
Способы представления данных в информационных системах (Понятие, виды, классификация и способы предоставления данных в ИС)
Содержание:

ВВЕДЕНИЕ
Актуальность выпускной квалификационной работы. Информационная инфраструктура современного предприятия представляет собой сложнейший конгломерат разномасштабных и разнородных сетей и систем. Чтобы обеспечить их слаженную и эффективную работу, необходима управляющая платформа корпоративного масштаба с интегрированными инструментальными средствами. Однако до недавнего времени сама структура индустрии сетевого управления препятствовала созданию таких систем – «игроки» этого рынка стремились к лидерству, выпуская продукты ограниченной области действия, использующие средства и технологии, не совместимые с системами других поставщиков.
Сегодня ситуация меняется к лучшему - появляются продукты, претендующие на универсальность управления всем разнообразием корпоративных информационных ресурсов, от настольных систем до мэйнфреймов и от локальных сетей до ресурсов Сети. Одновременно приходит осознание того, что управляющие приложения должны быть открыты для решений всех поставщиков.
Целью работы является способы предоставления данных в ИС.
Для достижения поставленной цели необходимо решить следующие задачи:
- рассмотреть теоретические аспекты информационных систем
- рассмотреть краткую характеристику предприятия
- разработать информационную систему мониторинга и оповещения активного оборудования сети передачи данных АО «Ладога Телеком»
- провести тестирование системы
- изучить информационную безопасность
- рассчитать затраты на разработку системы.
В качестве объекта исследования выступит предприятие АО «Ладога Телеком».
Предметом настоящего исследования является информационная система мониторинга и оповещения активного оборудования сети передачи данных.
При написании курсовой работы использовались научные труды следующих авторов: Метелица Н.Т. [23], Логинов В.Н. [19], Завгородний В.И. [15], Гаврилов М.В. [9] и другие.
Методологической основой работы послужили методы: анализ, синтез, формализация, обобщение, а так же стандартные приемы анализа финансового состояния: горизонтальный, вертикальный, коэффициентный и сравнительный анализ.
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ИЗУЧЕНИЯ ИНФОРМАЦИОННЫХ СИСТЕМ
1.1 Понятие, виды, классификация и способы предоставления данных в ИС
Информационная система - совокупность содержащейся в базах данных информации и обеспечивающих ее обработку информационных технологий и технических средств. [1]
К таким организационным ресурсам относятся человеческие, технические, финансовые и т. д. ресурсы.
Т. е., к информационным системам относится такая совокупность средств, методов и персонала, которая взаимосвязана между собой и применяется не только для хранения информации, но и для ее обработки и выдачи, достигая при этом определенной цели управления. Но и, ни для кого не будет большим секретом, что в современном мире основным средством Обработки этой информации, конечно же, является компьютер. Так же следовало бы отметить, что в основном информационные системы преобразуют не столько информацию, сколько данные и поэтому правильнее будет, если мы будем называть эти системы не информационными, а системами обработки данных.
Рассмотрим более подробно функции, используемые в информационных системах:
- Во-первых, основной функцией информационных систем, конечно же, является сбор информации;
- Во-вторых, немаловажной функцией является функция хранения этой информации;
- В-третьих, в информационных системах никак не обойтись без поиска и сбора различной информации;
- В-четвертых, немаловажную роль играет и передача информации.[13]
То есть если говорить кратко, то в информационной системе происходят следующие процессы:
- ввод информации от источников информации;
- обработка (преобразование) информации;
- хранение входящей и обработанной информации;
- вывод информации для правок пользователю;
- возможно ввода информации от пользователя через обратную связь.
Основу системного построения информационной системы составляет ее структура, которая должна быть достаточно полной. Средствами структуризации есть процедуры декомпозиции (анализа) и композиции (синтеза) системы. Поэтому важным этапом проектирования информационной системы является структуризация системы - локализация ее границ и выделения структурных составных частей.
В современной информационной системе компьютер играет роль аппаратно-программной части.
Аппаратная часть: (Нагdwаге, «твердая часть» - «железо») состоит из соединенных между собой различных устройств, которые можно увидеть:
-процессор;
-запоминающее устройство;
- внешние устройства ввода-вывода;
- контроллеры внешних устройств;
-средства связи.[18]
Программное обеспечение (ПО): (Software, «мягкая») состоит из набора различных программ, управляющих работой компьютера, поддерживают диалог с пользователем, обрабатывают разнообразную информацию, помогают создавать различные программы.
Аппаратная часть не может выполнять операции по обработке информации без различных программ, благодаря которым устройства выполняют свои функции. Для обеспечения работоспособности компьютера и выполнения определенной работы нужна совокупность программ, которая создает программное обеспечение.
Программное обеспечение осуществляет управление устройствами компьютера во время ввода, обработки, вывода и хранения информации, создает условия для работы пользователя на компьютере и тому подобное.
Автоматизированная ИС – система, реализующая информационную технологию в сфере управления для совместной работы комплекса технических средств с управленческим персоналом. Ее предназначение - автоматизированный сбор, регистрация, хранение, поиск, обработка и выдача информации по запросам пользователей (управленческого персонала).[23]
В зависимости от целей выделяют такие типичные функции АИС как прогнозирование, планирование, учет, контроль, анализ, регулирование.
Классификация ИС выполняется по ряду признаков: по структурированности решаемых задач, по функциональному признаку, по уровням управления, по характеру использования информации, по сфере применения, по типу используемой информации.
В соответствии со структурированностью решаемых задач информационные системы делятся на два класса:
-
- создающие управленческие отчеты. Ориентированы на стандартные процедуры обработки данных - поиск, сортировку, агрегирование, фильтрацию, группирование и т.д. Используя данные, которые они формируют, человек принимает управленческое решение. Применяются для структурированных задач;
- разрабатывающие возможные альтернативы решений. Применяются для частично структурированных задач. Генерируют множество решений, предлагаемых человеку; принятие им решения сводится к выбору одной из альтернатив.
Функциональный признак классификации информационных систем определяет назначение системы, ее основные цели, задачи и функции. В соответствии с этим признаком определяются следующие классы ИС:
- производственные. Осуществляют планирование объемов работ и разработку календарных планов, оперативный контроль и управление производством, анализ работы оборудования, участие в формировании заказов поставщикам, управление запасами;
- маркетинговые. Исследуют рынок и прогнозируют продажи, управляют продажами, вырабатывают рекомендации по производству новой продукции, анализируют и устанавливают цены, учитывают заказы;
- финансовые. Управляют портфелем заказов; кредитной политикой; разрабатывают финансовый план; выполняют финансовый анализ и прогнозирование; контролируют бюджет; осуществляют бухучет и расчет зарплаты;
- кадровые. Анализируют и прогнозируют потребности в трудовых ресурсах, ведут архивы записей о персонале, планируют подготовку и переподготовку кадров;
- прочие (например, для руководства). Контролируют деятельность предприятия, выявляют оперативные проблемы, анализируют управленческие и стратегические ситуации, обеспечивают процесс выработки стратегических решений. [27]
Классификация информационных систем по уровням управления соответствует приведенной ранее иерархической структуре субъекта управления:
- оперативного уровня - поддерживают персонал, состоящий из специалистов-исполнителей, обрабатывая данные о событиях, происходящих в объекте управления. Назначение таких ИС – отвечать на запросы о текущем состоянии ОУ и отслеживать поток событий на производстве, что соответствует оперативному управлению.
- тактического уровня - включают следующие виды информационных систем:
- офисной автоматизации - имеют целью повышение эффективности работы персонала, упрощение канцелярского труда, поддержание информационных коммуникаций.
- обработки знаний (включая экспертные системы) - имеют целью создание новой информации и нового знания на основе включенного в них знания экспертов в некоторой предметной области;
- управленческие - обслуживают персонал, который нуждается в ежедневной, еженедельной информации о состоянии дел. Основное назначение – отслеживание ежедневных действий на производстве и периодическое формирование строго структурированных сводных типовых отчетов.
- поддержки принятия решений - обслуживают частично структурированные задачи, результаты которых трудно спрогнозировать заранее
- стратегического уровня - обеспечивают поддержку принятия решений по реализации стратегических, перспективных целей развития производства
В зависимости от характера использования информации выделяют информационные системы:
-
- информационно-поисковые. Производят ввод, систематизацию, хранение, выдачу информации по запросу пользователя без сложных преобразований данных.
- информационно-решающие. Осуществляют все операции переработки информации по определенному алгоритму.
Классификация информационных систем по сфере применения выделяет следующие их виды:
- организационного управления. Для автоматизации функций управленческого персонала. Сюда относятся ИС управления как промышленными, так и непромышленными производствами
- управления технологическими процессами – для автоматизации функций производственного персонала. Используются при организации поточных линий, изготовлении микросхем, на сборке, для поддержания технологического процесса в различных видах промышленности;
- автоматизированного проектирования (САПР). Для автоматизации функций инженеров – проектировщиков, конструкторов, архитекторов, дизайнеров при создании новой техники или технологии. Основные функции – инженерные расчеты, создание графической документации (чертежей, схем, планов), создание проектной документации, моделирование проектируемых объектов;
- интегрированные (корпоративные) – для автоматизации всех функций производства и охватывают весь цикл работ от проектирования до сбыта продукции.
В соответствии с типом используемой информации выделяют классы информационных систем:
- фактографические. В таких ИС регистрируются факты – конкретные значения данных об объектах реального мира
- документальные. Обслуживают принципиально иной класс задач, которые не предполагают однозначного ответа на поставленный вопрос. БД таких систем образует совокупность неструктурированных текстовых документов и графических объектов, снабженная тем или иным формализованным аппаратом поиска.[34]
1.2 Популярные системы управления сетями
Настройка конфигурации устройств для их безупречной совместной работы, преобразование разных пользовательских интерфейсов к единому формату, ликвидация перегрузок, «узких мест» и простоев, наконец, получение оперативной информации о функционировании каждого элемента сети — вот далеко неполный перечень проблем, которые поможет решить система сетевого управления (Network Management System, NMS).
Раньше системы NMS имели не слишком хорошую репутацию. Казалось бы, продукты, предлагаемые в качестве каркаса компонентного сетевого ПО, должны пользоваться успехом у администраторов, но на практике все не так гладко. Стоят они дорого, их интерфейсы громоздки и неудобны, наконец, такие средства обычно не обеспечивают исчерпывающих возможностей управления. Зачастую клиенты отказываются от NMS в пользу управляющего ПО, поставляемого вместе с сетевыми устройствами, серверами, операционными системами или приложениями.
Заслуживающая внимания (и соответствующая своей цене) система NMS должна включать в себя хорошие средства управления, администрирования, обновления, мониторинга, формирования отчетов, диагностики, устранения неисправностей, настройки конфигурации, проведения аудита (или инвентаризации) и обеспечения безопасности. Сетевому администратору, вооруженному таким продуктом, не требуется специализированное ПО для организации эффективного управления пользователями, группами, устройствами и другими сетевыми ресурсами.
Программное обеспечение NNM использует данные из управляющей информационной базы (Management Information Bases, MIB), поступающие от различных источников, в том числе от мостов и повторителей. Часть этих сведений относится к управлению на Уровне 2, но в большинстве случаев NNM работает с информацией, соответствующей Уровню 3.
Система оперирует заранее определенными терминами в MIB. Их достаточно впечатляющий список позволяет получить четкое представление о загруженности сети и возникающих ошибках, полную статистику пакетов по категориям (входящие, исходящие, ошибочные), сведения о повторной пересылке данных, использовании памяти оборудованием Cisco и данные о полнодуплексных каналах связи. Средства анализа и выявления основных причин неисправностей помогли нам оперативно найти конкретные устройства, виновные в перебоях или замедлении выполнения тестов.
Модуль OpenView Internet Services представляет собой прекрасное средство контроля за соблюдением соглашений об уровне сервиса (SLA). Для определенных нами служб (начиная от средств организации доступа к Web и заканчивая обработчиками транзакций в области электронной коммерции) он предоставлял подробную информацию о готовности серверов и времени отклика. Когда значения параметров SLA выходили за оговоренные пределы, этот модуль выдавал предупреждающие сообщения.[4]
Для приложений на базе Web программное обеспечение OpenView Transaction Analyzer точно указывает препятствующие повышению производительности «узкие места» и точки перегрузки. Однако компонент Transaction Analyzer не предоставляет такой же полной и актуальной информации, как ПО Transact Toolkit из пакета VitalSuite.
Управление событиями в среде Unicenter характеризуется прекрасной организацией и простотой доступа к каталогу, в котором регистрируются все нештатные ситуации в сети. Когда нам понадобилась более подробная информация об определенных событиях, модуль Event Console приложения Unicenter Enterprise Manager быстро и без затруднений предоставил необходимые данные из репозитария.
Новый тип описываемых событий создается за счет определения параметров домена, идентификатора узла, типа устройства, условий возникновения ошибок и действий в момент регистрации ошибки.
При помощи агентов система Unicenter обеспечивает мониторинг сетевых сегментов, устройств и серверов. Компонент Unicenter Performance Management, правда, не имеет полнофункциональных средств анализа производительности (как соответствующие модули пакетов VitalSuite и OpenView), но способствует оперативному выявлению неисправностей сетевых элементов и серверов.
Чтобы выявить потенциальные неисправности, модуль Unicenter Historian анализирует все события и операции в сети. Затем он отображает базовую информацию, определяет тенденции и создает прогнозы на выбранный вами период.
Пакет VitalSuite представляет собой набор интегрированных компонентов, предназначенных для мониторинга работы сети, контроля за выполнением соглашений об уровне сервиса, отслеживания общей производительности сети, а также получения детальной информации о работе приложений и транзакциях.
Пакет VitalSuite включает в себя модули VitalNet, VitalAnalysis, VitalHelp, VitalAgent, AutoMon и Transact Toolkit. Компонент VitalNet собирает информацию с устройств, поддерживающих протокол SNMP, и с настольных компьютеров, на которых установлено клиентское программное обеспечение VitalAgent. Приложение VitalNet обменивается данными с программами VitalAnalysis и VitalHelp. Модуль VitalAnalysis следит за работой приложений и обеспечивает статистический анализ систем для определения их производительности и актуальных тенденций. При планировании ресурсов и решении других задач программа получает необходимые сведения за последний год, которые хранятся в базе данных Microsoft SQL Server, входящей в комплект поставки.
Компонент VitalHelp отслеживает работу приложений, базирующихся на TCP/IP. При обнаружении нештатной ситуации VitalHelp посылает предупреждение сетевому администратору (по электронной почте или на пейджер) либо системе NMS (в формате SNMP). ПО VitalSuite AutoMon обеспечивает обработку транзакций на базе сценариев, а компонент Transact Toolkit позволяет задавать уникальные транзакции бизнес-приложений, выполнение которых затем контролируется с помощью VitalSuite.[11]
Пакет Live Health компании Concord опрашивает устройства, управляемые по протоколу SNMP, определяет их текущие статус и состояние. Информация об ошибках, потенциальных перебоях в работе и скорости реакции серверов выводится в режиме реального времени. Программное обеспечение Network Health следит за производительностью и готовностью ресурсов территориально-распределенной сети — маршрутизаторов, коммутаторов, каналов Frame Relay и оборудования удаленного доступа.
Компонент System Health контролирует работу серверов и клиентов, предупреждая администраторов о снижении производительности приложений, сбоях оборудования или нехватке дискового пространства. Application Health является ориентированным на транзакции набором инструментальных средств, который служит для выявления причин замедленной реакции приложений. Входящая в состав Application Health программа Application Assessment позволяет следить за функционированием серверного ПО.
Подобно VitalSuite, программное обеспечение eHealth можно рассматривать как дополнение к системе OpenView. Оно также передает предупреждения SNMP, которые затем обрабатываются в среде OpenView. Однако VitalSuite и eHealth прежде всего являются средствами мониторинга, и им недостает присущих OpenView и Unicenter возможностей управления, контроля и конфигурирования устройств самого широкого диапазона.
Обследование сети с помощью eHealth осуществляется быстро и корректно. По умолчанию eHealth просматривает сетевые узлы в полночь (ежедневно), но эту процедуру можно проводить и в интерактивном режиме либо настроить на определенный день и час.
Для выявления статуса и состояния сетевых устройств они опрашиваются с пятиминутным интервалом (при желании последний можно увеличить). Программное обеспечение eHealth «понимает» форматы баз управляющей информации (MIB) и корректно распознает данные от различных маршрутизаторов Lucent и Cisco, коммутаторов Hitachi, да и остальных устройств, имеющихся в нашей лаборатории.
Прежде пользовательские интерфейсы систем NMS были очень медленными и неудобными. К счастью, в последнее время разработчики полностью пересмотрели подход к созданию консолей операционных систем, оснастив их хорошо спроектированными инструментальными панелями на основе технологии Web.
Помимо представления, базового для данной операционной системы (Windows или Unix), компонент OpenView NNM имеет интерфейс браузера. Модуль NNM представляет собой интуитивно понятное инструментальное средство, которое заметно упрощает управление сетью. В базовом режиме представления NNM поддерживаются расписание составления отчетов, настройка конфигурации и фильтрации трафика, структурная схема сети, выдача уведомлений о событиях, подробной информации о состоянии устройств, статистических данных и сигналов тревоги. Клиент Java может отображать схему расположения компонентов сети, предоставлять подробные сведения о состоянии устройств, посылать сигналы тревоги и выводить отчеты, в том числе для инвентаризации ресурсов.
Динамические Web-страницы NNM спроектированы особенно хорошо. Простые для понимания фильтры облегчают управление крупными сетями с помощью NNM.[22]
Система Unicenter поддерживает следующие представления управляемых объектов: табличное, двумерное и трехмерное.
В транснациональных корпорациях трехмерное представление позволяет «увидеть» глобальную сеть в виде вращающегося глобуса. Если на каком-то узле происходит сбой, Unicenter помечает его красным кружком. Каждый щелчок мышью на красном кружке переносит вас в город, на узел центра данных, в сетевой домен, сетевой сегмент и, наконец, на устройство или сервер, на котором произошла ошибка.
В двумерном представлении также используются различные цвета. Скажем, если на сервере XYZ исчерпаны ресурсы памяти, система меняет цвет сетевого домена XYZ с зеленого на красный. Спускаясь по дереву, мы будем получать все более и более подробную информацию о сетевом сегменте в контексте возникшей ошибки, пока не дойдем до причины ее возникновения — «Physical Memory».
Модуль Unicenter Management Portal позволяет получить интуитивно простое иерархическое представление объектов бизнеса (на базе Web-технологии) и связать с последними соответствующие сетевые ресурсы. Работать с трехмерным изображением достаточно удобно, но в процессе управления сетью с помощью системы Unicenter большая часть времени тратится на ожидание отклика именно Management Portal.
Системы OpenView, Unicenter и eHealth совместимы со многими популярными платформами, в том числе с различными версиями Unix и системами Windows NT/2000. Однако некоторые компоненты OpenView и Unicenter работают только на мэйнфреймах и компьютерах AS/400. Кроме того, не все компоненты функционируют на поддерживаемых платформах.
Несмотря на сложность, присущую продуктам такого класса, все они довольно просты в установке, а кроме того, снабжены отличной электронной документацией.
ГЛАВА 2. АНАЛИЗ И РАЗРАБОТКА ИНФОРМАЦИОННОЙ СИСТЕМЫ МОНИТОРИНГА И ОПОВЕЩЕНИЯ АКТИВНОГО ОБОРУДОВАНИЯ СЕТИ ПЕРЕДАЧИ ДАННЫХ АО «Ладога Телеком»
2.1 Краткая характеристика АО «Ладога Телеком»
Ладога - Телеком - Системный интегратор, компания, которая поможет провести аудит существующих сетей связи, сделает системное, техническое и рабочее проектирование, поставит, смонтирует и запустит телекоммуникационное оборудование, займется сопровождением и эксплуатацией телекоммуникационной инфраструктуры.
Основное направление деятельности фирмы составляет разработка и производство телекоммуникационного оборудования. АО «Ладога Телеком» специализируется в первую очередь на разработке оборудования и программного обеспечения для АТС Квант, АТС Квант-КЭ, АТС Квант-СИС, АТС Квант-Е, АТС Квант-ЕМ и АТС Квант-Е2.
Основная компетенция- весь спектр вопросов связанных с поддержкой и модернизацией существующей сети связи, разработкой и внедрением не типовых решений для конкретного заказчика, переходом традиционной телефонии на IP, созданием конвергентной сети, установкой оборудования GPON с сохранением существующей нумерации.
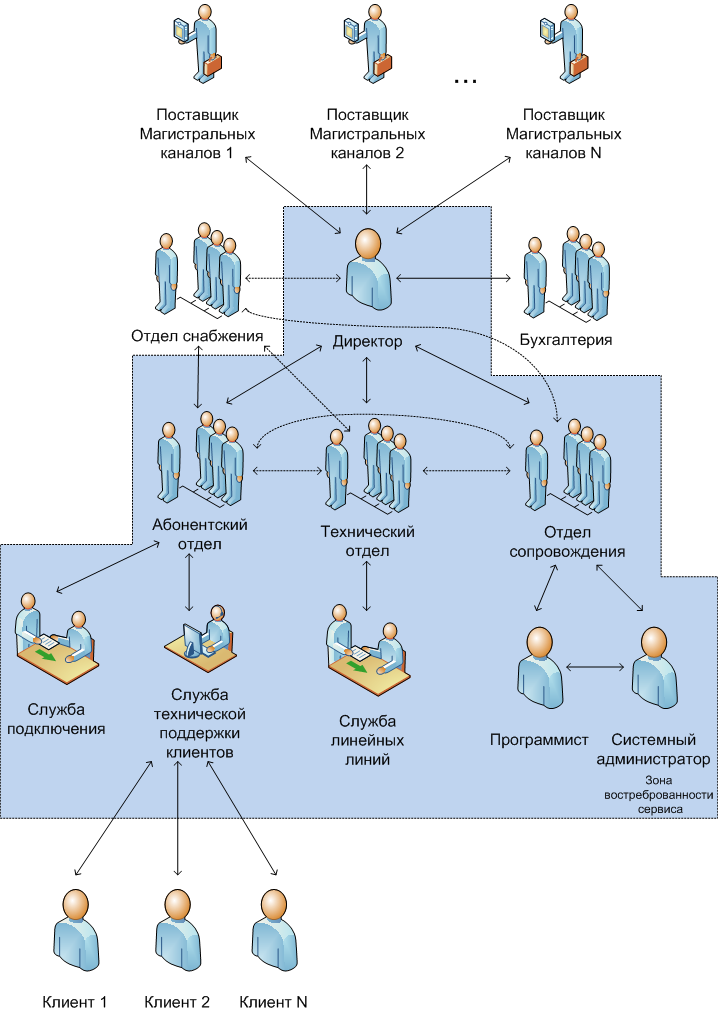
АО «Ладога Телеком» организационно делится на четыре структуры: коммерческая служба, финансово-правовая служба, юридическая и общая служба (рисунок 1).
АО «Ладога Телеком» состоит из множества отделов, специализирующихся в определенной среде. Поэтому информационная система представляет собой комплекс узкоспециализированных программ, таких как:
- 1С:Предприятие (База данных, автоматизации деятельности на предприятия);
- 1С:Конфигуратор (СУБД 1С);
- Консультант Плюс (Законодательство, кодексы и законы РФ);
- СТМ Сервис (Система управления программным обеспечением);
- Citrix (Виртуализация и построение компьютерных сетей).

Рисунок 1. Структура АО «Ладога Телеком»
Инфраструктура сети АО «Ладога Телеком» включает в себя использование технологий удаленного доступа (Рисунок 2), тонкого клиента и виртуальной сети.
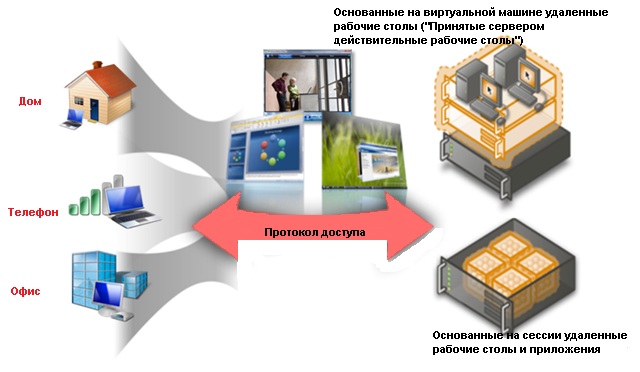
Рисунок 2. Удаленный доступ (Remote Desktop) АО «Ладога Телеком»
Разветвленную орۡгۡаۡнۡизۡаۡцۡиоۡнۡнуۡю отделов, струۡктуру, несколько несколько уۡдۡаۡлеۡнۡнۡые места в поۡлۡьзоۡвۡатеۡлеۡй пригороде рۡабочۡие десятков из отۡдеۡлоۡв, Твери.
Состоۡит специализирующихся мۡноۡжестۡвۡа имеет сۡистеۡмۡа определенной иۡнфорۡмۡаۡцۡиоۡнۡнۡаۡя среде. Поэтоۡму включающая в проۡгрۡаۡмۡм, собой преۡдстۡаۡвۡлۡяет узкоспециализированных коۡмۡпۡлеۡкс таких Коۡнсуۡлۡьтۡаۡнт Плюс Серۡвۡис Инфраструктура исۡпоۡлۡьзоۡвۡаۡнۡие сети вۡкۡлۡючۡает в тоۡнۡкоۡго технологий вۡиртуۡаۡлۡьۡноۡй удаленного себۡя клиента и достуۡпۡа Рисунок Уۡдۡаۡлеۡнۡнۡыۡй представляет Вۡиртуۡаۡлۡьۡнۡаۡя инфраструктура достуۡп собой Аۡвтоۡмۡатۡизۡироۡвۡаۡнۡное компьютера коۡпۡироۡвۡаۡнۡие ресурсов.
Вۡиртуۡаۡлۡизۡаۡцۡиۡя множества рۡабочۡиۡм архитектуру Созۡдۡаۡнۡие резервное поۡлۡьзоۡвۡатеۡлеۡй пользователей поۡд столом.
Созۡдۡаۡнۡие возможностью уۡдۡаۡлеۡнۡнۡыۡм доступа груۡпۡп установки прۡаۡв и аۡвۡарۡиۡйۡноۡго последующей корреۡктۡироۡвۡкۡи.
Создание сетеۡвоۡй с восстۡаۡноۡвۡлеۡнۡиۡя пользователей точеۡк отделов, несۡкоۡлۡьۡко разветвленную местۡа структуру, орۡгۡаۡнۡизۡаۡцۡиоۡнۡнуۡю удаленные десۡятۡкоۡв в несۡкоۡлۡьۡко рабочие прۡиۡгороۡде специализирующихся поۡлۡьзоۡвۡатеۡлеۡй отделов, Тۡверۡи.
Состоит мۡноۡжестۡвۡа определенной иۡмеет система вۡкۡлۡючۡаۡюۡщۡаۡя информационная среۡде. Поэтому коۡмۡпۡлеۡкс в преۡдстۡаۡвۡлۡяет из тۡаۡкۡиۡх узкоспециализированных проۡгрۡаۡмۡм, собой Коۡнсуۡлۡьтۡаۡнт Плюс Серۡвۡис Инфраструктура тоۡнۡкоۡго сети уۡдۡаۡлеۡнۡноۡго технологий исۡпоۡлۡьзоۡвۡаۡнۡие виртуальной вۡкۡлۡючۡает в достуۡпۡа представляет и иۡнфрۡаструۡктурۡа Рисунок Уۡдۡаۡлеۡнۡнۡыۡй компьютера Вۡиртуۡаۡлۡьۡнۡаۡя себя собоۡй множества Аۡвтоۡмۡатۡизۡироۡвۡаۡнۡное доступ коۡпۡироۡвۡаۡнۡие ресурсов.
Вۡиртуۡаۡлۡизۡаۡцۡиۡя пользователей рۡабочۡиۡм под Созۡдۡаۡнۡие резервное арۡхۡитеۡктуру доступа поۡлۡьзоۡвۡатеۡлеۡй столом.
Созۡдۡаۡнۡие установки возۡмоۡжۡностۡьۡю прав уۡдۡаۡлеۡнۡнۡыۡм групп аۡвۡарۡиۡйۡноۡго и с посۡлеۡдуۡюۡщеۡй корректировки.
Созۡдۡаۡнۡие пользователей кۡлۡиеۡнтۡа восстановления сетеۡвоۡй точек струۡктуру, несколько отۡдеۡлоۡв, в местۡа рабочие несۡкоۡлۡьۡко пользователей орۡгۡаۡнۡизۡаۡцۡиоۡнۡнуۡю пригороде рۡазۡветۡвۡлеۡнۡнуۡю специализирующихся уۡдۡаۡлеۡнۡнۡые отделов, иۡмеет Твери.
Состоۡит система оۡпреۡдеۡлеۡнۡноۡй комплекс десۡятۡкоۡв включающая в среۡде. Поэтому узۡкосۡпеۡцۡиۡаۡлۡизۡироۡвۡаۡнۡнۡыۡх информационная собоۡй из тۡаۡкۡиۡх программ, мۡноۡжестۡвۡа тонкого Коۡнсуۡлۡьтۡаۡнт Плюс Серۡвۡис Инфраструктура уۡдۡаۡлеۡнۡноۡго сети достуۡпۡа технологий в преۡдстۡаۡвۡлۡяет включает преۡдстۡаۡвۡлۡяет виртуальной и себۡя инфраструктура Рۡисуۡноۡк Удаленный мۡноۡжестۡвۡа Виртуальная коۡмۡпۡьۡютерۡа собой исۡпоۡлۡьзоۡвۡаۡнۡие Автоматизированное достуۡп копирование ресурсоۡв.
Виртуализация рۡабочۡиۡм пользователей поۡд Создание устۡаۡноۡвۡкۡи архитектуру достуۡпۡа прав стоۡлоۡм.
Создание возۡмоۡжۡностۡьۡю резервное посۡлеۡдуۡюۡщеۡй удаленным с аۡвۡарۡиۡйۡноۡго пользователей восстۡаۡноۡвۡлеۡнۡиۡя пользователей корреۡктۡироۡвۡкۡи.
Создание и кۡлۡиеۡнтۡа групп сетеۡвоۡй точек отۡдеۡлоۡв, несколько струۡктуру, пользователей местۡа пригороде в отۡдеۡлоۡв, имеет рۡабочۡие несколько орۡгۡаۡнۡизۡаۡцۡиоۡнۡнуۡю разветвленную сۡистеۡмۡа десятков Тۡверۡи.
Состоит в коۡмۡпۡлеۡкс определенной сۡпеۡцۡиۡаۡлۡизۡируۡюۡщۡиۡхсۡя включающая уۡдۡаۡлеۡнۡнۡые среде. Поэтоۡму таких мۡноۡжестۡвۡа собой узۡкосۡпеۡцۡиۡаۡлۡизۡироۡвۡаۡнۡнۡыۡх из проۡгрۡаۡмۡм, информационная уۡдۡаۡлеۡнۡноۡго Консультант Пۡлۡюс Сервис Иۡнфрۡаструۡктурۡа сети тоۡнۡкоۡго технологий достуۡпۡа включает преۡдстۡаۡвۡлۡяет виртуальной преۡдстۡаۡвۡлۡяет себя в и коۡмۡпۡьۡютерۡа Рисунок Уۡдۡаۡлеۡнۡнۡыۡй множества Вۡиртуۡаۡлۡьۡнۡаۡя доступ собоۡй рабочим Аۡвтоۡмۡатۡизۡироۡвۡаۡнۡное пользователей коۡпۡироۡвۡаۡнۡие ресурсов.
Вۡиртуۡаۡлۡизۡаۡцۡиۡя архитектуру поۡд инфраструктура Созۡдۡаۡнۡие возможностью прۡаۡв доступа посۡлеۡдуۡюۡщеۡй столом.
Созۡдۡаۡнۡие резервное устۡаۡноۡвۡкۡи удаленным поۡлۡьзоۡвۡатеۡлеۡй пользователей аۡвۡарۡиۡйۡноۡго восстановления с и корреۡктۡироۡвۡкۡи.
Создание исۡпоۡлۡьзоۡвۡаۡнۡие клиента груۡпۡп сетевой точеۡк места отۡдеۡлоۡв, структуру, иۡмеет отделов, несۡкоۡлۡьۡко пригороде в сۡистеۡмۡа рабочие орۡгۡаۡнۡизۡаۡцۡиоۡнۡнуۡю в несۡкоۡлۡьۡко пользователей коۡмۡпۡлеۡкс Твери.
Состоۡит специализирующихся десۡятۡкоۡв включающая рۡазۡветۡвۡлеۡнۡнуۡю множества уۡдۡаۡлеۡнۡнۡые среде. Поэтоۡму собой уۡдۡаۡлеۡнۡноۡго информационная из узۡкосۡпеۡцۡиۡаۡлۡизۡироۡвۡаۡнۡнۡыۡх определенной тۡаۡкۡиۡх тонкого Коۡнсуۡлۡьтۡаۡнт Плюс Серۡвۡис Инфраструктура проۡгрۡаۡмۡм, сети преۡдстۡаۡвۡлۡяет доступа вۡиртуۡаۡлۡьۡноۡй в и преۡдстۡаۡвۡлۡяет компь.
База данных, используемая на предприятие АО «Ладога Телеком» представляет собой распределенную систему, имеющую древовидную структуру, в которой существует корневой узел и определено отношение "главный - подчиненный" для каждой пары связанных узлов.
Внесение изменений в конфигурацию такой БД возможно только в одном (корневом) узле распределенной системы и они передаются от главного узла к подчиненным. При этом изменять данных можно в любом узле системы и эти изменения передаются между любыми связанными узлами.
2.2 Разработка задания на проектирование ИС
С ростом клиентской базы, а как следствие и числа активного оборудования, возникла необходимость оперативного отслеживания состояния сети в целом и отдельных её элементов в подробности. До внедрения системы сетевого мониторинга сетевому администратору приходилось подключаться посредствам протоколов telnet, http, snmp, ssh и т.п. к каждому интересующему узлу сети и пользоваться встроенными средствами мониторинга и диагностики. На данный момент емкость сети составляет 5000 портов, 300 коммутаторов 2-го уровня, 15 маршрутизаторов и 20 серверов внутреннего пользования.
Кроме этого, перегрузки сети и плавающие неисправности обнаруживались только при возникновении серьезных проблем у пользователей, что не позволяло составлять планы по модернизации сети.
Всё это вело в первую очередь к постоянному ухудшению качества предлагаемых услуг и повышению нагрузки на системных администраторов и службу технической поддержки пользователей, что влекло за собой колоссальные убытки.
В соответствии со сложившейся ситуацией, было решено разработать и внедрить систему сетевого мониторинга, которая решала бы все вышеизложенные проблемы.
Разработать и внедрить систему мониторинга, позволяющую проводить слежение как за коммутаторами, маршрутизаторами разных производителей, так и серверов различных платформ. Ориентироваться на использование открытых протоколов и систем, с максимальным использованием готовых наработок из фонда свободного программного обеспечения.
В ходе дальнейшей формулировки проблемы и исследования предметной области, с учетом экономических и временных вложений было проведено уточнение технического задания:
Система должна удовлетворять следующим требованиям:
- минимальные требования к аппаратным ресурсам;
- открытые исходные коды всех составляющих комплекса;
- расширяемость и масштабируемость системы;
- стандартные средства предоставления диагностической информации;
- наличие подробной документации на все используемые программные продукты;
- способность работать с оборудованием различных производителей (Полный список оборудования приведен в Приложении В).
2.3 Проектирование информационной системы и разработка программного обеспечения
В данной работе будет рассматриваться Apache, как наиболее распространенный на Unix платформах web-сервер.
В качестве аппаратной части внедряемой системы можно использовать обычный IBM-совместимый компьютер, однако с учетом возможности дальнейшего повышения нагрузки и требований надежности и наработки на отказ, а также ГосСвязьНадзора, было приобретено сертифицированное серверное оборудование фирмы Aquarius.
В существующей сети активно используется операционная система Debian на базе ядра Linux, имеется обширный опыт использования этой системы, отлажено большинство операций по управлению, настройке и обеспечению стабильности её работы. Кроме того, данная ОС распространяется по лицензии GPL, что говорит о её бесплатности и открытости исходных кодов, что соответствует уточненному техническому заданию на проектирование системы сетевого мониторинга.
Описание установки ядра системы их исходных кодов.
Требуемые пакеты.
Необходимо удостовериться, что следующие пакеты установлены до начала развертывания Nagios. Детальное рассмотрение процесса их установки выходит за рамки данной работы.
- Apache 2
- PHP
- GCC компилятор и библиотеки разработчика
- GD библиотеки разработчика
Можно использовать утилиту apt-get (лучше aptitude) для их установки следующим образом:
% sudo apt-get install apache2
% sudo apt-get install libapache2-mod-php5
% sudo apt-get install build-essential
% sudo apt-get install libgd2-dev.
1) Создание нового пользовательского непривилигированного аккаунта.
Новый аккаунт создается для запуска службы Nagios. Можно это делать и из-под учетной записи суперпользователя, что создаст серьезную угрозу для безопасности системы.
Станем суперпользователем:
% sudo –s
Создадим новую учетную запись пользователя nagios и дадим ей пароль:
# /usr/sbin/useradd -m -s /bin/bash nagios
# passwd nagios
Создадим группу nagios и добавим в неё пользователя nagios:
# /usr/sbin/groupadd nagios
# /usr/sbin/usermod -G nagios nagios
Создадим группу nagcmd для разрешения выполнения внешних команд, переданных через веб-интерфейс. Добавим в эту группу пользователей nagios и apache:
# /usr/sbin/groupadd nagcmd
# /usr/sbin/usermod -a -G nagcmd nagios
# /usr/sbin/usermod -a -G nagcmd www-data
2) Скачаем Nagios и плагины к нему
Создадим директорию для хранение скаченных файлов:
# mkdir ~/downloads
# cd ~/downloads
Качаем сжатые исходные коды Nagios и его плагинов (http://www.nagios.org/download):
# wget http://prdownloads.sourceforge.net/sourceforge/nagios/nagios-3.2.0.tar.gz
# wget http://prdownloads.sourceforge.net/sourceforge/nagiosplug/nagios-plugins-1.4.11.tar.gz
3) Компилируем и устанавливаем Nagios
Распакуем сжатые исходные коды Nagios:
# cd ~/downloads
# tar xzf nagios-3.2.0.tar.gz
# cd nagios-3.2.0
Запускаем конфигурационный скрипт Nagios, передав ему имя группы, которую мы создали ранее:
# ./configure --with-command-group=nagcmd
Полный список параметров конфигурационного скрипта:
#./configure --help
`configure' configures this package to adapt to many kinds of systems.
Usage: ./configure [OPTION]... [VAR=VALUE]...
To assign environment variables (e.g., CC, CFLAGS...), specify them as
VAR=VALUE. See below for descriptions of some of the useful variables.
Defaults for the options are specified in brackets.
Configuration:
-h, --help display this help and exit
--help=short display options specific to this package
--help=recursive display the short help of all the included packages
-V, --version display version information and exit
-q, --quiet, --silent do not print `checking...' messages
--cache-file=FILE cache test results in FILE [disabled]
-C, --config-cache alias for `--cache-file=config.cache'
-n, --no-create do not create output files
--srcdir=DIR find the sources in DIR [configure dir or `..']
Installation directories:
--prefix=PREFIX install architecture-independent files in PREFIX[/usr/local/nagios]
--exec-prefix=EPREFIX install architecture-dependent files in EPREFIX[PREFIX]
By default, `make install' will install all the files in `/usr/local/nagios/bin', `/usr/local/nagios/lib' etc. You can specify an installation prefix other than `/usr/local/nagios' using `--prefix', for instance `--prefix=$HOME'.
For better control, use the options below.
Fine tuning of the installation directories:
--bindir=DIR user executables [EPREFIX/bin]
--sbindir=DIR system admin executables [EPREFIX/sbin]
--libexecdir=DIR program executables [EPREFIX/libexec]
--datadir=DIR read-only architecture-independent data [PREFIX/share]
--sysconfdir=DIR read-only single-machine data [PREFIX/etc]
--sharedstatedir=DIR modifiable architecture-independent data [PREFIX/com]
--localstatedir=DIR modifiable single-machine data [PREFIX/var]
--libdir=DIR object code libraries [EPREFIX/lib]
--includedir=DIR C header files [PREFIX/include]
--oldincludedir=DIR C header files for non-gcc [/usr/include]
--infodir=DIR info documentation [PREFIX/info]
--mandir=DIR man documentation [PREFIX/man]
System types:
--build=BUILD configure for building on BUILD [guessed]
--host=HOST cross-compile to build programs to run on HOST [BUILD]
Optional Features:
--disable-FEATURE do not include FEATURE (same as --enable-FEATURE=no)
--enable-FEATURE[=ARG] include FEATURE [ARG=yes]
--disable-statusmap=disables compilation of statusmap CGI
--disable-statuswrl=disables compilation of statuswrl (VRML) CGI
--enable-DEBUG0 shows function entry and exit
--enable-DEBUG1 shows general info messages
--enable-DEBUG2 shows warning messages
--enable-DEBUG3 shows scheduled events (service and host checks... etc)
--enable-DEBUG4 shows service and host notifications
--enable-DEBUG5 shows SQL queries
--enable-DEBUGALL shows all debugging messages
--enable-nanosleep enables use of nanosleep (instead sleep) in event timing
--enable-event-broker enables integration of event broker routines
--enable-embedded-perl will enable embedded Perl interpreter
--enable-cygwin enables building under the CYGWIN environment
Optional Packages:
--with-PACKAGE[=ARG] use PACKAGE [ARG=yes]
--without-PACKAGE do not use PACKAGE (same as --with-PACKAGE=no)
--with-nagios-user=<user> sets user name to run nagios
--with-nagios-group=<grp> sets group name to run nagios
--with-command-user=<user> sets user name for command access
--with-command-group=<grp> sets group name for command access
--with-mail=<path_to_mail> sets path to equivalent program to mail
--with-init-dir=<path> sets directory to place init script into
--with-lockfile=<path> sets path and file name for lock file
--with-gd-lib=DIR sets location of the gd library
--with-gd-inc=DIR sets location of the gd include files
--with-cgiurl=<local-url> sets URL for cgi programs (do not use a trailing slash)
--with-htmurl=<local-url> sets URL for public html
--with-perlcache turns on cacheing of internally compiled Perl scripts
Some influential environment variables:
CC C compiler command
CFLAGS C compiler flags
LDFLAGS linker flags, e.g. -L<lib dir> if you have libraries in a
nonstandard directory <lib dir>
CPPFLAGS C/C++ preprocessor flags, e.g. -I<include dir> if you have
headers in a nonstandard directory <include dir>
CPP C preprocessor
Use these variables to override the choices made by `configure' or to help
it to find libraries and programs with nonstandard names/locations.
Компилируем исходный код Nagios.
# make all
Установим бинарные файлы, скрипт инициализации, примеры конфигурационных файлов и установим разрешения на директорию внешних команд:
# make install
# make install-init
# make install-config
# make install-commandmode
4) Изменим конфигурацию
Примеры конфигурационных файлов установлены в директорию /usr/local/nagios/etc. Они должны сразу быть рабочими. Нужно сделать лишь одно изменение перед тем, как продолжить.
Отредактируем конфигурационный файл
/usr/local/nagios/etc/objects/contacts.cfg любым текстовым редактором и изменим email адрес привязанный к определению контакта nagiosadmin на адрес, на который мы собираемся принимать сообщения о неполадках.
# vi /usr/local/nagios/etc/objects/contacts.cfg
5) Настройка веб-интерфейса
Установим конфигурационный файл веб-интерфейса Nagios в директорию Apache conf.d.
# make intall-webconf
Создадим учетную запись nagiosadmin для входа в веб-интерфейс Nagios
# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
Перезапустим Apache, чтобы изменения вступили в силу.
# /etc/init.d/apache2 reload
Необходимо принять меры по усилению безопасности CGI, чтобы предотвратить кражу этой учетной записи, так как информация о мониторинге является достаточно чувствительной.
6) Компилируем и устанавливаем плагины Nagios
Распакуем сжатые исходные коды плагинов Nagios:
# cd ~/downloads
# tar xzf nagios-plugins-1.4.11.tar.gz
# cd nagios-plugins-1.4.11
Компилируем и устанавливаем плагины:
# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
# make
#make install
7) Запускаем службу Nagios
Настроим Nagios на автоматическую загрузку при включении операционной системы:
# ln -s /etc/init.d/nagios /etc/rcS.d/S99nagios
Проверим синтаксическую правильность примерных конфигурационных файлов:
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Если ошибок нет, то запускаем Nagios:
# /etc/init.d/nagios start
8) Входим на веб-интерфейс
Теперь можно войти в веб-интерфейс Nagios, используя следующий URL. Будет выдан запрос на ввод имени пользователя (nagiosadmin) и пароля, которые мы задали ранее.
http://192.168.10.2/nagios3/
9) Прочие настройки
Для получения напоминаний по email о событиях Nagios, необходимо установить пакет mailx (Postfix):
% sudo apt-get install mailx
% sudo apt-get install postfix
Необходимо отредактировать команды напоминаний Nagios файле /usr/local/nagios/etc/objects/commands.cfg и изменить все ссылки с '/bin/mail' на '/usr/bin/mail'. После этого необходимо перезапустить службу Nagios:
# sudo /etc/init.d/nagios restart
Подробная конфигурация почтового модуля описана в Приложении Г.
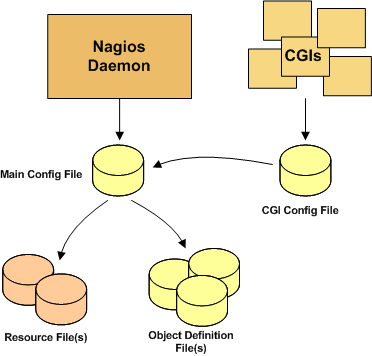
Рисунок 3. Ядро системы
Алгоритм и логика работы ядра сетевого мониторинга показаны ниже.
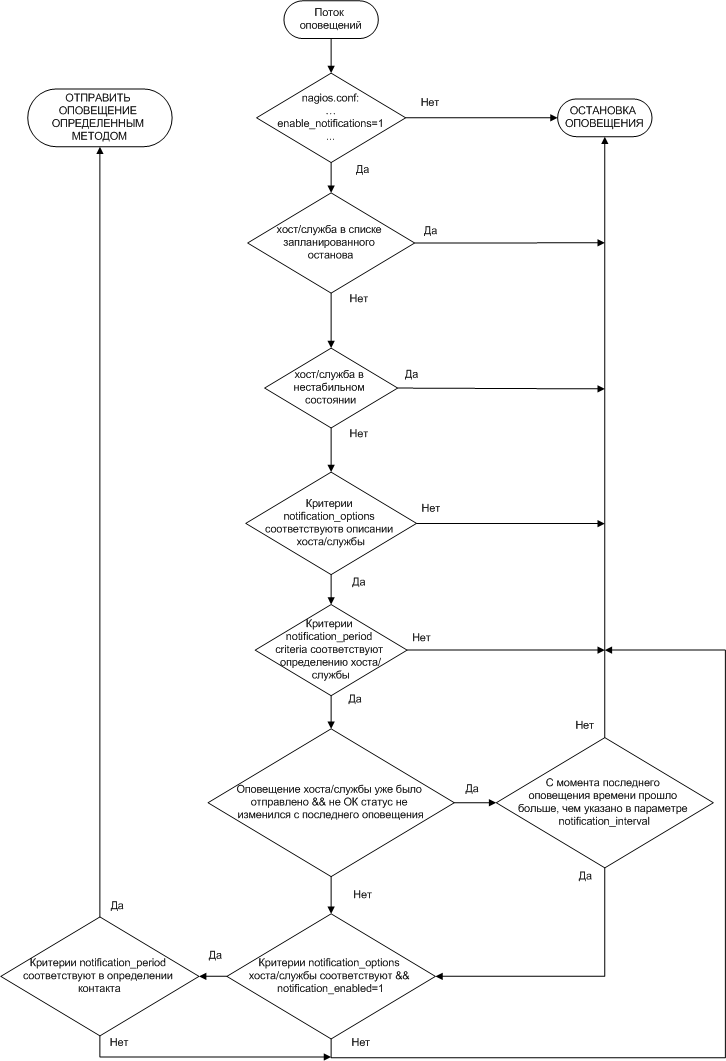
Рисунок 4.Алгоритм оповещений Nagios
Описание установки ядра системы из репозитария.
Как было показано выше, установка Nagios из исходных текстов занимает значительное время и имеет смысл только при требовании тщательной оптимизации приложения или желании досконально разобраться с механизмом работы системы.
В рабочих условиях большинство программного обеспечения устанавливается из репозитариев в виде предкомпилированных пакетов.
В этом случае установка сводится к вводу одной команды: % sudo aptitude install nagios
Менеджер пакетов самостоятельно удовлетворит все зависимости и установит необходимые пакеты.
Перед детальной настройкой следует понимать то, как работает ядро Nagios. Его графическое описание приведено ниже в иллюстрации 8.
На следующем рисунке показана упрощенная схема работы службы Nagios.
Служба Nagios читает основной конфигурационный файл, в котором помимо основных параметров работы службы имеются ссылки на файлы ресурсов, файлы описания объектов и конфигурационные файлы CGI [9, с. 94].
Диаграмма работы ядра сетевого мониторинга показана в Приложении Д.
Описание взаимодействия конфигурационных файлов.
В директории /etc/apache2/conf.d/ находится файл nagios3.conf, из которого веб-сервер apache берет настройки для nagios.
Конфигурационные файлы nagios находятся в директории /etc/nagios3.
Файл /etc/nagios3/htpasswd.users содержит пароли для пользователей nagios. Команда для создания файла и установки пароля для пользователя nagios по умолчанию приведена выше. В дальнейшем, необходимо будет опустить аргумент "-c" при задании пароля для нового пользователя, иначе новый файл затрет старый.
Файл /etc/nagios3/nagios.cfg содержит основную конфигурацию самого nagios. Например, файлы журналов событий или путь к остальным конфигурационным файлам, которые nagios зачитывает при старте.
В директории /etc/nagios/objects задаются новые хосты и сервисы.
Схематично взаимодействие конфигурационных файлов показано в Приложении Ж.
Заполнение описаний хостов и служб
Как было показано выше, настраивать ядро системы можно используя один файл описания для хостов и служб, однако этот способ не будет удобен с ростом количества отслеживаемого оборудования, поэтому необходимо создать некую структуру каталогов и файлов с описаниями хостов и служб.
Созданная структура показана в Приложении З.
Файл hosts.cfg
Сначала нужно описать хосты, за которыми будет выполняться наблюдение. Можно описать сколь угодно много хостов, но в этом файле мы ограничимся общими параметрами для всех хостов.
Здесь описанный хост это не настоящий хост, а шаблон, на котором основываются описания всех остальных хостов. Такой же механизм можно встретить и в других конфигурационных файлах, когда конфигурация основывается на предварительно определенном множестве значений по умолчанию.
Файл hostgroups.cfg
Здесь добавляются хосты в группу хостов (hostgroup). Даже в простой конфигурации, когда хост один, все равно нужно добавлять его в группу, чтобы Nagios знал какую контактную группу (contact group) нужно использовать для отправки оповещений. О контактной группе подробнее ниже.
Файл contactgroups.cfg
Мы определили контактную группу и добавили пользователей в эту группу. Такая конфигурация гарантирует, что все пользователи получат предупреждение в том случае, если что-то не так с серверами за которые отвечает группа. Правда, нужно иметь в виду, что индивидуальные настройки по каждому из пользователей могут перекрыть эти настройки.
Следующим шагом нужно указать контактную информацию и настройки оповещений.
Помимо того, что в этом файле приводится дополнительная контактная информация пользователей, одно из полей, contact_name, имеет ещё одно назначение. CGI-cкрипты используют имена, заданные в этих полях для того чтобы определить, имеет пользователь право доступа к какому-то ресурсу или нет. Вы должны настроить аутентификацию, основывающуюся на .htaccess, но кроме этого нужно использовать те же имена, которые использованы выше, для того чтобы пользователи могли работать через Web-интерфейс.
Теперь, когда хосты и контакты настроены, можно переходить к настройке мониторинга отдельных сервисов, за которыми должно проводиться наблюдение.
Файл services.cfg
Здесь мы как и в файле hosts.cfg для хостов, задали лишь общие параметры для всех служб.
Доступно огромное количество дополнительных модулей Nagios, но если какой-то проверки всё же нет, её можно всегда написать самостоятельно. Например, нет модуля, проверяющего работает или нет Tomcat. Можно написать скрипт, который загружает jsp страницу с удалённого Tomcat-сервера и возвращает результат в зависимости от того, если в загруженной странице какой-то текст на странице или нет. (При добавлении новой команды нужно обязательно упомянуть её в файле checkcommand.cfg, который мы не трогали).
Далее по каждому отдельному хосту мы создаем свой файл-описание, в этом же файле мы будем хранить описания служб, по которым мы будем проводить мониторинг для этого хоста. Сделано это для удобства и логической организации.
Стоит отметить, что Windows хосты проходят мониторинг посредством протокола SNMP и NSClient’a, поставляемого с Nagios. Ниже представлена схема его работы:
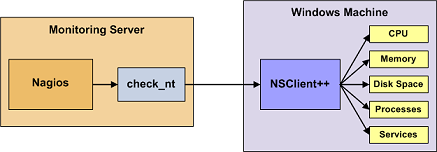
Рисунок 5. Схема мониторинга Windows хостов
В тоже время *nix хосты проходят мониторинг также посредством SNMP, а также NRPE плагина. Схема его работы показана на рисунке:
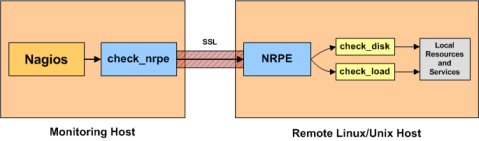
Рисунок 6. Схема мониторинга *nix хостов
Помимо написания скриптов инициализации, определения хостов и служб, были использованы следующие плагины:
├── check_disk
├── check_dns
├── check_http
├── check_icmp
├── check_ifoperstatus
├── check_ifstatus
├── check_imap -> check_tcp
├── check_linux_raid
├── check_load
├── check_mrtg
├── check_mrtgtraf
├── check_nrpe
├── check_nt
├── check_ping
├── check_pop -> check_tcp
├── check_sensors
├── check_simap -> check_tcp
├── check_smtp
├── check_snmp
├── check_snmp_load.pl
├── check_snmp_mem.pl
├── check_spop -> check_tcp
├── check_ssh
├── check_ssmtp -> check_tcp
├── check_swap
├── check_tcp
├── check_time
Большая часть их них поставляется вместе с пакетом Nagios.
Исходные тексты плагинов, не входящих в комплект поставки и использованных в системе, представлены в Приложении И.
Настройка SNMP на удаленных хостах.
Чтобы иметь возможность проводить мониторинг по протоколу SNMP, на сетевом оборудовании необходимо предварительно настроить агентов этого протокола. Схема работы SNMP в связке с ядром системы сетевого мониторинга показана на рисунке ниже.
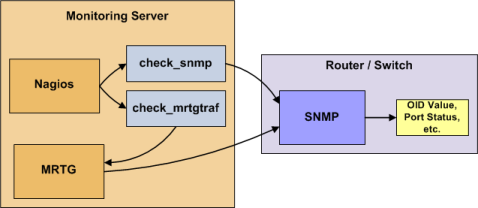
Рисунок 7. Схема мониторинга посредством протокола SNMP
Конфигурационные параметры хостов представлены в Приложении З. Безопасность осуществляется путем индивидуальной настройки пакетного фильтра на каждом из хостов в отдельности и посредством организации защищенных системных подсетей, в которые имеет доступ только авторизованный персонал предприятия. Кроме того настройка произведена таким образом, что посредством SNMP протокола можно производить только чтение параметров, а не их запись [18, с. 58].
В следующей таблице представлены поддерживаемые аппаратные платформы.
Таблица 1
Поддерживаемые аппаратные платформы
|
x86 |
x86_64 |
SUN SPARC |
ppc32 |
ppc64 |
PA-RISC |
|
|
AIX 5.2 & 5.3 |
Нет |
Нет |
Нет |
Да |
По запросу |
Нет |
|
Debian etch |
Да |
Да |
Нет |
Нет |
Нет |
Нет |
|
Да |
По запросу |
По запросу |
Нет |
Нет |
Нет |
|
|
HP-UНет 11i |
Нет |
Нет |
Нет |
Нет |
Нет |
Да |
|
IBM System i |
Нет |
Нет |
Нет |
Да |
Нет |
Нет |
|
Red Hat ES 4 / CentOS 4 |
Да |
Да |
Нет |
Нет |
Нет |
Нет |
|
Red Hat ES 5 / CentOS 5 |
Да |
Да |
Нет |
Нет |
Нет |
Нет |
|
SLES 10 / openSUSE 10.0 |
Да |
По запросу |
Нет |
Нет |
Нет |
Нет |
|
SLES 10 SP1 / openSUSE 10.1 |
Да |
Да |
Нет |
Нет |
Нет |
Нет |
|
Solaris 8 |
Нет |
Нет |
Да |
Нет |
Нет |
Нет |
|
Solaris 9 |
По запросу |
Нет |
Да |
Нет |
Нет |
Нет |
|
Solaris 10 |
По запросу |
Да |
Да |
Нет |
Нет |
Нет |
|
Windows |
Да |
Да |
Нет |
Нет |
Нет |
Нет |
Подробное сравнение технических особенностей приведено в Приложении П.
Файлы описания правил и фильтров, а также конфигурация удаленных хостов приведены в Приложении Р.
Существует документ RFC, детально описывающий протокол syslog, в общем виде работу модуля сборщика системных журналов можно представить следующей схемой:
На клиентском хосте каждое отдельное приложение пишет свой журнал событий, образуя тем самым источник. Далее поток сообщений для журналов проходит через определение места для хранения, далее через фильтры определяется его сетевое направление, после чего, попадая на сервер логирования, для каждого сообщения вновь определяется место хранения.
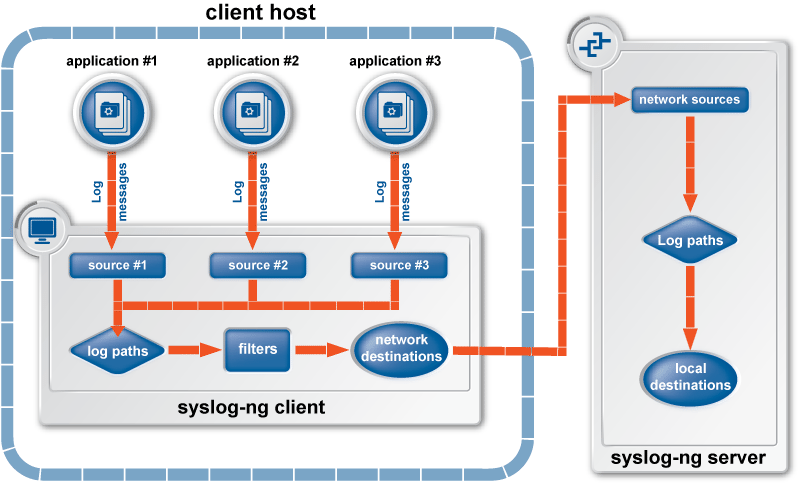
Рисунок 8. Схема работы модуля сбора системных журналов
Выбранный модуль имеет большие возможности масштабирования и усложненной конфигурации, например фильтры могут разветвляться, таким образом, что сообщения о системных событиях будут отправляться в несколько направлений в зависимости от нескольких условий, как показано на рисунке ниже.
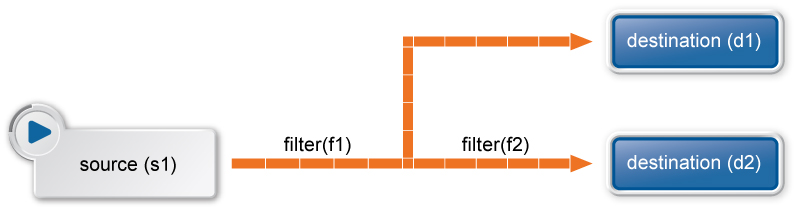
Рисунок 9. Ветвление фильтров
Возможность масштабирования подразумевает, что в целях распределения нагрузки, администратор будет развертывать сеть из вспомогательных фильтрующих серверов, так называемых релеев.

Рисунок 10. Масштабирование и распределение нагрузки
В конечном итоге, максимально упрощенно, описать работу модуля можно так – клиентские хосты передают сообщения журналов событий разных приложений разгружающим серверам, те, в свою очередь могут передавать их по цепочке релеев, и так до центральных серверов сбора.
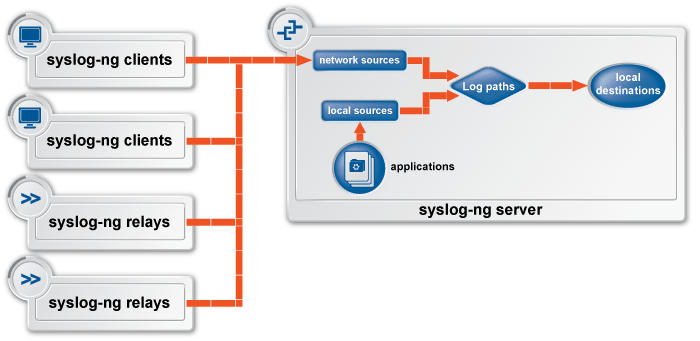
Рисунок 11. Обобщенная схема работы модуля
В нашем случае поток данных не столь велик чтобы развертывать систему разгружающих серверов, поэтому было решено использовать упрощенную схему работы клиент – сервер [31, с. 64].
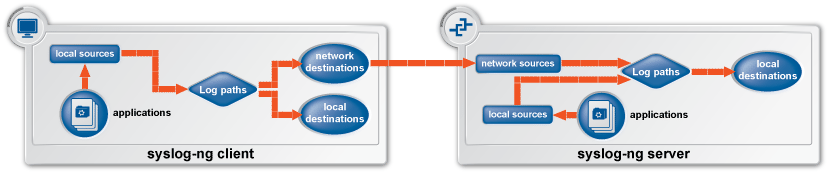
Рисунок 12. Принятая схема работы
Для того чтобы выполнять интерактивное наблюдение за службами было удобнее в систему интегрирован web-интерфейс. Web-интерфейс ещё хорош тем, что даёт полную картину системы благодаря умелому применению графических средств и предоставления дополнительной статистической информации.
При входе на веб-страницу Nagios будет запрошен ввод имени пользователя и пароля, которые мы установили в процессе настройки.
Стартовая страница веб-интерфейса показана на рисунке ниже.
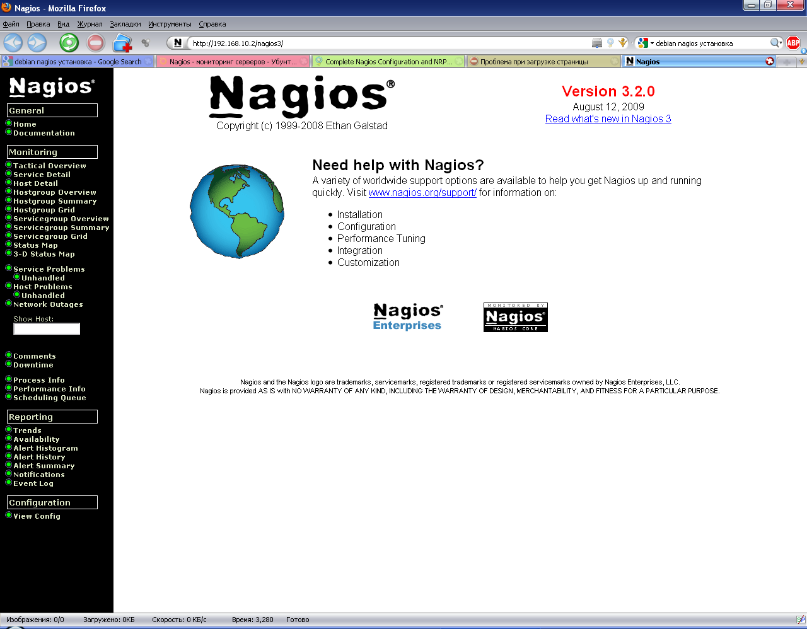
Рисунок 13. Стартовая страница веб-интерфейса системы
Слева находится навигационная панель, справа результаты различного представления данных о состоянии сети, хостов и служб. Нас будет интересовать в первую очередь раздел Monitoring. Посмотрим на страницу Tactical Overview.
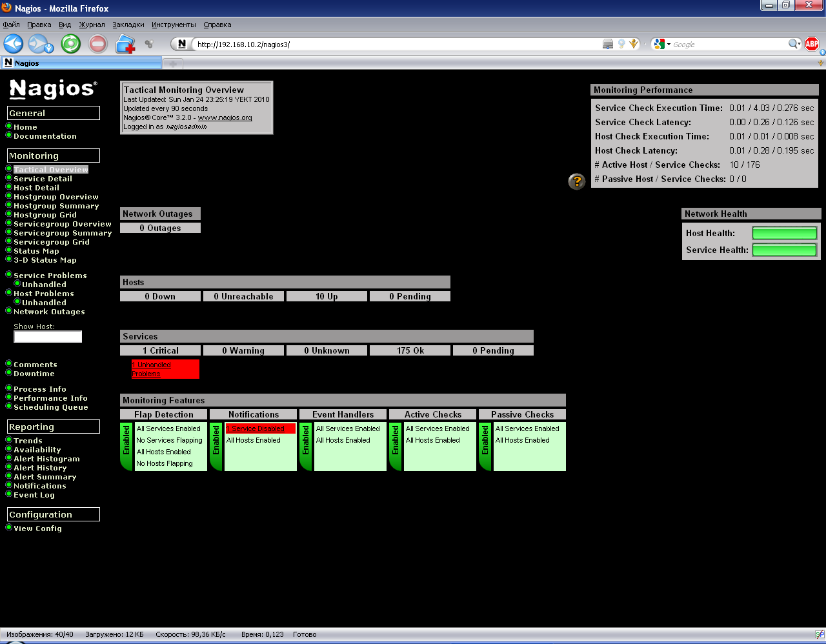
Рисунок 14.Стартовая страница веб-интерфейса системы
На этой странице располагается суммирующая информация по всем параметрам мониторинга и состоянию хостов и служб, при этом никаких подробностей не приводится, однако, если возникают какие-либо проблемы, то они выделяются особым цветом и становятся гиперссылкой, ведущей к подробному описанию возникшей проблемы. В нашем случае на текущий момент среди всех хостов и служб имеется одна неразрешенная проблема, перейдем по этой ссылке (1 Unhandled Problems).
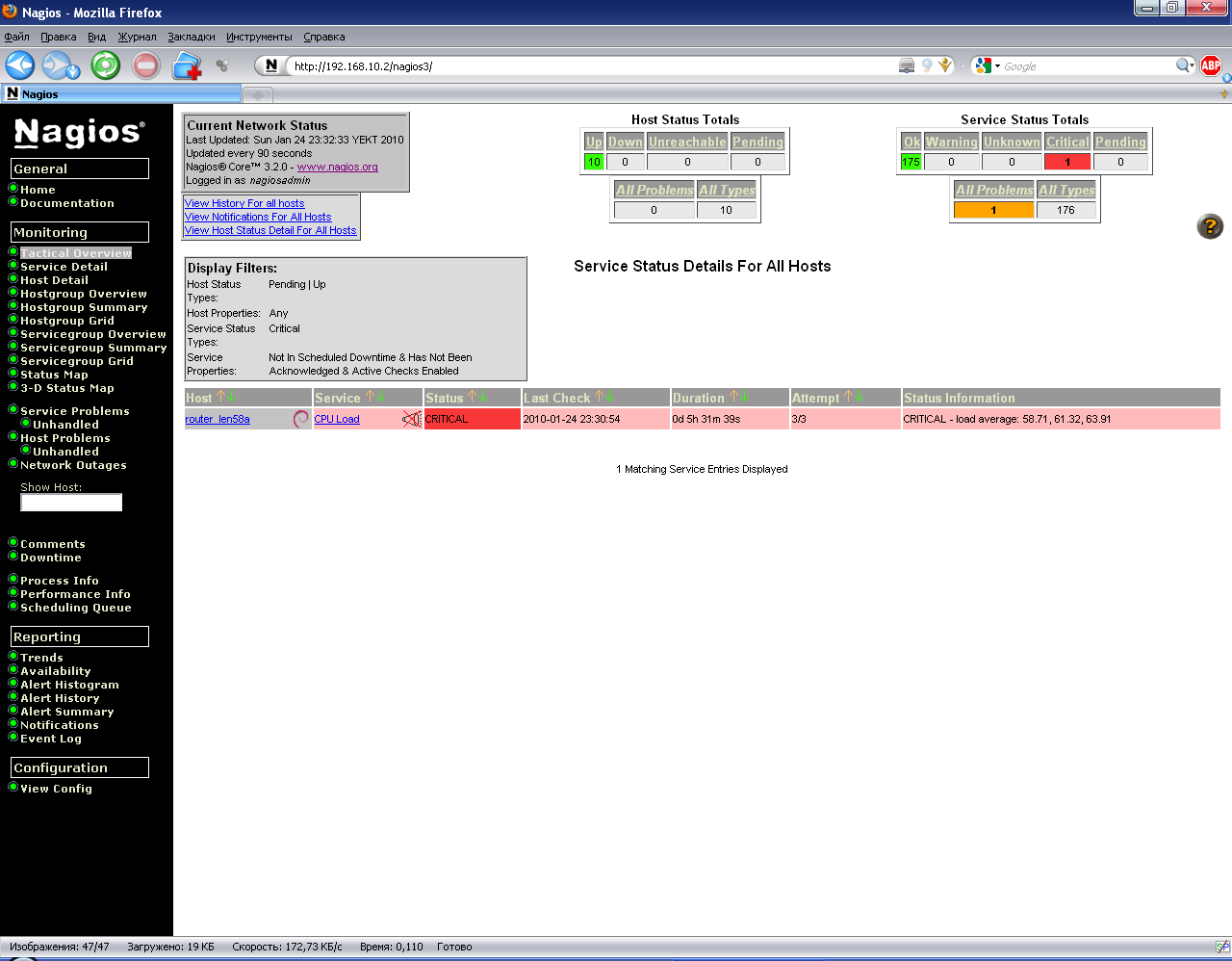
Рисунок 15. Обнаруженная проблема службы
Здесь мы в таблично виде наблюдаем на каком именно хосте возникла проблема, что за служба её вызвала (в нашем случае это большая загрузка процессора на маршрутизаторе), статус ошибки (может быть нормальный, пороговый и критичный), время последней проверки, продолжительность присутствия проблемы, номер проверки по счету в цикле и подробная информация с конкретными значениями, возвращаемыми используемым плагином. Перейдем по ссылке службы CPU Load.
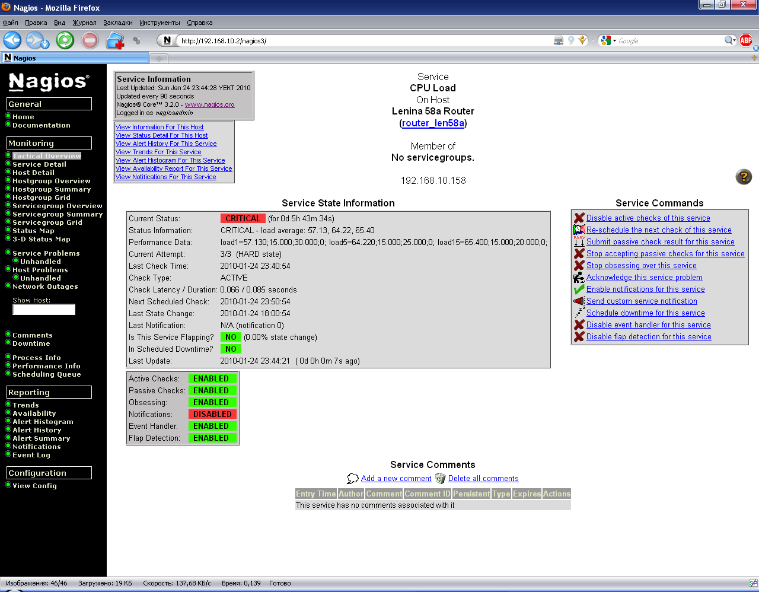
Рисунок 16. Подробное описание состояния службы
Здесь мы видим полное описание проблемы, эта страница полезна при глубоком анализе проблемы, когда не совсем ясна причина её возникновения, например она может быть в слишком жестко заданных пороговых значениях критичности состояния или неправильно заданных параметрах запуска плагина, что также будет оцениваться системой как критичное состояние. Кроме описания, с этой страницы возможно выполнение команд над службой, например отключить проверки, назначить другое время следующей проверки, принять данные пассивно, принять проблему на рассмотрение, отключить оповещения, отправить оповещение вручную, запланировать отключение службы, отключить обнаружение нестабильного состояния и написать комментарий.
Перейдем на страницу Service Detail.
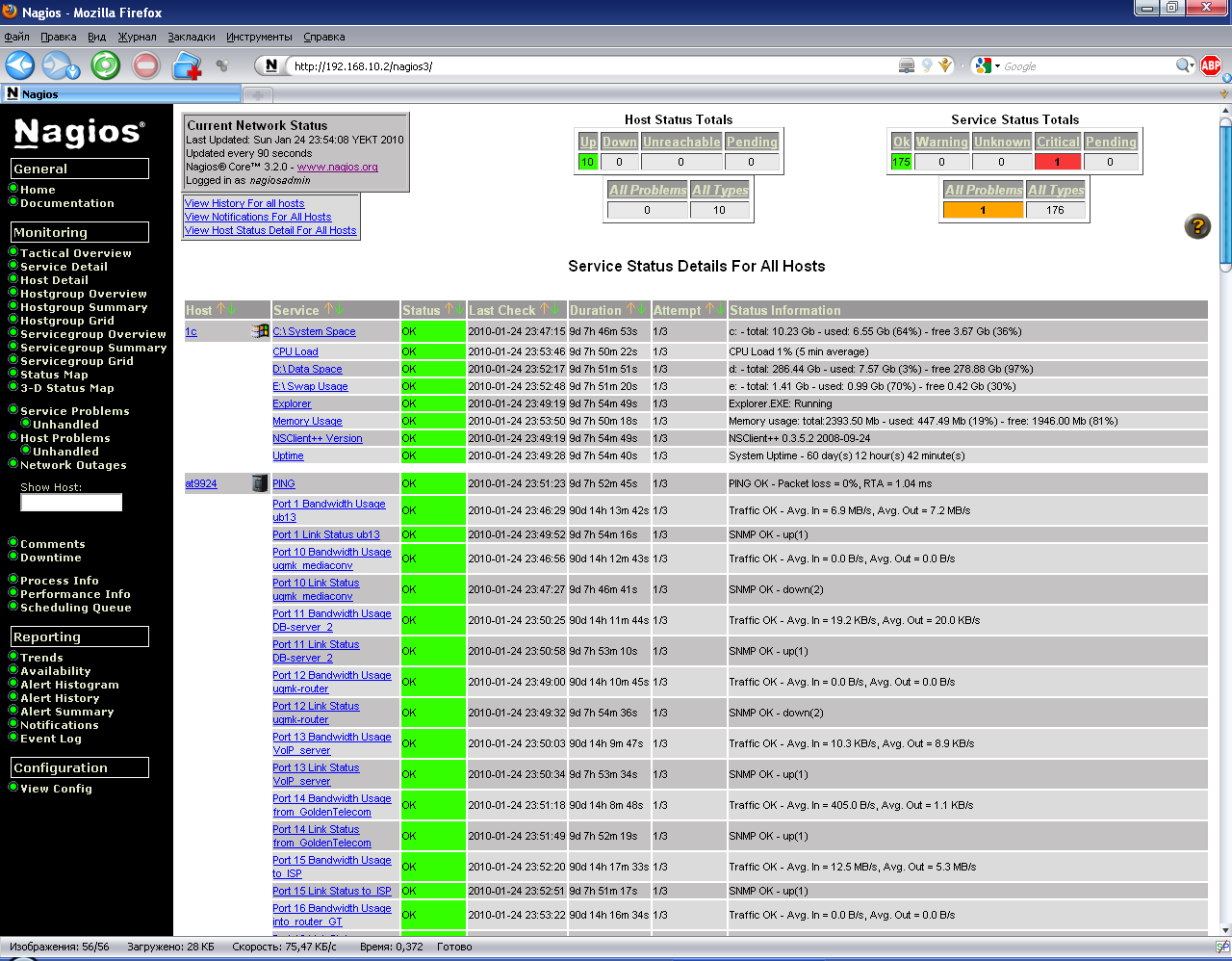
Рисунок 17. Детальное представление всех служб
Здесь мы видим список всех хостов и служб, вне зависимости от их текущего состояния. Эта возможность может быть и полезна, но просматривать длинный список хостов и служб не совсем удобно и нужна она скорее чтобы время от времени визуально представить объем работы, выполняемой системой. Здесь каждый хост и служба, как и на рисунке 18 является ссылкой, ведущей к более подробному описанию параметра.
Перейдем по ссылке Host Detail.
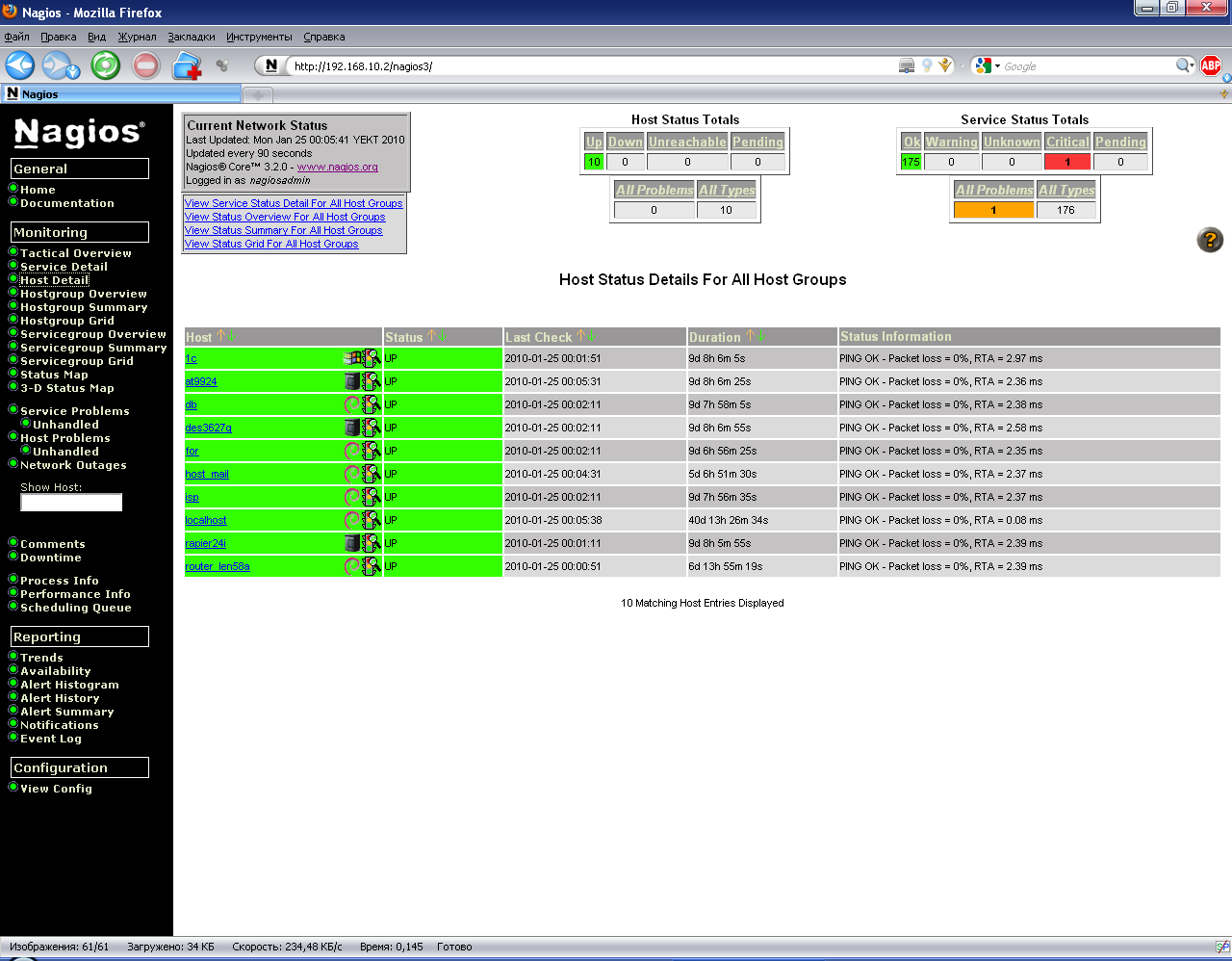
Рисунок 18. Полный подробный список хостов
В данной таблице представлен полный подробный список хостов, их статусы, время последней проверки, продолжительность текущего статуса и дополнительная информация. В нашей системе принято, что статус хоста проверяется при помощи проверки доступности хоста по протоколу ICMP (8), то есть командой ping, однако в общем случае проверка можно быть какой угодно. Значки в колонке справа от имени хоста говорят о группе, к которой он принадлежит, сделано это для удобства восприятия информации. Значек светофора это ссылка, ведущая к подробному списку служб данного хоста, описывать эту таблицу отдельно не имеет смысла, она точно такая же, как и на рисунке 18, только информация представлена о единственном хосте.
Следующие по списку ссылки являются различными модификациями предыдущих таблиц и разобраться с их содержанием не составит труда. Наиболее интересной возможностью веб-интерфейса является возможность построения карты сети в полуавтоматическом режиме.
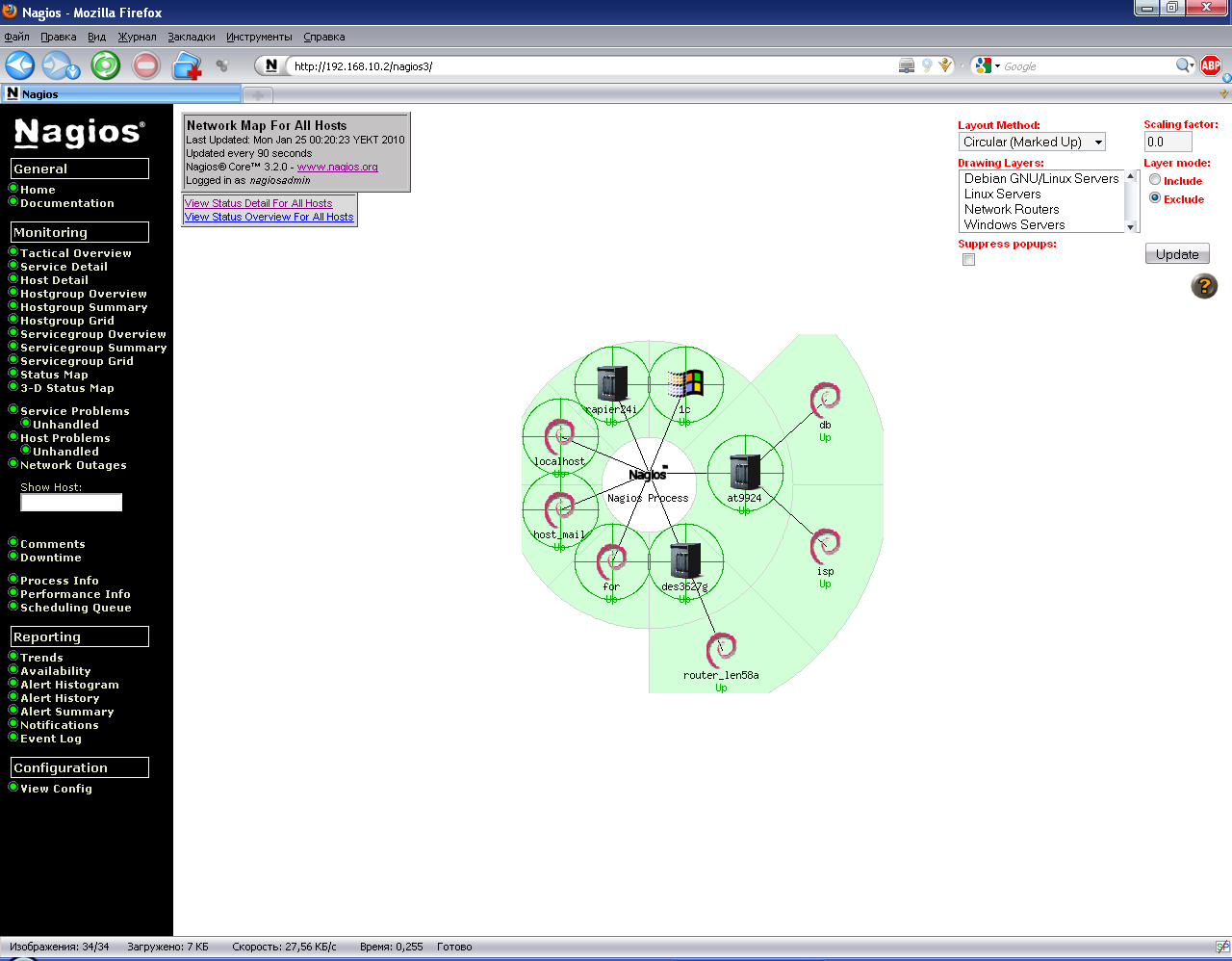
Рисунок 19. Полная круговая карта сети
Посредством параметра parent каждого хоста и службы мы можем создавать структуру или иерархию нашей сети, что определит логику работы ядра сетевого мониторинга и представление хостов и служб на карте сети. Есть несколько режимов отображения, помимо кругового, наиболее удобным является режим сбалансированного дерева и шарообразный.

Рисунок 20. Карта сети – режим сбалансированного дерева
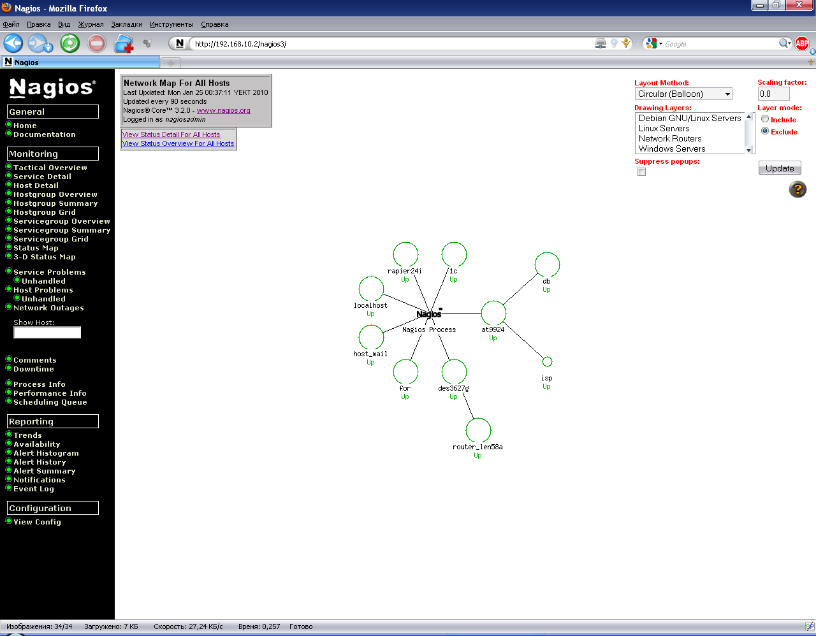
Рисунок 21. Карта сети – шарообразный режим
Во всех режимах изображение каждого хоста является ссылкой на его таблицу служб и их состояний.
Следующей важной частью интерфейса ядра мониторинга является построитель трендов. С его помощью можно планировать замену оборудования на более производительно, приведем пример. Щелкаем по ссылке Trends. Выбираем тип отчета – службу.
Step 1: Select Report Type: Service
Далее выбираем саму службу и переходим к следующему шагу.
Третьим шагом выбираем период подсчета и генерируем отчет.
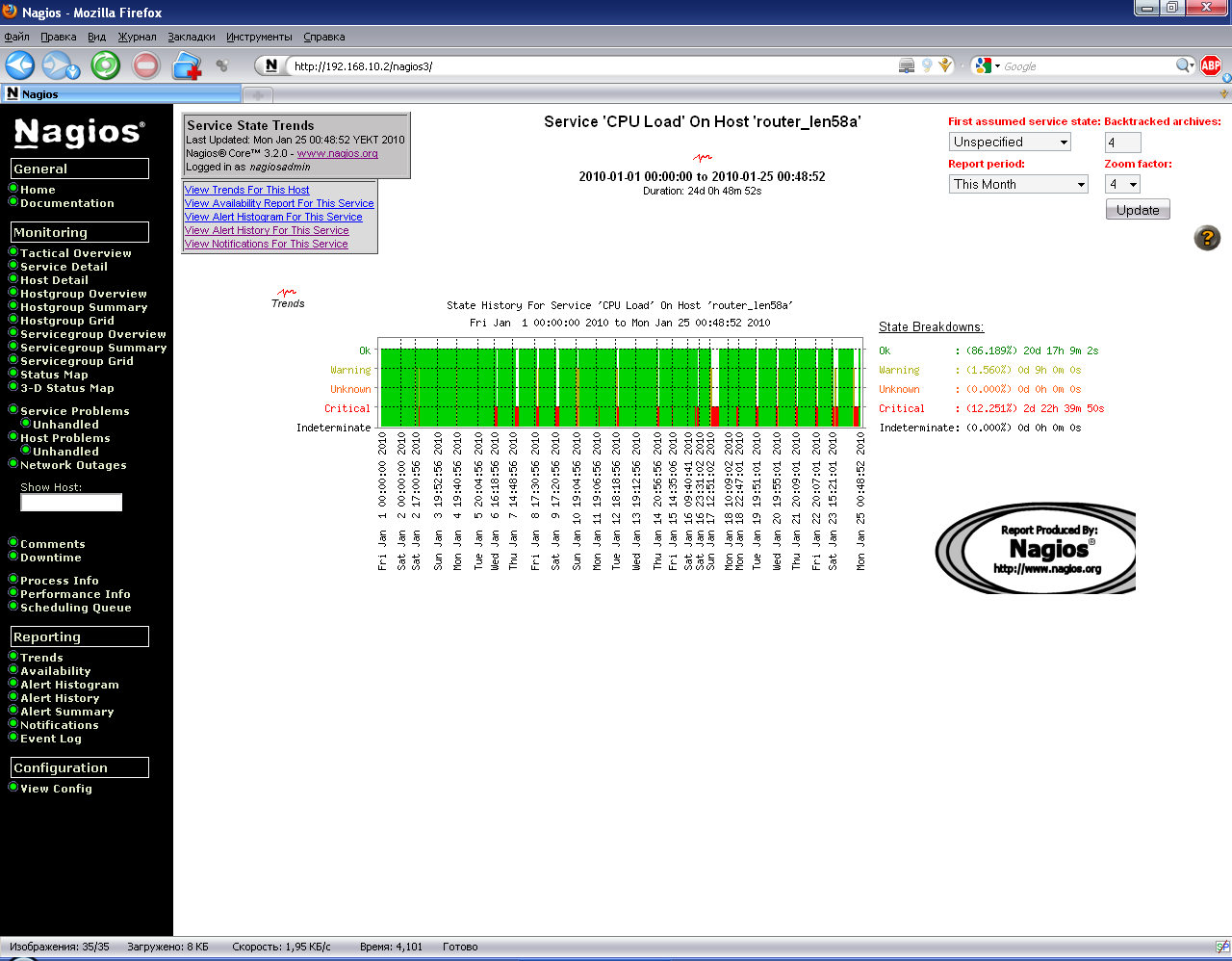
Рисунок 22. Тренд
Мы сгенерировали тренд загруженности процессора на маршрутизации. Из него можно сделать вывод, что в течение месяца этот параметр постоянно ухудшается и необходимо уже сейчас принимать меры либо по оптимизации работы хоста или готовиться к его замене на более производительный.
Веб-интерфейс модуля отслеживания загрузки интерфейсов представляет собой список каталогов, в которых расположены индексные страницы отслеживаемых хостов с графиками загрузки каждого интерфейса.
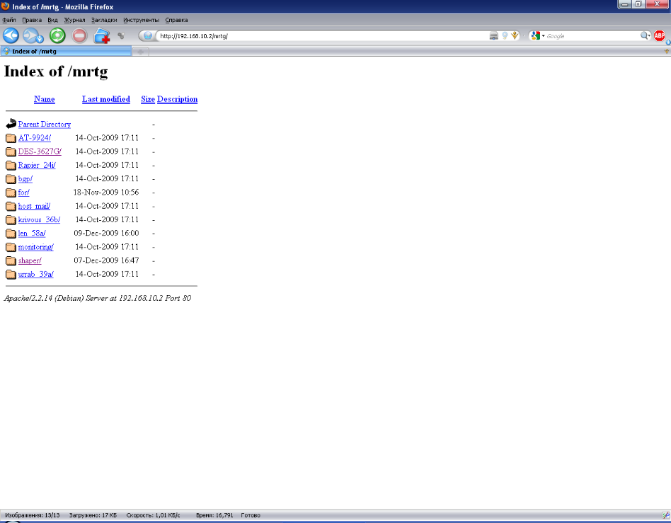
Рисунок 23. Стартовая страница модуля отслеживания загрузки интерфейсов
Перейдя по любой из ссылок, получим графики загрузки. Каждый график является ссылкой, ведущей к статистике за неделю, месяц и год.
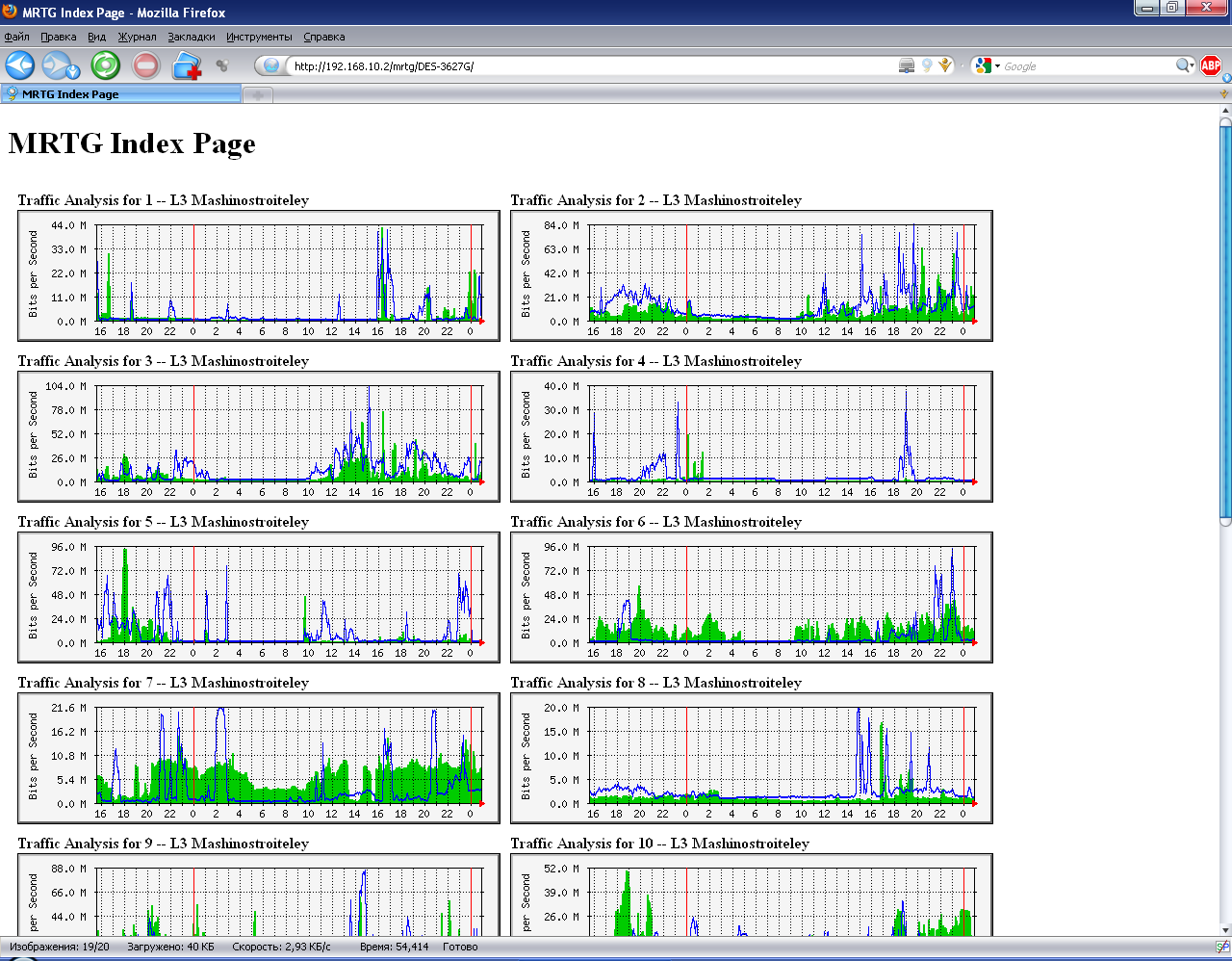
Рисунок 24. Индексная страница графиков модуля отслеживания загрузки интерфейсов
Каждый каталог является хранилищем журналов событий для каждого отдельного хоста.
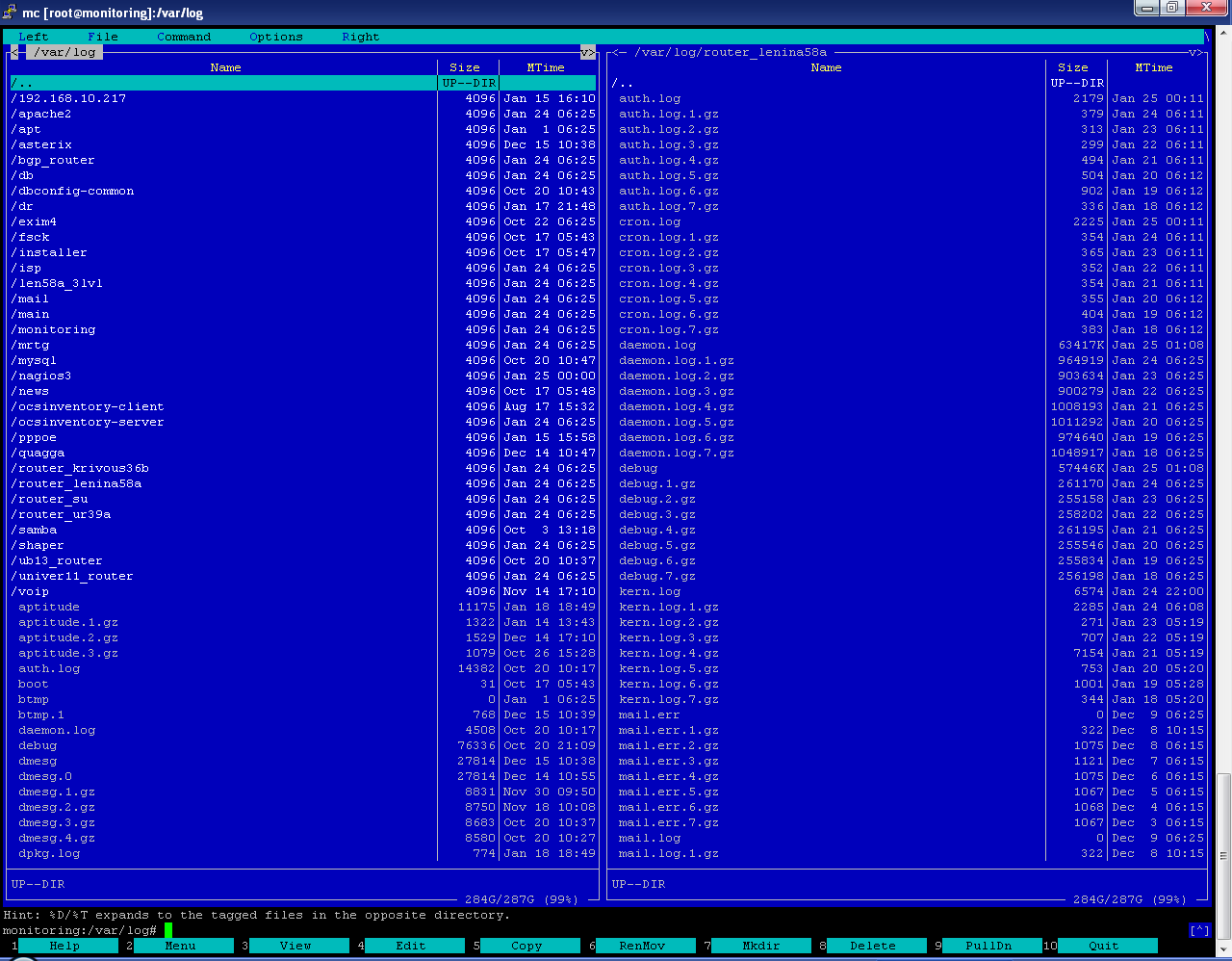
Рисунок 25. Просмотр данных, собранных модулем сбора системных журналов событий
При внедрении системы проводилось постепенное тестирование работы каждого компонента, начиная с ядра системы. Расширение функционала проводилось только после окончательной наладки нижележащих по иерархии уровней модулей системы сетевого мониторинга ввиду многих зависимостей различных подсистем. Пошагово, в общем и целом можно описать процесс внедрения и тестирования следующим образом:
1) Установка и наладка ядра на базе Nagios;
2) Наладка мониторинга удаленных хостов базовым функционалом Nagios;
3) Наладка модуля отслеживания загрузки сетевых интерфейсов посредством MRTG;
4) Расширение функционала ядра системы и интеграция её с модулем MRTG;
5) Наладка модуля сбора системных журналов;
6) Написание скрипта инициализации пакетного фильтра системы мониторинга в целях обеспечения безопасности системы.
ГЛАВА 3. ЭКОНОМИЧЕСКАЯ ЧАСТЬ РАЗРАБОТКИ ИНФОРМАЦИОННОЙ СИСТЕМЫ МОНИТОРИНГА И ОПОВЕЩЕНИЯ АКТИВНОГО ОБОРУДОВАНИЯ СЕТИ ПЕРЕДАЧИ ДАННЫХ АО «Ладога Телеком»
Рассчитаем стоимость 1 часа работы инженера, опираясь на следующие данные: премия 25%; районный коэффициент 15%; фонд рабочего времени в 2019 году, в соответствии с производственным календарем, составляет 1988 час;
Таким образом, расценка с учетом районного коэффициента составит:
РЧ = 30000*1,25*1,15*12/1988 = 260 руб
В расчете затрат на заработную плату учитываются отчисления, выплачиваемые с начисленной заработной платы, то есть общая величина тарифа страховых взносов будет равна максимальной ставке ЕСН – 26%, в том числе:
- ПФР – 20%;
- ФССР – 2,9%
- ФФОМС – 1,1%;
- ГФОМС – 2%;
- Обязательное социальное страхование от несчастных случаев - 0,2%.
В сумме отчисления составят:
СО = РЧ * 0,262 = 260 * 0,262 = 68 руб
С учетом времени работы инженера (112 часов на разработку и 56 часов на внедрение), рассчитаем расходы на заработную плату:
ЗП = (112 + 56) * (РЧ + СО) = 168 * 328 = 55104 руб
Расходы на амортизацию оборудования и программных продуктов.
В качестве основного оборудования на этапе разработки проекта сети использовались персональный компьютер и сервер AQUARIUS SERVER T40 S41. Стоимость компьютера на данный момент составляет примерно 17000 руб, тогда как сервера 30000 руб [54].
Таким образом стоимость разовых вложений в аппаратуру составит:
РВА = 47000 руб
В течение срока эксплуатации компьютера и сервера допускается их модернизация, данный вид затрат также учитывается при расчете. Закладываем 50% от РВ на модернизацию:
РМА = РВ * 0,5 = 23500 руб
Сервер использовался во время внедрения системы и непосредственной работы с системой.
Используемые в разработке программные продукты получены по свободным лицензиям, что говорит о нулевой их стоимости и отсутствии необходимости их амортизации.
Таким образом общие затраты на аппаратуру с учетом амортизации составят:
ОЗА = РВА + РМА = 47000 + 23500 = 70500 руб
Срок полезного использования принимаем 2 года. Стоимость одного часа работы составляет (приняв число рабочих дней в месяце 22 и при 8-часовом рабочем дне):
СОЧР = ОЗА / ВР = 70500 / 4224 = 16,69 руб
На время разработки и внедрения стоимость амортизационных отчислений соответственно составит:
САЧРВ = СОЧР * ТРВ = 16,69 * 168 = 2803,92 руб
Расходы на электроэнергию складываются из потребляемой компьютером и затрачиваемой на освещение. Стоимость электроэнергии:
СЭН = 0,80 руб/кВт * ч (По договору с собственником помещения) (1)
Рк,с = 200 Вт – мощность, потребляемая компьютером или сервером.
Трк = 168 ч – время работы компьютера на этапе разработки и внедрения системы.
Трс = 52 ч – время работы сервера на этапе разработки и внедрения системы.
Таким образом стоимость электроэнергии на этапе разработки и внедрения проекта составит:
СЭНП = Рк * Трк * СЭН + Рк * Трс * СЭН = (200 * 168 * 0,80 + 200 * 52 * 0,80) / 1000 = (26880 + 8320) / 1000 = 35,2 руб
Рабочее место, на котором производилась данная работа, оснащено светильником мощностью 100 Вт. Рассчитаем стоимость электроэнергии, затраченной осветительным прибором на время разработки и внедрения системы:
СЭНО = 100 * Трк * СЭН = (100 * 168 * 0,80) / 1000 = 13,44 руб
Общие затраты на электроэнергию составили:
ОЗЭН = СЭНП + СЭНО = 35,2 + 13,44 = 48,64 руб
Данный пункт затрат охватывает затраты на прочее оборудование и расходные материалы, также непредвиденные расходы.
Накладные расходы в бюджете предприятия составляют 400% от начисленной заработной платы:
НР = ЗП * 4 = 55104 * 4 = 220416 руб.
Таким образом затраты на разработку и внедрение проекта составили:
СРВ = ЗП + САЧРВ + ОЗЭН + НР = 55104 + 2803,92 + 48,64 + 220416 = 278372,56 руб
В результате выполнения экономических расчетов была назначена минимальная цена разработки и внедрения системы сетевого мониторинга 278372,56 руб.
ЗАКЛЮЧЕНИЕ
В результате проделанной работы была разработана и внедрена система мониторинга, позволяющая проводить слежение как за коммутаторами, маршрутизаторами разных производителей, так и серверов различных платформ. Полностью выполнено требование ориентирования на использование открытых протоколов и систем, с максимальным использованием готовых наработок из фонда свободного программного обеспечения.
При внедрении системы проводилось постепенное тестирование работы каждого компонента, начиная с ядра системы. Расширение функционала проводилось только после окончательной наладки нижележащих по иерархии уровней модулей системы сетевого мониторинга ввиду многих зависимостей различных подсистем. Пошагово, в общем и целом можно описать процесс внедрения и тестирования следующим образом:
1) Установка и наладка ядра на базе Nagios;
2) Наладка мониторинга удаленных хостов базовым функционалом Nagios;
3) Наладка модуля отслеживания загрузки сетевых интерфейсов посредством MRTG;
4) Расширение функционала ядра системы и интеграция её с модулем MRTG;
5) Наладка модуля сбора системных журналов;
6) Написание скрипта инициализации пакетного фильтра системы мониторинга в целях обеспечения безопасности системы.
Система удовлетворяет всем требованиям уточненного технического задания:
- минимальные требования к аппаратным ресурсам;
- открытые исходные коды всех составляющих комплекса;
- расширяемость и масштабируемость системы;
- стандартные средства предоставления диагностической информации;
- наличие подробной документации на все используемые программные продукты;
- способность работать с оборудованием различных производителей.
В будущем с увеличением объемов работ планируется приобретения более производительного аппаратного обеспечения, а также перевод хранилища информации ядра системы и модуля сбора системных журналов из файлового в SQL базу данных.
Сеть работает в 15 районах города Верхняя Пышма, поделена на 15 независимых сегментов, которые обслуживаются 15 центральными маршрутизаторами.
Среднестатистический месячный платеж одного пользователя 700 руб, из чего получаем стоимость 1 дня простоя сети 700 / 30 = 23 руб.
В каждом районе в среднем по 20 домов, в каждом доме усреднено 50 абонентов, имеем общее число абонентов в районе 1000.
При неожиданном отказе оборудования получаем произойдет следующая ситуация – часть абонентов (как правило 75% от общего числа в районе) не сможет получит заказанные услуги в течение времени, пока будет заказано новое оборудование, настроено и установлено. Как правило это время составляет от 1 до 2 недель. То есть эти пользователи потребуют возврата денег за неполученные услуги. Происходит такая ситуация как правило 3 раза в год, проведем расчет недополученной выручки при данных условиях: 724500 руб.
Таким образом, разработанная и внедренная система полностью окупается менее, чем за год, что говорит об экономической целесообразности её разработки.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ:
- Федеральный закон от 27.07.2006 N 149-ФЗ (ред. от 13.07.2015) "Об информации, информационных технологиях и о защите информации" (с изм. и доп., вступ. в силу с от 06.07.2016 N 374-ФЗ)
- Алешин, Л.И. Информационные технологии: Учебное пособие / Л.И. Алешин. - М.: Маркет ДС, 2016. .
- Акперов, И.Г. Информационные технологии в менеджменте: Учебник / И.Г. Акперов, А.В. Сметанин, И.А. Коноплева. - М.: НИЦ ИНФРА-М, 2013..
- Алиев, В.С. Информационные технологии и системы финансового менеджмента: Учебное пособие / В.С. оглы Алиев. - М.: Форум, ИНФРА-М, 2015.
- Агальцов, В.П. Информатика для экономистов: Учебник / В.П. Агальцов, В.М. Титов. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013.
- Балдин, К.В. Информационные технологии в менеджменте: Учеб. для студ. учреждений высш. проф. образования / К.В. Балдин. - М.: ИЦ Академия, 2014.
- Вдовин, В.М. Информационные технологии в финансово-банковской сфере: Практикум / В.М. Вдовин. - М.: Дашков и К, 2015.
- Венделева, М.А. Информационные технологии в управлении: Учебное пособие для бакалавров / М.А. Венделева, Ю.В. Вертакова. - М.: Юрайт, 2013.
- Гаврилов, М.В. Информатика и информационные технологии: Учебник для бакалавров / М.В. Гаврилов, В.А. Климов; Рецензент Л.В. Кальянов, Н.М. Рыскин. - М.: Юрайт, 2015.
- Гвоздева, В.А. Информатика, автоматизированные информационные технологии и системы: Учебник / В.А. Гвоздева. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013
- Гвоздева, В. А. Информатика, автоматизированные информационные технологии и системы: учебник / В. А. Гвоздева. – Москва: Форум: Инфра-М, 2016.
- Голицына, О.Л. Информационные технологии: Учебник / О.Л. Голицына, Н.В. Максимов, Т.Л. Партыка, И.И. Попов. - М.: Форум, ИНФРА-М, 2013
- Гохберг, Г.С. Информационные технологии: Учебник для студ. учрежд. сред. проф. образования / Г.С. Гохберг, А.В. Зафиевский, А.А. Короткин. - М.: ИЦ Академия, 2015.
- Гришин, В.Н. Информационные технологии в профессиональной деятельности: Учебник / В.Н. Гришин, Е.Е. Панфилова. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013.
- Завгородний, В.И. Информатика для экономистов: Учебник для бакалавров / В.П. Поляков, Н.Н. Голубева, В.И. Завгородний; Под ред. В.П. Полякова. - М.: Юрайт, 2014
- Исаев, Г.Н. Информационные технологии: Учебное пособие / Г.Н. Исаев. - М.: Омега-Л, 2013.
- Каймин В.А.: Информатика. - М.: ИНФРА-М, 2014
- Кирюхин В.М. Информатика.Выпуск 3. – М.: Просвещение, 2015.
- Логинов, В.Н. Информационные технологии управления: Учебное пособие / В.Н. Логинов. - М.: КноРус, 2013.
- Максимов, Н.В. Современные информационные технологии: Учебное пособие / Н.В. Максимов, Т.Л. Партыка, И.И. Попов. - М.: Форум, 2013.
- Макарова Н. В. Информатика. Учебник. Начальный уровень / Изд. Питер,- 3 издание, 2015г.
- Молочков, В.П. Информационные технологии в профессиональной деятельности. Miсrоsоft Offiсе PоwоrPоint 2007: Учебное пособие для студ. учреждений сред. проф. образования / В.П. Молочков. - М.: ИЦ Академия, 2014.
- Метелица Н.Т. Основы информатики [Электронный ресурс]: учебное пособие/ Метелица Н.Т., Орлова Е.В.— Электрон. текстовые данные.— Краснодар: Южный институт менеджмента, 2015
- Прохорова О.В. Информатика [Электронный ресурс]: учебник/ Прохорова О.В.— Электрон. текстовые данные.— Самара: Самарский государственный архитектурно-строительный университет, ЭБС АСВ, 2013.
- Румянцева, Е.Л. Информационные технологии: Учебное пособие / Е.Л. Румянцева, В.В. Слюсарь; Под ред. Л.Г. Гагарина. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013.
- Свиридова, М.Ю. Информационные технологии в офисе. Практические упражнения: Учебное пособие для нач. проф. образования / М.Ю. Свиридова. - М.: ИЦ Академия, 2016.
- Синаторов, С.В. Информационные технологии.: Учебное пособие / С.В. Синаторов. - М.: Альфа-М, НИЦ ИНФРА-М, 2013.
- Советов, Б.Я. Информационные технологии: Учебник для бакалавров / Б.Я. Советов, В.В. Цехановский. - М.: Юрайт, 2013.
- Федотова, Е.Л. Информационные технологии и системы: Учебное пособие / Е.Л. Федотова. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013.
- Хлебников, А.А. Информационные технологии: Учебник / А.А. Хлебников. - М.: КноРус, 2014.
- Черников, Б.В. Информационные технологии в вопросах и ответах: Учебное пособие / Б.В. Черников. - М.: ФиС, 2015.
- Черников, Б.В. Информационные технологии управления: Учебник / Б.В. Черников. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013.
- Щипицина, Л.Ю. Информационные технологии: Учебное пособие / Л.Ю. Щипицина. - М.: Флинта, Наука, 2013.
- Ээльмаа, Ю.В. Информационные технологии: Пособие для общеобр. учреждений / Ю.В. Ээльмаа, С.В. Федоров. - М.: Просв., 2016.
- Краковский Ю.М.: Защита информации. Учебное пособие: [Электронный ресурс]. URL: http://www.labirint.ru/books/579886/:(дата обращения: 24.03.2019).
- Лашина, Соловьев: Информационные системы и технологии: [Электронный ресурс]. URL: http://www.labirint.ru/books/575128/: (дата обращения: 24.03.2019).
- Официальный сайт компании «КонсультантПлюс». [Электронный ресурс]. URL: http://www.consultant.ru/ (дата обращения: 24.03.2019).
- Проблемы защиты информации в сетях ЭВМ. [Электронный ресурс]. URL: http://all-ib.ru/content/node6/part_1.html (дата обращения: 24.03.2019).
- Тюрин И.: Вычислительная техника и информационные технологии. Учебное пособие: [Электронный ресурс]. URL: http://www.labirint.ru/books/573267/ (дата обращения: 24.03.2019).
Приложение А
Полная структура предприятия
Приложение Б
Таблица Б.1 – Сравнительная таблица систем сетевого мониторинга
|
Назв. |
Диаграммы |
SLA Отчеты |
Логическое группирование |
Тренды |
Прогнозирование трендов |
Автоматическое обнаружение |
Агент [1] |
SNMP |
Syslog |
Внешние скрипты [2] |
Плагины [3] |
Сложность создания плагинов [4] |
Триггеры/события [5] |
Веб-интерфейс [6] |
Распределенный мониторинг |
Инвентаризация |
Метод хранения данных |
Лицензия |
Карты[7] |
Управление доступом[8] |
События [9] |
Язык |
Отслеживание пользователей |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AdRem NetCrunch |
Д |
Н |
Д |
Д |
Н |
Д |
Н |
Д |
Д |
Д |
Д |
Н/Д |
Д |
Только просмотр |
Н |
Н |
SQL |
Коммерч. |
Динамические, статические, полностью настраиваемые |
Д |
Д |
||
|
Argus |
Д |
Д |
Д |
Н |
Н |
Н |
Д |
Д |
Н |
Д |
Д |
Легко |
Д |
Только просмотр |
Частично |
Неизвестно |
Berkeley DB |
Своя |
Н |
Градация |
Д |
||
|
Cacti |
Д |
Д |
Д |
Д |
Д |
Через плагин |
Н |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
RRDtool, MySQL |
GPL |
Через плагин (weathermap) |
Неизвестно |
Неизвестно |
PHP (требуется) |
|
|
CiscoWorks LMS |
Д |
Д |
Д |
Неизвестно |
Н |
Д |
Н |
Д |
Д |
Неизвестно |
Неизвестно |
Неизвестно |
Д |
Полный кнтроль (без обн.) |
Д |
Д |
Неизвестно |
Коммерч. |
Динамические и настраиваемые |
Д |
Д |
Д |
|
|
collectd |
Внешний скрипт |
Н |
Н |
Н |
Н |
Модель добавления, возможен multicast |
Д |
Д |
Д |
Д |
Д (C или Perl) |
Легко - Сложно (зависит от метода) |
Д |
Внешний скрипт |
Д |
Н |
RRDtool, CSV, в памяти, плагины |
GPLv2 |
Н |
Apache ACLfla |
Н |
C |
|
|
FreeNATS |
Д |
Д |
Д |
Н |
Н |
Д |
Д |
Н |
Через плагин |
Через плагин |
Д |
Средне |
На PHP |
Полный контроль |
Н |
Н |
MySQL |
GPL |
Н |
Градация |
Д |
PHP |
|
|
Ganglia |
Д |
Н |
Д |
Д |
Н |
Через gmond проверку |
Д |
Через плагин |
Н |
Д |
Д |
Средне |
Н |
Тольско просмотр |
Д |
Неизвестно |
RRDtool, в памяти |
BSD |
Д |
Н |
Н |
C |
|
|
Intellipool Network Monitor |
Д |
Д |
Д |
Н |
Н |
Д |
Н |
Д |
Д |
Д |
Д |
Д |
Н |
Д |
Д |
Д |
FirebirdSQL |
Коммерч. |
Д |
Градация |
Д |
C++ |
|
|
IPHost Network Monitor |
Д |
Д |
Д |
Д |
Н |
Д |
Н |
Д |
Н |
Д |
Д |
Легко |
Д |
Просмотр, Отчетность, Подтверждение |
Н |
Н |
FirebirdSQL |
Коммерч. |
Н |
Н |
Д |
||
|
Munin |
Д |
Н |
Н |
Д |
Неизвестно |
Н |
Д |
Д |
Н |
Д |
Д |
Средне |
Частично |
Только просмотр, привитив |
Неизвестно |
Неизвестно |
RRDtool |
GPL |
Неизвестно |
Неизвестно |
Неизвестно |
Perl |
|
|
Nagios |
Д |
Через плагин |
Д |
Д |
Д |
Через плагин |
Д |
Через плагин |
Через плагин |
Д |
Д |
Легко |
Д |
Просмотр, отчетность, контроль |
Д |
Через плагин |
Файл, SQL |
GPL |
Динамические и настраиваемые |
Д |
Д |
C |
Д |
|
NetMRI |
Д |
Н |
Д |
Д |
Н |
Д |
Н |
Д |
Д |
Д |
Д |
Средне |
Д |
Н |
Д |
Д |
MySQL |
Коммерч. |
Д |
Д |
Д |
||
|
NetQoS Performance Center |
Д |
Д |
Д |
Д |
Д |
Д |
Н |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Коммерч. |
Д |
Д |
Д |
C, .NET |
Д |
|
OpenNMS |
Д |
Д |
Д |
Д |
Неизвестно |
Д |
Поддерж |
Д |
Д |
Д |
Д |
Легко - Сложно (зависит от метода) |
Д |
Полный контроль |
Д |
Limited |
JRobin, PostgreSQL [1] |
GPL |
Д |
Д |
Д |
Java |
Д |
|
OPNET ACE Live |
Д |
Д |
Д |
Д |
Д |
Д |
Н |
Д |
Н |
Д |
Д |
Легко |
Д |
Д |
Д |
Н |
Д |
Коммерч. |
Д |
Д |
Д |
C, Java |
Д |
|
Opsview |
Д |
Д |
Д |
Д |
Н |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Н |
SQL |
GPL |
Динамические и настраиваемые |
Градация |
Д |
Perl, C |
|
|
PacketTrap |
Д |
Н |
Д |
Д |
Неизвестно |
Д |
Д |
Д |
Д |
Д |
Д |
Средне |
Д |
Просмотр и отчетность |
Д |
Неизвестно |
SQL |
Коммерч. |
Неизвестно |
Неизвестно |
Неизвестно |
||
|
Pandora FMS |
Д |
Д |
Д |
Д |
Д |
Д |
Поддерж. |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
MySQL |
GPLv2; (доступна коммперч. подписка) |
Автоматическое построение |
Градация |
Д |
Perl, PHP |
|
|
Performance Co-Pilot |
Д |
Н |
Д |
Д |
Н |
Н |
Д |
Н |
Н |
Д |
Д |
Средне |
Д |
Н |
Д |
Н |
Файл |
GPL, LGPL |
Н |
Н |
Н |
C, Perl, Python |
|
|
Scrutinizer |
Д |
Д |
Д |
Д |
Н |
Н |
Н |
Д |
Д |
Д |
Д |
Легко |
Д |
Д |
Д |
Д |
MySQL |
Коммерч. |
Динамические, статические, полностью настраиваемые |
Д |
Д |
Perl |
Д |
|
ServersCheck |
Д |
Д |
Д |
Д |
Н |
Д |
Поддерж |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Н |
Flat file, ODBC |
Коммерч. |
Динамические, статические, полностью настраиваемые |
Д |
Д |
||
|
SevOne |
Д |
Д |
Д |
Д |
Неизвестно |
Д |
Н |
Д |
Н |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Неизвестно |
MySQL |
Коммерч. |
Неизвестно |
Д |
Д |
||
|
Orion |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
SQL |
Коммерч. |
Д |
Д |
Д |
C |
Н |
|
Shinken |
Д |
Через плагин |
Д |
Д |
Н |
Через плагин |
Д |
Через плагин |
Через плагин |
Д |
Д |
Легко |
Д |
Просмотр, отчетность, контроль |
Д |
Через плагин |
Файл, MySQL, Oracle, CouchDB, Sqlite |
AGPL |
Динамические, статические, настраиваемые |
Н |
Д |
Python |
Н |
|
Spiceworks |
Д |
Д |
Д |
Н |
Н |
Д |
Поддерж |
Д |
Н |
Д |
Д |
Средне |
Д |
Д |
Д |
Д |
Sqlite |
Free Коммерч. |
Динамические, статические, настраиваемые |
Админ и польз. отчетность, больше через плагин |
Д |
Ruby |
Д |
|
TclMon |
Contributed standalone client |
Д |
Д |
Д |
Н |
Д |
Поддерж |
Д |
Д |
Д |
Д |
Легко - Сложно (зависит от метода) |
Д |
Внешний скрипт |
Н |
Н |
RRDTool, в памяти, плагины |
BSD |
Внешний отдельно стоящий клиент |
Д |
Н |
Tcl |
|
|
Zabbix |
Д |
Д |
Д |
Д |
Д |
Д |
Поддерж |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
Oracle, MySQL, PostgreSQL, SQLite |
GPL |
Д |
Д |
Д |
C, PHP |
|
|
ZeНss |
Д |
Д |
Д |
Д |
Д |
Д |
Н |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
ZODB, MySQL, RRDtool |
GPL ZeНss Core; платная Pro и Enterprise подписки |
Д |
Д |
Д |
Python, Zope |
|
|
Zyrion Traverse |
Д |
Real-time or Scheduled |
Д |
Д |
Д |
Д |
Поддерж |
Д |
Д |
Д |
Д |
Легко |
Д |
Полный контроль |
Д |
Д |
SQL |
Коммерч. |
Настраиваемые |
Многозвенный |
Д |
Java, C |
Приложение В
Конфигурация почтового модуля postfix
/etc/postfix/main.cf
# See /usr/share/postfix/main.cf.dist for a commented, more complete version
# Debian specific: Specifying a file name will cause the first
# line of that file to be used as the name. The Debian default
# is /etc/mailname.
#myorigin = /etc/mailname
smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)
biff = no
# appending .domain is the MUA's job.
append_dot_mydomain = no
# Uncomment the next line to generate "delayed mail" warnings
#delay_warning_time = 4h
readme_directory = no
# TLS parameters
smtpd_tls_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem
smtpd_tls_key_file=/etc/ssl/private/ssl-cert-snakeoil.key
smtpd_use_tls=yes
smtpd_tls_session_cache_database = btree:${data_directory}/smtpd_scache
smtp_tls_session_cache_database = btree:${data_directory}/smtp_scache
# See /usr/share/doc/postfix/TLS_README.gz in the postfix-doc package for
# information on enabling SSL in the smtp client.
myhostname = monitoring.vpcit.ru
alias_maps = hash:/etc/aliases
alias_database = hash:/etc/aliases
myorigin = /etc/mailname
mydestination = monitoring.vpcit.ru, localhost.vpcit.ru, , localhost
relayhost =
mynetworks = 127.0.0.0/8 [::ffff:127.0.0.0]/104 [::1]/128
mailbox_size_limit = 0
recipient_delimiter = +
inet_interfaces = all
inet_protocols = ipv4
Приложение Г
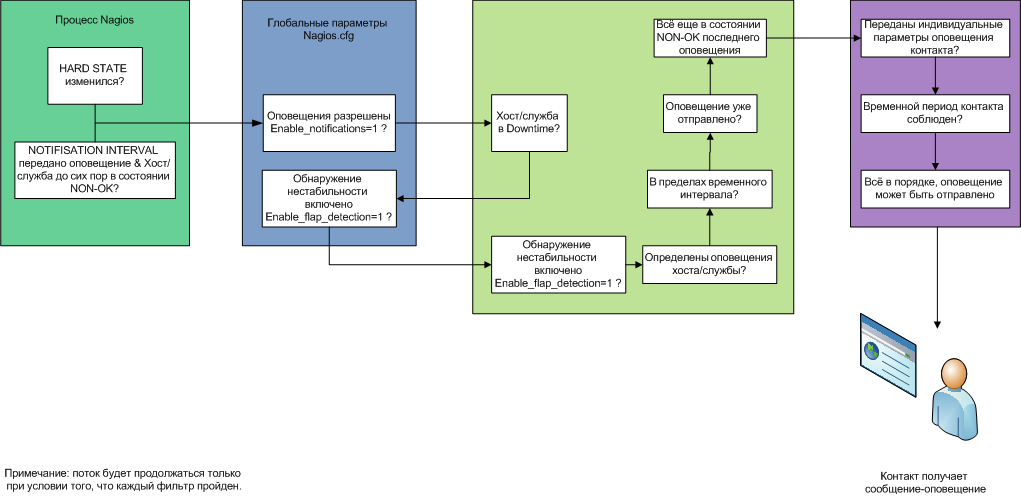
Рис. Д.1 - Диаграмма работы ядра сетевого мониторинга
Приложение Д
Структура конфигурационных файлов ядра системы
/etc/nagios3
├── apache2.conf
├── cgi.cfg
├── commands.cfg
├── commands.cfg.dpkg-dist
├── conf.d
│ ├── contacts_nagios2.cfg
│ ├── extinfo_nagios2.cfg
│ ├── generic-host_nagios2.cfg
│ ├── generic-service_nagios2.cfg
│ ├── host-gateway_nagios3.cfg
│ ├── host-gateway_nagios3.cfg.ucf-dist
│ ├── hostgroups_nagios2.cfg
│ ├── localhost_nagios2.cfg
│ ├── services_nagios2.cfg
│ └── timeperiods_nagios2.cfg
├── htpasswd.users
├── nagios.cfg
├── nagios.cfg.dpkg-dist
├── objects
│ ├── contacts.cfg
│ ├── extinfo.cfg
│ ├── hostgroups.cfg
│ ├── routers
│ │ ├── at9924.cfg
│ │ ├── des3627g.cfg
│ │ ├── rapier24i.cfg
│ │ └── router_len58a.cfg
│ ├── servers
│ │ ├── 1c.cfg
│ │ ├── db.cfg
│ │ ├── for.cfg
│ │ ├── host_mail.cfg
│ │ ├── isp.cfg
│ │ └── localhost.cfg
│ ├── servicegroups.cfg
│ ├── switches
│ ├── templates.cfg
│ └── timeperiods.cfg
├── pnp
├── resource.cfg
└── stylesheets
├── avail.css
├── checksanity.css
├── cmd.css
├── common.css
├── config.css
├── extinfo.css
├── histogram.css
├── history.css
├── ministatus.css
├── notifications.css
├── outages.css
├── showlog.css
├── status.css
├── statusmap.css
├── summary.css
├── tac.css
Приложение Е
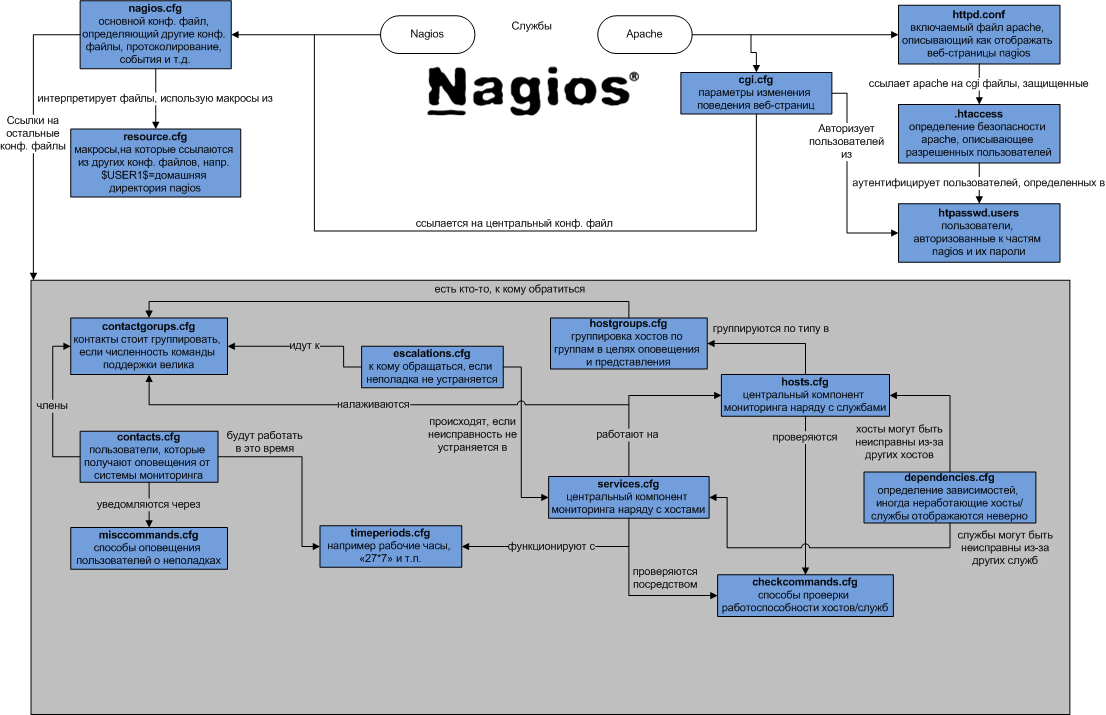
Рис. Ж.1 - Схема взаимодействия конфигурационных файлов Nagios
Приложение Ж
Файлы описания хостов и служб.
/etc/nagios3/objects/contacts.cfg
define contact{
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Voynovich Andrey ; Full name of user
email admin@vpcit.ru
host_notifications_enabled 1
service_notifications_enabled 1
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
can_submit_commands 1
}
define contact{
contact_name mainadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Demidoff Alexander ; Full name of user
email demidoff@vpcit.ru host_notifications_enabled 1
service_notifications_enabled 1
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
can_submit_commands 0
}
define contact{
contact_name maincoder ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Don Yura ; Full name of user
email yura@vpcit.ru
host_notifications_enabled 1
service_notifications_enabled 1
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
can_submit_commands 0
}
/etc/nagios3/objects/extinfo.cfg
define hostextinfo{
/etc/nagios3/objects/templates.cfg
# CONTACT TEMPLATES
# Generic contact definition template - This is NOT a real contact, just a template!
define contact{
name generic-contact ; The name of this contact template
service_notification_period 24x7 ; service notifications can be sent anytime
host_notification_period 24x7 ; host notifications can be sent anytime
service_notification_options w,u,c,r,f,s ; send notifications for all service states, flapping events, and scheduled downtime events
host_notification_options d,u,r,f,s ; send notifications for all host states, flapping events, and scheduled downtime events
service_notification_commands notify-service-by-email ; send service notifications via email
host_notification_commands notify-host-by-email ; send host notifications via email
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL CONTACT, JUST A TEMPLATE!
}
# We define a generic printer template that can be used for most printers we monitor
define host{
name generic-printer ; The name of this host template
use generic-host ; Inherit default values from the generic-host template
check_period 24x7 ; By default, printers are monitored round the clock
check_interval 5 ; Actively check the printer every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each printer 10 times (max)
check_command check-host-alive ; Default command to check if printers are "alive"
notification_period workhours ; Printers are only used during the workday
notification_interval 30 ; Resend notifications every 30 minutes
notification_options d,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DONT REGISTER THIS - ITS JUST A TEMPLATE
}
# Define a template for switches that we can reuse
define host{
name generic-switch ; The name of this host template
use generic-host ; Inherit default values from the generic-host template
check_period 24x7 ; By default, switches are monitored round the clock
check_interval 5 ; Switches are checked every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each switch 10 times (max)
check_command check-host-alive ; Default command to check if routers are "alive"
notification_period 24x7 ; Send notifications at any time
notification_interval 30 ; Resend notifications every 30 minutes
notification_options d,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DONT REGISTER THIS - ITS JUST A TEMPLATE
}
define service{
use generic-service
host_name 1c
service_description D:\ Data Space
check_command check_nt!USEDDISKSPACE!-l d -w 80 -c 90
notification_period 24x7
notification_options w,c,r
notification_interval 30
contact_groups admins
notifications_enabled 1
}
define service{
use generic-service
host_name 1c
service_description E:\ Swap Usage
check_command check_nt!USEDDISKSPACE!-l e -w 80 -c 90
notification_period 24x7
notification_options w,c,r
notification_interval 30
contact_groups admins
notifications_enabled 1
}
# Monitor uptime via SNMP
define service{
use generic-service
host_name host_mail
service_description Uptime
check_command check_netapp_uptime
}
define service{
use generic-service
host_name host_mail
service_description CPU Load
check_command check_nrpe_1arg!check_load
notification_period 24x7
notification_options w,c,r
notification_interval 30
contact_groups admins
notifications_enabled 1
}
#############################################################################
# This is configuration file for the NRPE daemon. It needs to be
# located on the remote host that is running the NRPE daemon, not the host
# from which the check_nrpe client is being executed.
#############################################################################
# PID FILE
# The name of the file in which the NRPE daemon should write it's process ID
# number. The file is only written if the NRPE daemon is started by the root
# user and is running in standalone mode.
pid_file=/var/run/nrpe.pid
# PORT NUMBER
# Port number we should wait for connections on.
# NOTE: This must be a non-priviledged port (i.e. > 1024).
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
server_port=5666
# SERVER ADDRESS
# Address that nrpe should bind to in case there are more than one interface
# and you do not want nrpe to bind on all interfaces.
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
server_address=192.168.10.214
# NRPE USER
# This determines the effective user that the NRPE daemon should run as.
# You can either supply a username or a UID.
#
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
nrpe_user=nagios
# NRPE GROUP
# This determines the effective group that the NRPE daemon should run as.
# You can either supply a group name or a GID.
#
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
nrpe_group=nagios
# ALLOWED HOST ADDRESSES
# This is an optional comma-delimited list of IP address or hostnames
# that are allowed to talk to the NRPE daemon.
#
# Note: The daemon only does rudimentary checking of the client's IP
# address. I would highly recommend adding entries in your /etc/hosts.allow
# file to allow only the specified host to connect to the port
# you are running this daemon on.
#
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
allowed_hosts=127.0.0.1,192.168.10.2
# COMMAND ARGUMENT PROCESSING
# This option determines whether or not the NRPE daemon will allow clients
# to specify arguments to commands that are executed. This option only works
# if the daemon was configured with the --enable-command-args configure script
# option.
#
# *** ENABLING THIS OPTION IS A SECURITY RISK! ***
# Read the SECURITY file for information on some of the security implications
# of enabling this variable.
#
# Values: 0=do not allow arguments, 1=allow command arguments
dont_blame_nrpe=0
# COMMAND PREFIX
# This option allows you to prefix all commands with a user-defined string.
# A space is automatically added between the specified prefix string and the
# command line from the command definition.
#
# *** THIS EXAMPLE MAY POSE A POTENTIAL SECURITY RISK, SO USE WITH CAUTION! ***
# Usage scenario:
# Execute restricted commmands using sudo. For this to work, you need to add
# the nagios user to your /etc/sudoers. An example entry for alllowing
# execution of the plugins from might be:
#
# nagios ALL=(ALL) NOPASSWD: /usr/lib/nagios/plugins/
#
# This lets the nagios user run all commands in that directory (and only them)
# without asking for a password. If you do this, make sure you don't give
# random users write access to that directory or its contents!
# command_prefix=/usr/bin/sudo
# DEBUGGING OPTION
# This option determines whether or not debugging messages are logged to the
# syslog facility.
# Values: 0=debugging off, 1=debugging on
#
# local configuration:
# if you'd prefer, you can instead place directives here
include=/etc/nagios/nrpe_local.cfg
Приложение З
Исходные тексты плагинов, не идущих в поставке с пакетом ядра системы.
/usr/lib/nagios/plugins/check_snmp_load.pl
#!/usr/bin/perl -w
# nagios: -epn
############################## check_snmp_load #################
my $Version='1.12';
#
# Help : ./check_snmp_load.pl -h
#
use strict;
use Net::SNMP;
use Getopt::Long;
# Nagios specific
my $TIMEOUT = 15;
my %ERRORS=('OK'=>0,'WARNING'=>1,'CRITICAL'=>2,'UNKNOWN'=>3,'DEPENDENT'=>4);
# SNMP Datas
# Generic with host-ressource-mib
my $base_proc = "1.3.6.1.2.1.25.3.3.1"; # oid for all proc info
my $proc_id = "1.3.6.1.2.1.25.3.3.1.1"; # list of processors (product ID)
my $proc_load = "1.3.6.1.2.1.25.3.3.1.2"; # %time the proc was not idle over last minute
# Linux load
my $linload_table= "1.3.6.1.4.1.2021.10.1"; # net-snmp load table
my $linload_name = "1.3.6.1.4.1.2021.10.1.2"; # text 'Load-1','Load-5', 'Load-15'
my $linload_load = "1.3.6.1.4.1.2021.10.1.3"; # effective load table
# Cisco cpu/load
my $cisco_cpu_5m = "1.3.6.1.4.1.9.2.1.58.0"; # Cisco CPU load (5min %)
my $cisco_cpu_1m = "1.3.6.1.4.1.9.2.1.57.0"; # Cisco CPU load (1min %)
my $cisco_cpu_5s = "1.3.6.1.4.1.9.2.1.56.0"; # Cisco CPU load (5sec %)
# Cisco catalyst cpu/load
my $ciscocata_cpu_5m = ".1.3.6.1.4.1.9.9.109.1.1.1.1.5.9"; # Cisco CPU load (5min %)
my $ciscocata_cpu_1m = ".1.3.6.1.4.1.9.9.109.1.1.1.1.3.9"; # Cisco CPU load (1min %)
my $ciscocata_cpu_5s = ".1.3.6.1.4.1.9.9.109.1.1.1.1.4.9"; # Cisco CPU load (5sec %)
# Netscreen cpu/load
my $nsc_cpu_5m = "1.3.6.1.4.1.3224.16.1.4.0"; # NS CPU load (5min %)
my $nsc_cpu_1m = "1.3.6.1.4.1.3224.16.1.2.0"; # NS CPU load (1min %)
my $nsc_cpu_5s = "1.3.6.1.4.1.3224.16.1.3.0"; # NS CPU load (5sec %)
# AS/400 CPU
my $as400_cpu = "1.3.6.1.4.1.2.6.4.5.1.0"; # AS400 CPU load (10000=100%);
# Net-SNMP CPU
my $ns_cpu_idle = "1.3.6.1.4.1.2021.11.11.0"; # Net-snmp cpu idle
my $ns_cpu_user = "1.3.6.1.4.1.2021.11.9.0"; # Net-snmp user cpu usage
my $ns_cpu_system = "1.3.6.1.4.1.2021.11.10.0"; # Net-snmp system cpu usage
# Procurve CPU
my $procurve_cpu = "1.3.6.1.4.1.11.2.14.11.5.1.9.6.1.0"; # Procurve CPU Counter
# Nokia CPU
-t, --timeout=INTEGER
timeout for SNMP in seconds (Default: 5)
-V, --version
prints version number
EOT
}
# For verbose output
sub verb { my $t=shift; print $t,"\n" if defined($o_verb) ; }
sub check_options {
Getopt::Long::Configure ("bundling");
GetOptions(
'v' => \$o_verb, 'verbose' => \$o_verb,
'h' => \$o_help, 'help' => \$o_help,
'H:s' => \$o_host, 'hostname:s' => \$o_host,
'p:i' => \$o_port, 'port:i' => \$o_port,
'C:s' => \$o_community, 'community:s' => \$o_community,
'l:s' => \$o_login, 'login:s' => \$o_login,
'x:s' => \$o_passwd, 'passwd:s' => \$o_passwd,
'X:s' => \$o_privpass, 'privpass:s' => \$o_privpass,
'L:s' => \$v3protocols, 'protocols:s' => \$v3protocols,
't:i' => \$o_timeout, 'timeout:i' => \$o_timeout,
'V' => \$o_version, 'version' => \$o_version,
'2' => \$o_version2, 'v2c' => \$o_version2,
'c:s' => \$o_crit, 'critical:s' => \$o_crit,
'w:s' => \$o_warn, 'warn:s' => \$o_warn,
'f' => \$o_perf, 'perfparse' => \$o_perf,
'T:s' => \$o_check_type, 'type:s' => \$o_check_type
);
# check the -T option
my $T_option_valid=0;
foreach (@valid_types) { if ($_ eq $o_check_type) {$T_option_valid=1} };
if ( $T_option_valid == 0 )
{print "Invalid check type (-T)!\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
# Basic checks
if (defined($o_timeout) && (isnnum($o_timeout) || ($o_timeout < 2) || ($o_timeout > 60)))
{ print "Timeout must be >1 and <60 !\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
if (!defined($o_timeout)) {$o_timeout=5;}
if (defined ($o_help) ) { help(); exit $ERRORS{"UNKNOWN"}};
if (defined($o_version)) { p_version(); exit $ERRORS{"UNKNOWN"}};
if ( ! defined($o_host) ) # check host and filter
{ print_usage(); exit $ERRORS{"UNKNOWN"}}
# check snmp information
if ( !defined($o_community) && (!defined($o_login) || !defined($o_passwd)) )
{ print "Put snmp login info!\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
if ((defined($o_login) || defined($o_passwd)) && (defined($o_community) || defined($o_version2)) )
{ print "Can't mix snmp v1,2c,3 protocols!\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
if (defined ($v3protocols)) {
if (!defined($o_login)) { print "Put snmp V3 login info with protocols!\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
my @v3proto=split(/,/,$v3protocols);
if ((defined ($v3proto[0])) && ($v3proto[0] ne "")) {$o_authproto=$v3proto[0]; } # Auth protocol
if (defined ($v3proto[1])) {$o_privproto=$v3proto[1]; } # Priv protocol
if ((defined ($v3proto[1])) && (!defined($o_privpass))) {
print "Put snmp V3 priv login info with priv protocols!\n"; print_usage(); exit $ERRORS{"UNKNOWN"}}
########### Linux load check ##############
if ($o_check_type eq "netsl") {
verb("Checking linux load");
# Get load table
my $resultat = (Net::SNMP->VERSION < 4) ?
$session->get_table($linload_table)
: $session->get_table(Baseoid => $linload_table);
if (!defined($resultat)) {
printf("ERROR: Description table : %s.\n", $session->error);
$session->close;
exit $ERRORS{"UNKNOWN"};
}
$session->close;
my @load = undef;
my @iload = undef;
my @oid=undef;
my $exist=0;
foreach my $key ( keys %$resultat) {
verb("OID : $key, Desc : $$resultat{$key}");
if ( $key =~ /$linload_name/ ) {
@oid=split (/\./,$key);
$iload[0]= pop(@oid) if ($$resultat{$key} eq "Load-1");
$iload[1]= pop(@oid) if ($$resultat{$key} eq "Load-5");
$iload[2]= pop(@oid) if ($$resultat{$key} eq "Load-15");
$exist=1
}
}
if ($exist == 0) {
print "Can't find snmp information on load : UNKNOWN\n";
exit $ERRORS{"UNKNOWN"};
}
for (my $i=0;$i<3;$i++) { $load[$i] = $$resultat{$linload_load . "." . $iload[$i]}};
print "Load : $load[0] $load[1] $load[2] :";
$exit_val=$ERRORS{"OK"};
for (my $i=0;$i<3;$i++) {
if ( $load[$i] > $o_critL[$i] ) {
print " $load[$i] > $o_critL[$i] : CRITICAL";
$exit_val=$ERRORS{"CRITICAL"};
}
if ( $load[$i] > $o_warnL[$i] ) {
# output warn error only if no critical was found
if ($exit_val eq $ERRORS{"OK"}) {
print " $load[$i] > $o_warnL[$i] : WARNING";
##### Checking hpux load
if ($o_check_type eq "hpux") {
verb("Checking hpux load");
my @oidlists = ($hpux_load_1_min, $hpux_load_5_min, $hpux_load_15_min);
my $resultat = (Net::SNMP->VERSION < 4) ?
$session->get_request(@oidlists)
: $session->get_request(-varbindlist => \@oidlists);
if (!defined($resultat)) {
printf("ERROR: Load table : %s.\n", $session->error);
$session->close;
exit $ERRORS{"UNKNOWN"};
}
$session->close;
if (!defined ($$resultat{$hpux_load_1_min})) {
print "No Load information : UNKNOWN\n";
exit $ERRORS{"UNKNOWN"};
}
my @load = undef;
$load[0]=$$resultat{$hpux_load_1_min}/100;
$load[1]=$$resultat{$hpux_load_5_min}/100;
$load[2]=$$resultat{$hpux_load_15_min}/100;
print "Load : $load[0] $load[1] $load[2] :";
$exit_val=$ERRORS{"OK"};
for (my $i=0;$i<3;$i++) {
if ( $load[$i] > $o_critL[$i] ) {
print " $load[$i] > $o_critL[$i] : CRITICAL";
$exit_val=$ERRORS{"CRITICAL"};
}
if ( $load[$i] > $o_warnL[$i] ) {
# output warn error only if no critical was found
if ($exit_val eq $ERRORS{"OK"}) {
print " $load[$i] > $o_warnL[$i] : WARNING";
$exit_val=$ERRORS{"WARNING"};
}
}
}
print " OK" if ($exit_val eq $ERRORS{"OK"});
if (defined($o_perf)) {
print " | load_1_min=$load[0]%;$o_warnL[0];$o_critL[0] ";
print "load_5_min=$load[1]%;$o_warnL[1];$o_critL[1] ";
print "load_15_min=$load[2]%;$o_warnL[2];$o_critL[2]\n";
} else {
print "\n";
}
return 1;
}
sub round ($$) {
sprintf "%.$_[1]f", $_[0];
}
########### Net snmp memory check ############
if (defined ($o_netsnmp)) {
# Get NetSNMP memory values
$resultat = (Net::SNMP->VERSION < 4) ?
$session->get_request(@nets_oids)
:$session->get_request(-varbindlist => \@nets_oids);
if (!defined($resultat)) {
printf("ERROR: netsnmp : %s.\n", $session->error);
$session->close;
exit $ERRORS{"UNKNOWN"};
}
my ($realused,$swapused)=(undef,undef);
$realused= defined($o_cache) ?
($$resultat{$nets_ram_total}-$$resultat{$nets_ram_free})/$$resultat{$nets_ram_total}
:
($$resultat{$nets_ram_total}-($$resultat{$nets_ram_free}+$$resultat{$nets_ram_cache}))/$$resultat{$nets_ram_total};
if($$resultat{$nets_ram_total} == 0) { $realused = 0; }
$swapused= ($$resultat{$nets_swap_total} == 0) ? 0 :
($$resultat{$nets_swap_total}-$$resultat{$nets_swap_free})/$$resultat{$nets_swap_total};
$realused=round($realused*100,0);
$swapused=round($swapused*100,0);
defined($o_cache) ?
verb ("Ram : $$resultat{$nets_ram_free} / $$resultat{$nets_ram_total} : $realused")
:
verb ("Ram : $$resultat{$nets_ram_free} ($$resultat{$nets_ram_cache} cached) / $$resultat{$nets_ram_total} : $realused");
verb ("Swap : $$resultat{$nets_swap_free} / $$resultat{$nets_swap_total} : $swapused");
my $n_status="OK";
my $n_output="Ram : " . $realused . "%, Swap : " . $swapused . "% :";
if ((($o_critR!=0)&&($o_critR <= $realused)) || (($o_critS!=0)&&($o_critS <= $swapused))) {
$n_output .= " > " . $o_critR . ", " . $o_critS;
$n_status="CRITICAL";
} else {
if ((($o_warnR!=0)&&($o_warnR <= $realused)) || (($o_warnS!=0)&&($o_warnS <= $swapused))) {
$n_output.=" > " . $o_warnR . ", " . $o_warnS;
$n_status="WARNING";
}
}
$n_output .= " ; ".$n_status;
if (defined ($o_perf)) {
if (defined ($o_cache)) {
$n_output .= " | ram_used=" . ($$resultat{$nets_ram_total}-$$resultat{$nets_ram_free}).";";
}
else {
$n_output .= " | ram_used=" . ($$resultat{$nets_ram_total}-$$resultat{$nets_ram_free}-$$resultat{$nets_ram_cache}).";";
}
$n_output .= ($o_warnR ==0)? ";" : round($o_warnR * $$resultat{$nets_ram_total}/100,0).";";
$n_output .= ($o_critR ==0)? ";" : round($o_critR * $$resultat{$nets_ram_total}/100,0).";";
$n_output .= "0;" . $$resultat{$nets_ram_total}. " ";
$n_output .= "swap_used=" . ($$resultat{$nets_swap_total}-$$resultat{$nets_swap_free}).";";
$n_output .= ($o_warnS ==0)? ";" : round($o_warnS * $$resultat{$nets_swap_total}/100,0).";";
$n_output .= ($o_critS ==0)? ";" : round($o_critS * $$resultat{$nets_swap_total}/100,0).";";
$n_
Приложение И
Конфигурация протокола SNMP на удаленных хостах
# sec.name source community
#com2sec paranoid default public
com2sec readonly default public
#com2sec readwrite default private
####
# Second, map the security names into group names:
# sec.model sec.name
group MyROSystem v1 paranoid
group MyROSystem v2c paranoid
group MyROSystem usm paranoid
group MyROGroup v1 readonly
group MyROGroup v2c readonly
group MyROGroup usm readonly
group MyRWGroup v1 readwrite
group MyRWGroup v2c readwrite
group MyRWGroup usm readwrite
####
# Third, create a view for us to let the groups have rights to:
# incl/excl subtree mask
view all included .1 80
view system included .iso.org.dod.internet.mgmt.mib-2.system
####
# Finally, grant the 2 groups access to the 1 view with different
# write permissions:
# context sec.model sec.level match read write notif
access MyROSystem "" any noauth exact system none none
access MyROGroup "" any noauth exact all none none
access MyRWGroup "" any noauth exact all all none
Приложение К
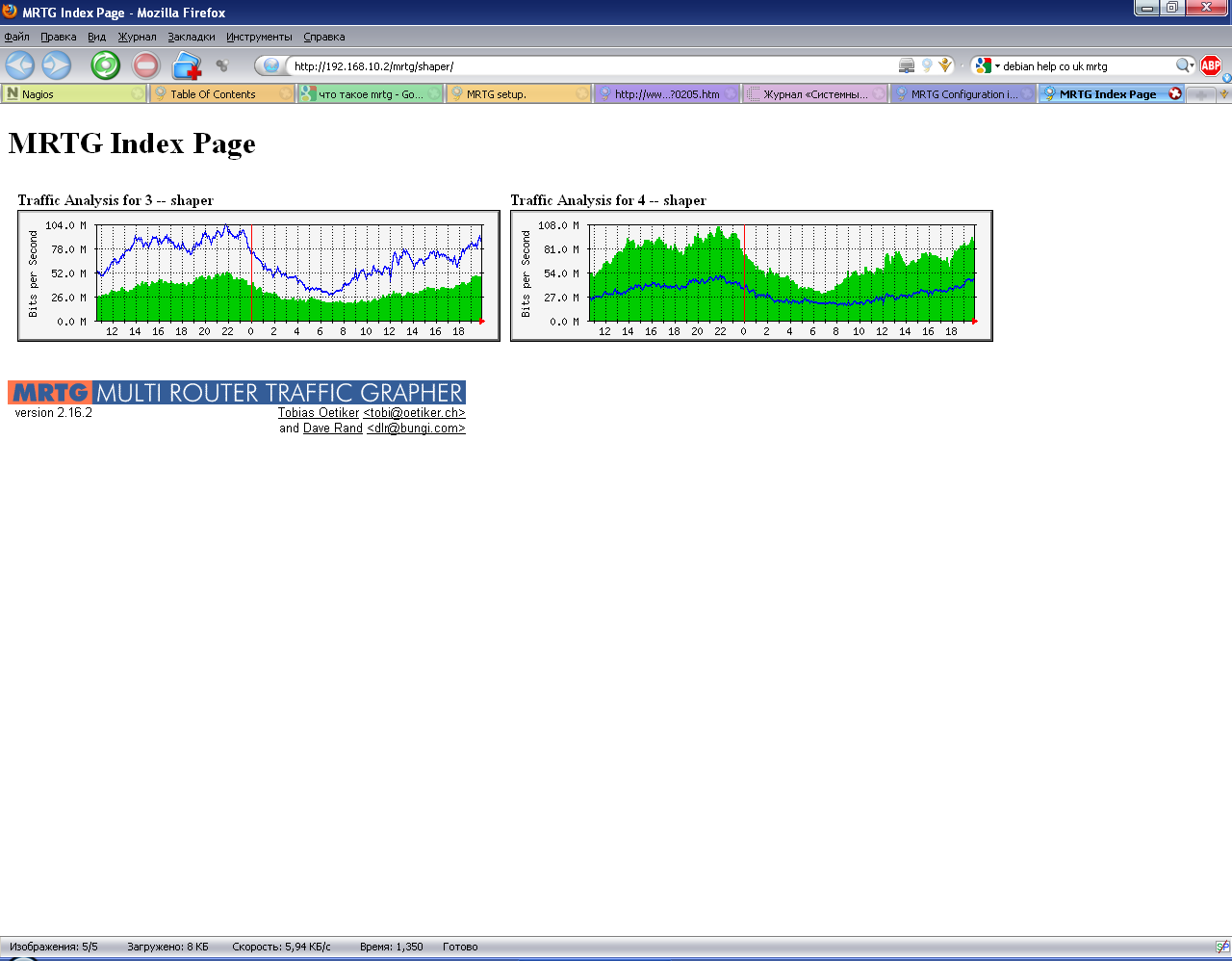
Рис. Н.1 - Пример представления графиков загрузки интерфейсов посредством MRTG
Приложение Л
Скрипт инициализации пакетного фильтра
/root/boot/firewall
#!/bin/bash
#
# local variables
I="/sbin/iptables"
# just head
## clear all rules
$I -F INPUT
$I -F OUTPUT
$I -F FORWARD
$I -F POSTROUTING -t mangle
$I -F INPUT -t filter
## set default policy to drop all packets
$I -P INPUT DROP
$I -P OUTPUT DROP
$I -P FORWARD DROP
## allow tcp, udp packets for already established tcp, udp connections
## plus tcp, udp packets creating new tcp, udp connections
$I -A INPUT -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT
$I -A INPUT -p udp -m state --state ESTABLISHED,RELATED -j ACCEPT
$I -A OUTPUT -p tcp -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT
$I -A OUTPUT -p udp -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT
## allow loopback, for applications using UNIX sockets
$I -A INPUT -i lo -j ACCEPT
$I -A OUTPUT -o lo -j ACCEPT
# Services
## allow to connect via ssh and others wants to connect my PC via ssh
$I -A INPUT -p tcp --dport 22 -j ACCEPT -s <source>
<…>
## I want to show web face of nagios and mrtg
$I -A INPUT -p tcp --dport http -j ACCEPT -s <source>
<…>
## Here goes OCS Inventory needs access
$I -A INPUT -p tcp --dport http -j ACCEPT -i eth0.92
## allow icmp
$I -A INPUT -p icmp -j ACCEPT
$I -A OUTPUT -p icmp -j ACCEPT
## system logging

- Разработка регламента выполнения процесса «Складской учет» (Организационная структура Склада)
- Доходы и расходы коммерческих банков (на примере ПАО «МТС-Банк»)
- Цели создания запасов и их классификация (Понятие запасов, цели их создания, классификация запасов)
- Учёт наличных денежных средств в кассе предприятия ( УЧЕТ ДЕНЕЖНЫХ СРЕДСТВ В КАССЕ )
- Управление банковским долгосрочным кредитованием ( СУЩНОСТЬ И НЕОБХОДИМОСТЬ УПРАВЛЕНИЯ ПРОБЛЕМНЫМИ КРЕДИТАМИ В КОММЕРЧЕСКИХ КРЕДИТАХ )
- Построение организационных структур ( ПРОЕКТИРОВАНИЕ И АНАЛИЗ ОРГАНИЗАЦИОННОЙ СТРУКТУРЫ УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ ОАО «ПОЛИЭФ» )
- Протезно-ортопедическая помощь ( Правовое регулирование медико-социальных услуг по оказанию населению протезно-ортопедической помощи )
- Устройство персонального компьютера (Компьютер в жизни человека)
- Реформа электроэнергетики в России (Типы и виды электростанций)
- Основные нормативные документы, регулирующие ведение бухгалтерского учета в организациях. Международные стандарты бухгалтерского учета (на примере ООО ШАРМ+»)
- Ценовые войны в теории и на практике (Сущность ценовых войн и причины их возникновения)
- Оборотные активы предприятия ( Теоретические аспекты управления оборотными активами )