигает несколько кВт. [3]
Научно аргументированные мнения говорят, что развитие технологий в электронной технике и использование последних высокоэффективных накопительных сред в сочетании с всесторонним внедрением бионики при решении проблем, связанных с синтезом запоминающих приборов, разрешат создавать запоминающие устройства, схожие по свойствам с памятью человека.
1.3 ОПЕРАЦИИ С ДАННЫМИ
Данные характеризуются собственным типом и множеством операций над ними. Данные в компьютере можно условно разделить на простые и сложные.
Примеры простых данных, которые способен обрабатывать компьютер приведены в таблице 1:
|
№ |
Типы данных |
Операции |
|
1 |
Числа (числовые данные) |
Все арифметические операции |
|
2 |
Тексты(символьные данные) |
Замещение, вставка, удаление символов, сравнение, конкатенация строк |
|
3 |
Логические(бинарные) данные |
Все логические операции (конъюнкция, дизъюнкция, отрицание и др.) |
|
4 |
Изображения:рисунки, графика,анимация (графические данные) |
Операции над пикселями, из которых состоит изображение: яркость, цвет, контрастность |
|
5 |
Видео данные |
Удаление фрагмента, вставка фрагмента, работа с кадрами |
|
6 |
Аудио данные |
Усиление, уменьшение, удаление фрагмента, вставка фрагмента |
Таблица 1. Типы данных, обрабатываемых компьютером
Сложные данные можно разделить по характеру описанных в них данных на однотипные и разнотипные. К однотипным данным обычно относят массивы и списки, а к разнотипным структуры, записи и таблицы, хотя это и довольно условное разделение, зависящее от архитектуры представления. [1] В ходе осуществления информационного процесса данные могут быть преобразованы из одного типа в другой с помощью методов. Обработка данных включает в себя множество различных операций. По мере внедрения новейших технологий и повсеместного усложнения связей в социуме, затраты на обработку данных неуклонно возрастают. Как правило, это связано с неизменным усложнением критериев управления производством и социумом. [2] Следующий фактор, тоже вызывающий сильное увеличение объемов обрабатываемых данных, также связан с научно-техническим прогрессом, а именно с качественными темпами создания и внедрения новых носителей данных, средств обеспечения их безопасности и транспортировки. [3]
В структуре определяемых операций с данными возможно отметить главные:
- сбор данных – создание базы информации с целью обеспечения минимальной полноты для принятия решений;
- формализация данных - приведение данных, поступающих из различных источников, к схожей форме, чтобы привести их к сопоставимой между собой форме, то есть увеличить их степень доступности;
- фильтрация данных - отсеивание «ненужных» данных, в которых нет нужды для принятия решений; в этом случае должен быть снижен уровень лишней информации, а достоверность и адекватность данных в этом случае будет лишь увеличиваться;
- сортировка данных - упорядочение данных по какому-либо признаку с целью увеличения степени удобства использования, что увеличивает доступность данных;
- архивация данных - организация дополнительной безопасности для данных в удобной и легкодоступной форме; используется для снижения ресурсов, необходимых для хранению данных и повышает общую степень безопасности информационного процесса в целом;
- защита данных - множество мер, нацеленных на предотвращение утраты данных, повышает безопасность использования и модификации данных;
- транспортировка данных это получение и отдача (доставка и поставка) данных между удаленными членами информационного процесса; при данном подходе отправителя данных в информатике принято называть сервером, а получателем - клиентом;
- преобразование данных - перевод данных в различные формы, типы или структуры. Переустройство данных нередко связано с модификацией типа носителя, к примеру статьи могут содержаться в обычной бумажной форме, но возможно приспособить для этих целей и электронную форму, и микрофотопленку.
Нужда в неоднократности преобразований данных возникает также при их перемещении, тем более в случае если оно выполняется способами, непредназначенными для транспортировки представленного вида информации. Для иллюстрации этого факта можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства — телефонные модемы. [1]
ГЛАВА 2. КОДИРОВАНИЕ ДАННЫХ
2.1 КОДИРОВАНИЕ ДАННЫХ ДВОИЧНЫМ КОДОМ
Для упрощения принципов взаимодействия с данными различных типов и форматов представления, не последнюю роль может сыграть создание общих методов работы с ними. Чтобы разработать такие методы обычно применяются приемы кодирования информации, что выражается в преобразованиях одного типа к другому. Сама эта идея появилась из логики о том, что естественные языки также являются системой кодировки понятий через слова для выражения какой-то мысли посредством речи. [4] В этом ключе принято считать примыкающую к языку азбуку как систему кодировки самого языка с помощью графических обозначений. Попытки унификации языков принимались на протяжении всей истории, однако, чаще всего они заканчивались безрезультатно (если не считать некоторые естественные ассимиляционные процессы). [5] Если подходить к этому вопросу научным образом, то эти провальные попытки можно объяснить с позиции социальных потрясений, которые непременно возникнут в ходе изменения системы кодирования общественных данных, что влечёт за собой также правовые и моральные потрясения. Такие же проблемы наблюдаются и в отдельных отраслях науки, культуры и техники. Тем не менее, в искусственной среде отдельных сфер применения можно встретить успешных представителей. [6] В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое. Собственная система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит). В качестве примера могут быть использованы такие кодировки как ASCII, азбука Морзе, коды Брайля, сигнальные морские коды. [4]
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия: 00 01 10 11
Тремя битами можно закодировать восемь различных значений: 000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
где N — количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в данной системе. [4]
2.2 КОДИРОВАНИЕ ЦЕЛЫХ И ДЕЙСТВИТЕЛЬНЫХ ЧИСЕЛ
Способов преобразования целых чисел в двоичный код довольно много, для ручного перевода целого числа в двоичное представление — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа. [4]
19:2 = 9 + 1
9:2=4+1
4 : 2 = 2 +0
2:2=1+0
Таким образом, 1910= 100112.
Конечно же ЭВМ не делает это таким методом, обычно за кодировку целых чисел отвечают специальные служебные регистры в процессоре, сама по себе память в компьютере представляет собой последовательность бит, которые затем, при необходимости, могут быть преобразованы в различные системы счисления. [5]
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. [5] При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 • 101 300 000 = 0,3 • 106
123 456 789 - 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком). [5]
2.3 КОДИРОВАНИЕ ТЕКСТОВЫХ ДАННЫХ
Память компьютера устроена таким образом, что каждый объект в ней представляет из себя набор чисел, которые могут быть раскодированы однозначным образом. [6] Каждому числу в определённом контексте ставится в соответствие какое-то абстрактное понятие. Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§». [6]
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера. [6]
Для английского языка противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных. [6]
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 2. Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). [5] Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
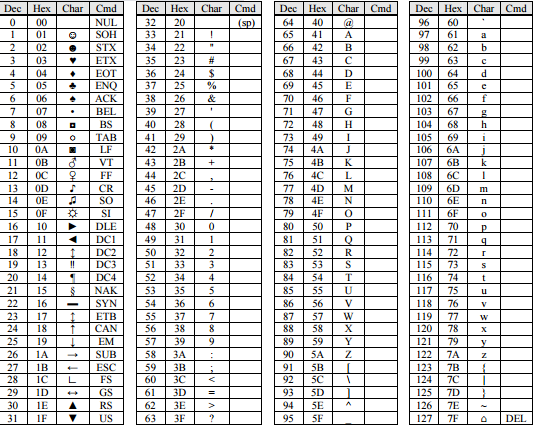
Таблица 2. Таблица кодировки ASCII
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 3). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows. [4]
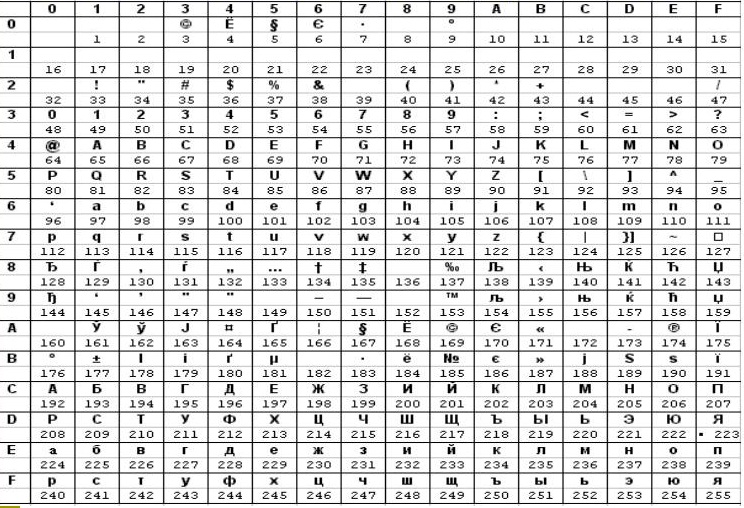 Таблица 3. Кодировка Windows 1251
Таблица 3. Кодировка Windows 1251
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица4). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернет.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ICO (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко. [5]

Таблица 4. Кодировка КОИ-8
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день.
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики. [4]
2.4 УНИВЕРСАЛЬНАЯ СИСТЕМА КОДИРОВАНИЯ ТЕКСТОВЫХ ДАННЫХ
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). [6] В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. [5] Unicode (Юникод или Уникод, англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. В MicrosoftWindows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти. [4]
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы. [6]
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, — а эта работа ведётся постоянно, поскольку изначально система Юникод включала только Plane 0 — двухбайтные коды, — выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
1.1 (соответствует стандарту ISO/IEC 10646—1:1993),
2.0, 2.1 (тот же стандарт ISO/IEC 10646—1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2),
3.0 (стандарт ISO/IEC 10646—1:2000).
3.2 (стандарт 2002 года)
4.0 (стандарт 2003)
4.01 (стандарт 2004)
4.1 (стандарт 2005)
5.0 (стандарт 2006)
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 231 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 220+216 (1 114 112) для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — сегодня (в версии 5.0) используется чуть больше 99 000 кодовых позиций. [6]
Кодовое пространство разбито на 17 плоскостей по 216 (65536) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей. Плоскости 16 и 17 выделены для частного употребления. [5]
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов 0…FFFF) или «U+xxxxx» (для кодов 10000…FFFFF) или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных. [4]
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования. [6]
Графические символы включают в себя следующие группы:
xgVEVEVEљ
~lUCU.U
буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов; цифры; знаки пунктуации; специальные знаки (математические, технические, идеограммы и пр.); разделители. [4]
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character). [5]
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (base characters), а непротяжённые- модифицирующими (combining characters); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ?» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов — селекторы варианта начертания (variation selectors). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов письма Phags-Pa. [4]
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
Форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции. [5]
Форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода. [6]
В любой последовательности символов, стартующей с начального символа S символ C блокируется от S если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки прошедшие каноническую декомпозицию.
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода.
Символ X может быть первично совмещен с символом Y если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>.
Если очередной символ C не блокируется последним встреченным начальным базовым символом L, и он может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется. [4]
Форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
Форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией. [4]
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. [4] Под символы кириллицы выделены коды от U+0400 до U+052F. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода. [5]
2.5 КОДИРОВАНИЕ ГРАФИЧЕСКИХ ДАННЫХ
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. [5] Растровое изображение представлено на рисунке 2.

Рисунок 2. Растровое изображение
Растр - это метод кодирования графической информации (точечная структура графического изображения).
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа. [6]
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основных цвета:
красный (Red, R);
зеленый (Green, G);
синий (Blue, В).
На практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB (по первым буквам названий основных цветов). [6]
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн. различных цветов, что на самом деле близко к чувствительности человеческого глаза. [6] Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. [4] Соответственно, дополнительными цветами являются:
голубой (Cyan, С);
пурпурный (Magenta., М);
желтый (yellow, Y).
Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). [6] Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color. [5]
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным — без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (то есть, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация может быть неправильной: листва на деревьях может оказаться красной, а небо — зеленым). [5]
2.6 КОДИРОВАНИЕ ЗВУКОВОЙ ИНФОРМАЦИИ
Способы работы со звуком пришли в вычислительную технику позднее. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. [4] Огромное количество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). [6] Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны. [5]
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. [4] Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. [6] Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
ГЛАВА 3. ПРИМЕНЕНИЕ ОБРАБОТКИ ДАННЫХ В СОВРЕМЕННЫХ ТЕХНЛОГИЯХ
3.1 РАСПРЕДЕЛЕННЫЕ ФАЙЛОВЫЕ СИСТЕМЫ
Распределенная файловая система похожа на обычную файловую систему, но, в отличие от последней, она работает на нескольких серверах сразу. В ней можно делать почти все, что делается в обычных файловых системах. В основе любой файловой системы лежат такие действия, как хранение, чтение и удаление данных, а также реализация средств безопасности файлов – распределенные файловые системы не являются исключением. [7] Распределенные файловые системы обладают рядом важных преимуществ:
Они способны хранить файлы, размер которых превышает размер диска отдельного компьютера
Файлы автоматически реплицируются на нескольких серверах для создания избыточности или выполнения параллельных операций, при этом все сложности технической реализации скрываются от пользователя. [8]
Система легко масштабируется: пользователь не ограничивается объемом памяти или дискового пространства одного сервера.
Раньше масштабирование осуществлялось переводом всех систем на сервер с большим объемом памяти и дискового пространства на более быстрые процессоры (вертикальное масштабирование). В наше время в систему можно добавить ещё один малый сервер (горизонтальное масштабирование). Благодаря этому принципу потенциал масштабирования становится практически безграничным. [7]
В настоящее время самой популярной распределенной файловой системой является Hadoop File System. Она представляет собой реализацию Google Hadoop File System, так как эта система чаще всего применяется на практике. Впрочем, существует много других распределенных файловых систем. [7]
После того, как данные будут сохранены в распределенной файловой системе, их нужно использовать. Одним из важных аспектов работы с распределенным жестким диском заключается в том, что вы не перемещаете данные к программе, а скорее перемещаете программу к данным. К счастью, в сообществе разработки открытого ПО было создано много инфраструктур, которые выполняют всю «черную работу», связанную с перезапуском сбойных заданий, отслеживанием результатов из других субпроцессов и т.д. [7]
После создания распределенной файловой системы необходимо добавить данные. Нужно переместить данные из одного источника в другой, именно здесь в полной мере проявляются достоинства таких инфраструктур интеграции данных, как Apache Sqoop и Apache Flume. Процесс похож на процесс извлечения, преобразования и загрузки в традиционных складах данных.
Когда данные оказываются на своем месте, наступает время извлечения вожделенной скрытой информации. На этой стадии приходится использовать методы из области машинного обучения, статистики и прикладной математики. До второй мировой войны все вычисления приходилось выполнять вручную, что существенно ограничивало возможности анализа данных. [7] После второй мировой войны появились компьютеры и технологии научных вычислений. Один компьютер мог выполнять огромные объемы вычислений, и перед исследователями открылся новый мир. Со времен этой научной революции человеку достаточно построить математические формулы, записать их в алгоритм и загрузить данные. При огромных объемах современных данных один компьютер уже не справлялся с нагрузкой. Более того, некоторые алгоритмы, разработанные в предыдущем веке, никогда не завершатся до момента гибели Вселенной, даже если бы в вашем распоряжении оказались вычислительные ресурсы всех существующих компьютеров на земле. Этот факт связан с их временной сложностью. Пример такого алгоритма – попытка взлома пароля с проверкой всех возможных комбинаций. Один из самых серьёзных недостатков старых алгоритмов заключается в том, что они плохо масштабировались. При тех объемах данных, которые приходится анализировать сегодня, это создает проблемы, и для работы с такими объемами данных требуются специализированные библиотеки и инфраструктуры. [8] Самая популярная библиотека машинного обучения для Python называется Scikitlearn. Это отличный инструмент машинного обучения, и большинство специалистов в этой области активно использует её. Хотя конечно существуют и другие библиотеки Python. Конечно, варианты не ограничиваются библиотеками Python. Spark – новое ядро машинного обучения с лицензией Apache, специализирующееся на машинном обучении в реальном времени. [8]
3.2 БАЗЫ ДАННЫХ NOSQL
Для хранения данных требуется программное обеспечение, а для больших данных – специализированное программное обеспечение, которое могло было бы управлять данными и формировть запросы к ним. Традиционно в этой области правил бал реляционные базы данных – такие как Oracle Sql, Mysql, Sybase IQ и др. И хотя во многих ситуациях они все ещё считаются предпочтительным решением, появились новые типы баз данных, объединенные в категорию баз данных Nosql. [8]
Название категории обманчиво, потому что ”No” в этом контексте ознает не только. Нехватка функциональности в SQL не является основной причиной сдвига парадигмы, и многие базы данных NoSQL реализовали собственную версию SQL. Однако у традиционных баз данных существуют свои недостатки, которые усложняют их масштабирование. Решая некоторые проблемы традиционных баз данных, базы данных NoSQL обеспечивают возможность почти неограниченного роста данных. Эти недостатки проявляются во всем, что относится к большим данным: их память и вычислительный ресурс не масштабируется за пределы одного узла и в традиционных базах данных отсутствуют средства обработки потоковых, графовых и неструктурированных форм данных. [8]
Существует много разновидностей баз данных, но их можно разделить на следующие типы:
Столбцовые базы данных – данные организуются в столбцы, что позволяет алгоритмам существенно повышать скорость обработки запросов. В более современных технологиях используется принцип хранения по ячейкам. Табличные структуры продолжают играть важную роль в обработке данных. [7]
Хранилища документов - хранилища документов не используют таблицы, но хранят полную информацию о документе. Их отличительной особенностью является чрезвычайно гибка схема данных
Потоковые данные – сбор, преобразование и агрегирование данных осуществляется не по пакетному принципу, а в реальном времени. Хотя мы выделили потоковые данные в категорию баз данных, чтобы упростить выбор инструмента, скорее они образуют особую разновидность задач, породившую такие технологии, как Storm. [8]
Хранилища «ключ-значение» - данные не хранятся в таблицах, с каждым значением связан ключ.
SQL в Hadoop – пакетные запросы в Hadoop пишутся на SQL-подобном языке, во внутренней реализации которого используется инфраструктура отображения свертки (map-reduce)
Обновленный SQL – этот тип сочетает масштабируемость баз данных NoSQL с преимуществом реляционных баз данных. Все эти базы данных используют интерфейс SQL и реляционную модель данных [8]
Графовые базы данных – не для всех задач табличный формат является оптимальным. Некоторые задачи более естественно подходят для представления в виде графа и хранения в графовых базах данных. Классический пример такого рода – социальная сеть.
Инструменты планирования упрощают автоматизацию повторяющихся операций и запуск заданий по событиям (например, при появляении нового файла в папке). Они похожи на такие традиционные программы, как CRON в Linux, но разработаны специально для операций с данными. Например, такие инструменты могут запускать MapReduce при появляении нового набора данных в каталоге. [8]
Стоит упомянуть безопасность. При обеспечении безопасности нужно организовывать механизмы точного управления доступом к данным, но делать это на уровне каждого приложения – ещё та головная боль. Средства безопасности больших данных позволяют создать централизованную и высокоточную систему управления доступом к данным. Безопасность больших данных превратилась в самостоятельную область исследований, и специалисты data science обычно сталкиваются с ней в роли потребителей данных, редко когда им приходится реализовывать средства безопасности самостоятельно. [8]
Существуют инструменты сравнительного анализа. Этот класс инструментов был разработан для оптимизации установки больших данных за счет предоставления стандартизированных профилей. Профили строятся на основании представительного множества операций с данными. Задачи сравнительного анализа и оптимизации инфраструктуры больших данных и настройки конфигурации часто относятся к компетенции не специалистов data science, а профессионалов, специализирующихся на организации IT-инфраструктуры. Использование оптимизированной инфраструктуры приводит к существенной экономии. Например, экономия 10% в кластере из 100 серверов равна стоимости 10 серверов. [7]
Само же развертывание системы и подготовка инфраструктуры данных – непростая задача. Инструменты развертывания системы проявляют себя при развертывании новых приложений в кластерах больших данных. Они в значительной степени автоматизируют установку и настройку компонентов в данных. [7]
Предположим, мы создали приложение для прогнозирования результатов футбольных матчей и теперь хотим предоставить всем желающим доступ к прогнозам нашего приложения. Однако, мы понятия не имеем какие архитектуры или технологии будут использоваться в их системах. Инструменты программирования служб обеспечивают доступ к приложениям данных как к сервису. В разработке архитектуры управления данными иногда приходится открывать доступ к моделям через службы. Самым известным примером такого рода является REST-служба. Сокращение REST обозначает Representation State Transfer, т.е передача состояния представления. Эти службы часто используются для передачи данных веб-сайтам. [7]
3.3 СВЯЗИ И КЛАССИФИКАЦИИ ДАННЫХ
Данные - обобщающий термин для любых наборов информации, достаточно объемных и сложных, чтобы от их обработки можно было бы добиться какого-то определённого результата. Данные можно охарактеризовать «четырьмя V»: объемом, разнообразием, скоростью и достоверностью. Основным содержанием data science являются методы аналаза наборов данных, от совсем небольших до гигантских. [7] Процесс data science сам по себе нелинеен, но его можно разделить на несколько шагов:
- Назначение цели исследования.
- Сбор данных
- Подготовка данных
- Исследование данных
- Моделирование.
- Отображение и автоматизация
Набор технологий данных вовсе не сводится к табличным методам представления информации. [8]Он состоит из множества разных технологий, которые можно разбить на следующие категории:
- Файловая система
- Инфраструктуры распределенного программирования
- Интеграция данных
- Базы данных
- Машинное обучение
- Безопасность
- Планирование
- Сравнительный анализ
- Развертывание
- Программирование служб
Не все категории больших данных интенсивно используются специалистами data science. В основном они занимаются файловыми системами, инфраструктурами распределенного программирования, базами данных и машинным обучением. Конечно, им приходится иметь дело с другими компонентами, и все же эти предметные области относятся к сфере деятельности других профессий. [7]
Данные могут существовать во многих формах. Основные формы:
- Структурированные данные
- Неструктурированные данные
- Данные на естественном языке
- Машинные данные
- Графовые данные
- Потоковые данные
Структурированный подход к data science повышает вероятность успеха в проектах при минимальных издержках. [8] Он также делает возможным коллективную работу над проектом, при которой каждый участник группы занимается той областью, в которой наиболее силен. Однако, этот подход не годится для всех типов проектов и не является единственно правильным подходом к качественной обработке и анализу данных.
ЗАКЛЮЧЕНИЕ
В ходе данной работы были рассмотрены различные приёмы построения архитектуры данных, а также операции над ними. В ходе рассмотрения приёмов представления данных во внутреннем пространстве компьютера мы пришли к выводу, что в процессе развития информационных технологий получили своё непосредственное развитие унифицированные способы работы с информацией, в следствии чего удалось использовать методические наработки в различных сферах одной области, что повлекло за собой активное развитие всего спектра информационных технологий. В конечном счёте, это привело к созданию таких технологий как машинное обучение, облачные хранилища, архитектуры серверного типа и многие другие. В рамках курсовой работы были сформулированы задачи, решение каждой из которых нашло своё отражение в этой работе. В частности:
- Были изучены способы представления данных в информационных технологиях
- Были изучены основные приёмы работы с данными
- Была выявлена практическая значимость и область применения этих приёмов работы
- Проанализированы современные технологические решения с позиции полученных сведений об представлении и обработке данных
На основании выполнения этих задач можно сделать вывод, что наша гипотеза о том, что способы обработки данных являются основополагающей областью для изучение любой современной технологии полностью подтвердилась, в следствии чего, можно говорить о базисной концепции изучаемой области, что, в частности, делает написанную курсовую работу – методическим пособием для начинающих изучать информационные технологии в целом, или же тех, кто хочет разобраться в какой-то конкретной области современных технологических решений.
БИБЛИОГРАФИЯ
- Волк В.К. Исследование функциональной структуры памяти персонального компьютера. Лабораторный практикум. Учебное пособие. Издательство Курганского государственного университета, 2004 г. – 72 с.
- Алёна Палажченко. История бумажного листа. Наука и жизнь. № 12, 2009
- Божко, В.П. Информатика: данные, технология, маркетинг / В.П. Божко, В.В. Брага, Н.Г. Бубнова. — М.: Финансы и статистика, 2014. — 224 c.
- Велихов, А. С. Основы информатики и компьютерной техники: учебное пособие / А. С. Велихов. – Москва: СОЛОН-Пресс, 2007. – 539 с.
- Верещагин, Н. К. Информация, кодирование и предсказание / Н.К. Верещагин, Е.В. Щепин. - М.: ФМОП, МЦНМО, 2016. - 240 c.
- Гоппа, В.Д. Введение в алгебраическую теорию информации / В.Д. Гоппа. - М.: ФИЗМАТЛИТ, 2013. - 112 c.
- Девенпорт Т. О чем говорят цифры. Как понимать и использовать данные/ Томас Денвенпорт, Ким Джин Хо, пер. с анг. Э. Кондуковой – М.: Манн, Иванов и Фербер, 2014 -224с.
- Силен Дэви, Мейсман Арно, Али Мохамед Основы Data Science и Big Data. Python и наука о данных. – СПБ.: Питер, 2017. -336с.: ил.

- Разработка регламента выполнения процесса «Учет реализации лекарственных препаратов через аптечную сеть» (Анализ предметной области)
- Понятие правонарушения ( Юридический состав правонарушения)
- Органы исполнительной власти»
- Изучение понятия и основ оперативно-розыскной деятельности
- Выбор стиля руководства организации(Теоретические аспекты стилей руководства в организации)
- Роль мотивации в поведение организации (Мотивация в современных условиях)
- Жизненный цикл организации и ее управление на примере Кольского филиала АО «Атомэнергоремонт»
- Влияние кадровой стратегии на работу службы персонала (Понятие и сущность деятельности)
- Организационная культура и ее роль в современных организациях (Методы формирования и управления организационной культурой)
- Корпоративная культура в организации ( Формирование корпоративной культуры )
- Теоретические и методологические аспекты управления мотивацией персонала
- Управление поведением в конфликтных ситуациях (Суть конфликтов в организации)