
Мультипроцессоры
Содержание:

ВВЕДЕНИЕ
Актуальность работы. В настоящее время цифровые видеокамеры становятся неотъемлемым элементом повседневной жизни человека, и основными направлениями совершенствования видеокамер являются: повышение их разрешения и расширение встраиваемых функций по обработке видео. Отсюда появляются требования по повышению производительности цифрового процессора видеокамер. Достигнуть высокой производительности можно за счет применения методов параллельного выполнения команд (конвейер команд, векторизация, суперскалярность) и параллельного выполнения потоков команд (многопотоковость).
Для облегчения работы цифрового процессора и для дальнейшей об- работки цифрового потока в систему видеокамеры можно внедрить много- процессорную систему, так как она лучше справляется с задачами обработки и архивации цифровых потоков.
Данная система должна обладать малыми габаритами, высокой скоростью обработки потоков и высокой степенью интегрируемости с конечным устройством.
Мультипроцессорные системы реализуются в системах обрабатывающих цифровой поток уже в течение нескольких десятилетий, однако сейчас интерес к ним снова возрастает в связи с появлением возможности использовать встраиваемые в кристалл процессоры.
Целью работы является изучение многопроцессорной системы
Объектом исследования является процесс создания и отладки устройств, выполненных на программируемой логической интегральной схеме.
Предметом исследования являются методы и алгоритмы создания многопроцессорных систем.
Для достижения поставленной цели были решены следующие задачи:
1. Исследование особенности работы встроенных процессоров;
2. Исследование взаимодействия системы с периферийными устройствами входящих в систему;
3. Исследование особенностей многопроцессорных систем и их работы с общими периферийными устройствами;
Для достижения поставленной цели были использованы общелогические методы – анализ, синтез, классификация, типологизация, системный подход и метод теоретического познания – формализация.
ГЛАВА 1. ВЫБОР АППАРАТНО-ПРОГРАММНЫХ И ПРОГРАММНЫХ СРЕДСТВ ДЛЯ РАЗРАБОТКИ МНОГОПРОЦЕССОРНОЙ СИСТЕМЫ
1.1 ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ
По мере развития цифровых микросхем возникло противоречие между возможной степенью интеграции и номенклатурой выпускаемых микросхем. Экономически оправдано было выпускать микросхемы средней интеграции, таких как регистры, счетчики, сумматоры. Более сложные схемы приходилось создавать из этих узлов. Разместить более сложную схему на полупроводниковом кристалле не было проблем, но это было оправдано либо очень большой серийностью аппаратуры, либо ценой аппаратуры (военная, авиационная или космическая). Заказные микросхемы не могли удовлетворить возникшую потребность в миниатюризации аппаратуры. Решение могло быть только одним — предоставить разработчикам аппаратуры возможность изменять внутреннюю структуру микросхемы (программировать). [1][1]
История развития программируемых логических интегральных схем (ПЛИС) начинается с появления программируемых постоянных запоминающих устройств. Первое время программируемые ПЗУ использовались исключительно для хранения данных, однако вскоре их стали применять для реализации цифровых комбинационных устройств с произвольной таблицей истинности. В качестве недостатка подобного решения следует отметить экспоненциальный рост сложности устройства в зависимости от количества входов. Добавление одного дополнительного входа цифрового устройства приводит к удвоению требуемого количества ячеек памяти ПЗУ. Это не позволяет реализовать многовходовые комбинационные цифровые схемы.
Для реализации цифровых комбинационных устройств с большим числом входов были разработаны программируемые логические матрицы (ПЛМ). В иностранной литературе они получили название — Programmable Logic Arrays (PLA). Именно программируемые логические матрицы можно считать первыми программируемыми логическими интегральными схемами (Programmable Logic Devices — PLDs). ПЛМ получили широкое распространение в качестве первых универсальных микросхем большой интеграции [1].
Преимущества ПЛИС в качестве платформы для создания процессорных систем можно описать следующими параметрами: настройка, устранение устаревания, снижение затрат за счет системной интеграции и аппаратного ускорения.
Настройка. Разработчик встроенной процессорной системы обладает полной гибкостью для настройки встроенного процессора на основе пара- метров конфигурации. В качестве настраиваемого функционального блока (IP core) несколько процессоров могут быть созданы на одном устройстве, в зависимости от потребностей конечного приложения. Наличие конфигурируемых периферийных устройств также помогает в создании пользовательских встроенных решений, поскольку инструменты разработки ПЛИС облегчают как проектирование, так и интеграцию определенных периферийных устройств.
Устранение устаревания. Некоторые отрасли промышленности, особенно те, которые поддерживают сегмент рынка аэрокосмической и оборонной промышленности, предъявляют строгие требования к разработке, чтобы продлить срок службы изделия дольше, чем срок службы стандартного электронного изделия. Необходимость смягчения устаревания компонентов может рассматриваться как сложная проблема. Настраиваемые процессоры, тем не менее, обеспечивают отличное решение, поскольку одно и то же ядро может поддерживаться и переноситься между различными семействами устройств в течение длительного срока службы.
Снижение затрат за счет системной интеграции. Преимуществом программируемого устройства является не только настраиваемая цифровая логика; Это, скорее, широкий спектр функций - в некоторых случаях, не цифровых, доступных в современных технологиях. Высокоценные цифровые компоненты системы могут содержать процессоры, цифровые сигнальные процессоры (DSP), стандартные компоненты для конкретных приложений (ASSP), программируемые пользователем вентильные матрицы (FPGA), системы на кристалле (SoC) или их комбинацию. Их нецифровые компоненты могут включать в себя, помимо прочего, аналого-цифровые преобразователи (АЦП), датчики и интерфейсы интегральных схем, предназначенных для подключения к физической среде передачи (PHY). Устройства ПЛИС могут интегрировать большую часть этой функции в один чип. Уменьшая количество компонентов в устройстве, компания может сократить размер платы и управление запасами, что экономит время и затраты на разработку. [1][2]
Аппаратное ускорение. Пожалуй, наиболее веская причина выбора встроенного процессора программируемого устройства - это гибкость, позволяющая делать компромисс между аппаратным и программным обеспечением, что повышает эффективность и производительность. Например, если алгоритм идентифицирован как узкое место программного обеспечения, в ПЛИС специально для этого алгоритма может быть сконструирован пользовательский механизм совместной обработки. Этот сопроцессор может быть подключен к встроенному процессору ПЛИС через специальные каналы с малой задержкой.
Для реализации многопроцессорной системы на кристалле была выбрана система автоматизированного проектирования (САПР) QuartusII, фирмы Altera, с входящими в ее состав QSYS и NIOSII.
Для решения данной задачи были рассмотрены программируемые логические интегральные схемы (ПЛИС) фирмы Altera и Xilinx.
1.2. СРЕДСТВО АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ QUARTUSII
Quartus II – это средство проектирования устройств с высокой степенью интеграции, включая разработку законченных систем на одном программируемом кристалле (System-on-a-programmable-chip (SOPC)).
Программное обеспечение Quartus II предоставляет полный цикл для создания высокопроизводительных систем на кристалле. Quartus II объединяет в себе проектирование, синтез, размещение элементов, трассировку соединений и верификацию, связь с системами проектирования других производителей.
Разработка систем на кристалле требует от разработчиков эффективной командной работы. Изменения в одной части проекта должно иметь минимальное влияние на других членов команды. Программное обеспечение Quartus II - это наиболее комплексная среда для разработки систем на кристалле SOPC, доступная в настоящее время [2].
1.3. СРЕДА СИСТЕМНОЙ ИНТЕГРАЦИИ QSYS
Qsys - это инструмент системной интеграции, входящий в состав программного обеспечения Quartus II. Qsys фиксирует аппаратные конструкции системного уровня на высоком уровне абстракции и автоматизирует задачу определения и интеграции настраиваемых компонентов HDL, которые могут включать в себя IP-ядра, IP-проверки и другие модули дизайна. Qsys облегчает повторное использование дизайна путем упаковки и предоставления пользовательских компонентов и систем, а также интегрирует пользовательские компоненты Altera с сторонними компонентами разработчика [3].
Qsys автоматически создает логику межсоединений из указанных на- ми параметров подключения, устраняя подверженную ошибкам и трудоемкую задачу записи HDL для определения соединений на системном уровне.
Qsys использует стандартные интерфейсы Avalon , AMBA AXI3 (вер- сия 1.0) и AMBA AXI4 (версия 2.0), которые можно использовать для создания своих пользовательских IP-компонентов. Связи между интерфейсами Avalon и AXI разрешены и могут быть достигнуты без использования мостов. Взаимодействие Qsys обеспечивает необходимую рабочую логику соединений. [2][3]
Qsys interconnect поддерживает полную 64-битную адресацию для всех интерфейсов и компонентов Qsys, с диапазоном 0x0000 0000 0000 0000 до 0xFFFF FFFF FFFF FFFF, включительно. Это включает в себя поддержку ведущих и ведомых устройств Avalon, ведущих и ведомых AXI3, и ведущих и ведомых AXI4, отображаемых в памяти, соединениях, переводчиков, адаптеров и маршрутизаторов.
В Qsys можно добавлять экземпляры компонентов, настраивать их и устанавливать связи между их интерфейсами. После создания системы Qsys генерирует HDL для системного модуля, который создает экземпляр системы, включая экземпляр системных межсоединений.
Также Qsys можно использовать для построения встроенных микропроцессорных систем, включающих процессоры, интерфейсы памяти и периферийные устройства. Можно создавать системы потоков данных, которые не включают процессор. Qsys позволяет создавать топологии шины с несколькими ведущими и ведомыми устройствами.
Двойной щелчок на экземпляре на панели подключения открывает редактор параметров, который позволяет настраивать аппаратные настройки. Например, для контроллеров памяти можно определить ширину данных, размеры пакетов, задержки трассировки и тайминги устройств.
Для некоторых компонентов можно создавать, изменять и сохранять пользовательские параметры компонента в виде файла предварительной настройки, который затем можно использовать в других системах Qsys. Если компонент или ядро IP поддерживает пресеты, то редактор настроек появится в правой части редактора параметров.
1.4. ВСТРАИВАЕМЫЙ ПРОЦЕССОР NIOS II
Процессор Nios II, представленный компанией Altera в 2004 году, предназначен для замены оригинального процессора Nios, характеризующегося 16 битным набором инструкций и 16 битным регистровым окном. В настоящее время процессор Nios II признан самым популярным конфигурируемым в кристалле FPGA процессором, лидером по гибкости использования [4].
Процессор Nios II может быть сконфигурирован под требуемую задачу. Существует 3 различные версии конфигурации процессора:
1) Nios II/f (fast) – версия процессора, предназначенная для достижения максимальной производительности. Конфигурация имеет широкий набор опций для оптимизации процессора по производительности;
2) Nios II/s (standart) – стандартная версия процессора, требующая меньше ресурсов для реализации, и характеризующаяся меньшей производительностью; [2][4]
3) Nios II/e (economy) – экономичная версия процессора, требующая наименьшее количество ресурсов кристалла для реализации, и обладающая ограниченным набором возможностей.
Процессор Nios II имеет RISC архитектуру, в которой арифметические и логические операции выполняются над операндами, находящимися в регистрах общего назначения. Обмен информацией между регистрами и па- мятью осуществляется путем выполнения команд “Load” и “Store” (загрузка и хранение соответственно).
Машинное слово процессора Nios II имеет ширину 32 бита, такой же размер имеют его регистры. Для адресации байтов в слове используется little-endian стиль, при котором менее значимые байты расположены по меньшим адресам в ОП. Процессор имеет гарвардскую архитектуру, то есть использует раздельные шины для данных и команд. Структурная схе- ма процессора Nios II воспроизведена на рисунке 1.
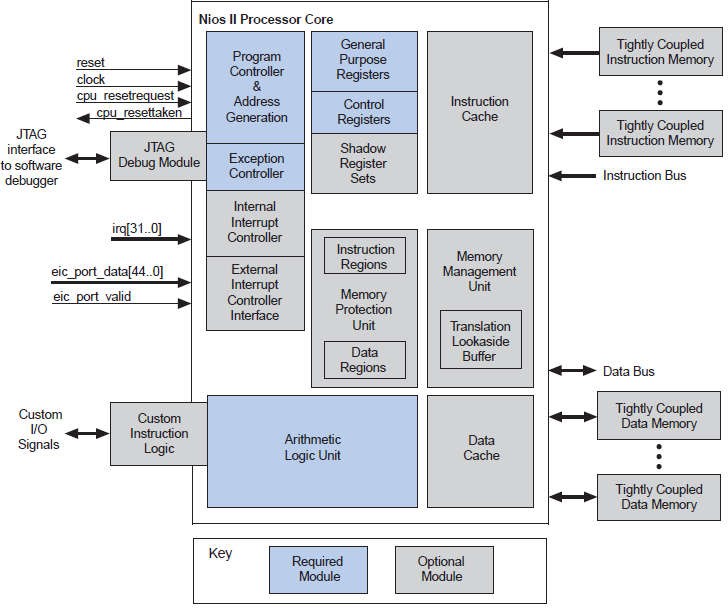
Рис. 1. Структурная схема процессора Nios II.
Процессор Nios II может функционировать в следующих режимах:
1) Режим супервизора. В данном режиме процессору разрешается выполнять все инструкции и осуществлять любые функции. Процессор переключается в этот режим после поступления сигнала сброса;
2) Режим пользователя. Целью данного режима является предотвращение выполнения определенных инструкций системного назначения. Переключение в этот режим становится возможным лишь при наличии модуля управления памятью (MMU) или модуля защиты памяти (MPU).
Ниже приведены основные характеристики процессора Nios II/f:
1) Более 2-х гигабайт адресного пространства;
2) Отдельный кэш инструкций и кэш данных;
3) Аппаратное выполнение умножения и деления;
4) 6-ти стадийный конвейер;
5) Поддержка исключений;
6) Система защиты памяти;
7) Система виртуальной памяти;
8) Выполнение операции умножения и сдвига за один такт;
9) Динамическое предсказание ветвлений;
10) Использование до 256 пользовательских инструкций;
11) Широкие возможности отладки через JTAG модуль;
12) Реализация требует 1400-1800 логических элементов FPGA;
13) Реализация включает 3 блока памяти M4K, плюс блоки для кэш памяти;
14) Производительность процессора 51 миллион операций в секунду (51 DMIPS) на частоте 50 МГц.
Процессор Nios II и интерфейсы для сопряжения с оперативной памятью и другими периферийными компонентами системы реализуются в кристалле ПЛИС. Для соединения компонентов процессорной системы ис- пользуется синхронная шина Avalon. Шина Avalon может содержать сле- дующие типы:
1) Avalon Clock Interface, для передачи синхросигналов и управления ими;
2) Avalon Reset Interface, для передачи сигналов сброса;
3) Avalon Streaming Interface (Avalon-ST), для поддержки однонаправленных потоков данных, включая мультиплексированные, пакетные и данные цифровых сигнальных процессоров;
4) Avalon Memory Mapped Interface (Avalon-MM), для чтения/записи с адресацией типа ведущий/ведомый;
5) Avalon Tri-State Conduit Interface (Avalon TC), для сопряжения с моду- лями вне кристалла;
6) Avalon Interrupt Interface, для реализации приоритетной системы прерываний;
7) Avalon Conduit Interface, для объединения отдельных сигналов или групп сигналов, которые не подходят под любой другой тип шины Avalon.
1.5 ВСТРАИВАЕМЫЙ ПРОЦЕССОР MICROBLAZE
Процессор MicroBlaze представляет собой полнофункциональное программируемое 32-разрядное ядро RISC, оптимизированное для ПЛИС. Он удовлетворяет разнообразным требованиям на промышленных, медицинских, автомобильных, потребительских и коммуникационных инфраструктурных рынках, среди прочих - для чувствительных к стоимости и больших объемов приложений. Он весьма конфигурируемый и может использоваться в качестве микроконтроллера или встроенного процессора в ПЛИС (Spartan-6 или Artix-7 ПЛИС) или в качестве сопроцессора для ARM Cortex-A9 на базе Zynq-7000 AP SoCs. Для оптимизации встраиваемых систем большую роль играет доступность простых в использовании средств разработки и отладки аппаратного и программного обеспечения, времени выполнения и IP ядер. Чтобы решить эту проблему, Xilinx также предоставляет Vivado® Design Suite, который включает в себя IP- интегратор Vivado (IPI) и ISE Embedded edition (для ПЛИС Spartan-6). Эти инструменты обеспечивают среду разработки на базе IP и систем, в которой используются встроенные IP-устройства с поддержкой Plug-and-Play (на базе AXI4) и полный комплект средств разработки программного обеспечения (SDK). Эти компоненты помогают пользователям быстрее создавать более совершенные системы, сокращая общее время разработки решения [5][5].
Несмотря на растущую сложность и изощренность встроенных систем, даже для недорогих приложений с низким уровнем затрат, исключи- тельное время выхода на рынок продолжает расти. Даже низкоуровневые программируемые решения вышли далеко за пределы логики склеивания для полнофункциональных высокоприоритетных компонентов, которые позволяют ключевой системный интеллект посредством встроенной обработки. Наличие правильного программируемого устройства и встроенного процессора больше не является полным решением; в равной степени важно иметь дееспособные программные средства, программное обеспечение времени выполнения, поддержку периферийных IP-адресов и документацию.
Встроенные процессорные системы ПЛИС Xilinx предоставляют разработчику множество исключительных преимуществ по сравнению с типичными микропроцессорами, включая настройку, снижение устаревания, снижение стоимости компонентов и аппаратное ускорение [6][6].
На рисунке 2 представлен структурный вид ядра MicroBlaze
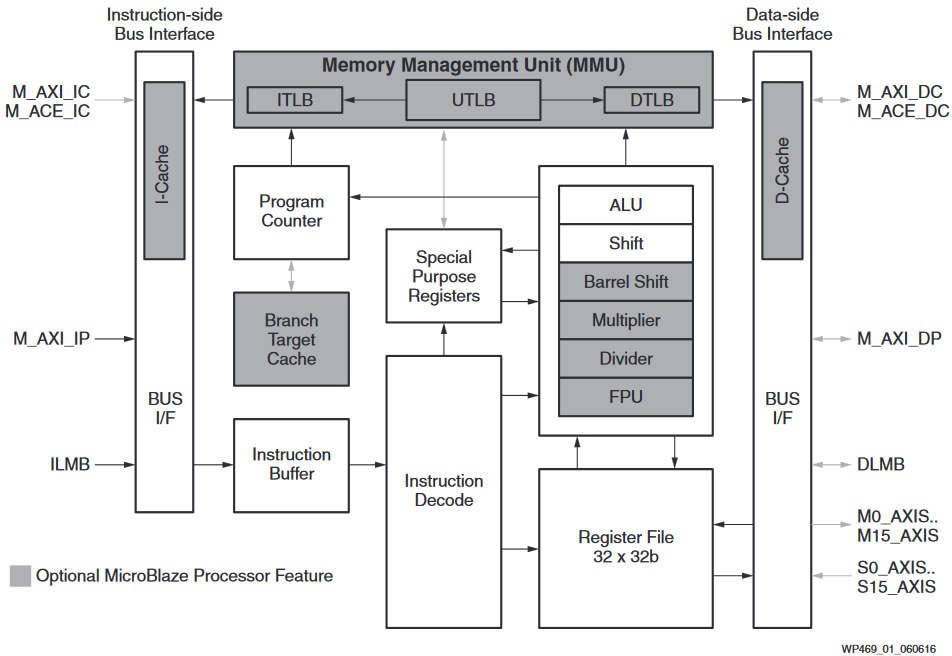
Рис. 2. Структурный вид ядра MicroBlaze
В отличие от готовых процессоров, инструменты проектирования Xilinx поддерживают функции и потоки, такие как Vivado High-Level Synthesis, который позволяет создавать IP-адреса из C / C ++ и SystemC без необходимости вручную писать RTL.
1.6. СРЕДСТВО РАЗРАБОТКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ NIOS II SBT FOR ECLIPSE
Средство разработки программного обеспечения Nios II (SBT) для Eclipse - это интегрированная среда разработки для задач разработки программного обеспечения Nios II, таких как редактирование, сборка и отладка [7][7].
Основные возможности Nios II SBT for Eclipse это:
1) Инструменты на основе проектов Eclipse;
2) Шаблоны для создания программного обеспечения Nios II;
3) Компилятор для C и C ++ (GNU);
4) Поддержка библиотеки Newlib C;
5) Навигатор источника, редактор и отладчик;
6) Средства создания программного обеспечения;
7) Пакет поддержки пакета поддержки Nios II (BSP);
8) Quartus Prime Programmer;
9) Командная оболочка Nios II;
10) Полная документация и материалы для обучения.
1.7. СЕМЕЙСТВО ПЛИС CYCLONЕ V
Основой массива программируемой логики 28-нм семейства Cyclone V, в отличии от других семейств серии Cyclone, являются адаптивные ло- гические модули (также, как в сериях Arria и Stratix). Кроме этого, микро- схемы семейства Cyclone V содержат блоки цифровой обработки сигналов переменной точности, блоки встроенного ОЗУ, высокоскоростные прие- мопередатчики, аппаратные IP-блоки (контроллеры PCI-Express и кон- троллеры внешней синхронной памяти), и средства защиты проекта от не- санкционированного копирования, и модификации [8][8].
Семейство Cyclone V имеет в своем составе микросхемы, которые со- держат такие инновационные решения, как аппаратный процессорный блок, основой которого является одно- или двухъядерный процессор ARM Cortex A9.
Семейство Cyclone V состоит из следующих подсемейств:
1) Cyclone V E – не содержит встроенных трансиверов и аппаратных кон- троллеров PCI Express;
2) Cyclone V GX – содержит встроенные трансиверы с максимальной ско- ростью передачи данных 3.125 Гбит/с;
3) Cyclone V GT – содержит встроенные трансиверы с максимальной ско- ростью передачи данных 5 Гбит/с;
4) Cyclone V SE – содержит аппаратный процессорный блок (одно- или двухъядерный);
5) Cyclone V SX – содержит двухъядерный аппаратный процессорный блок и встроенные трансиверы с максимальной скоростью передачи данных 3.125 Гбит/с;
6) Cyclone V ST– содержит двухъядерный аппаратный процессорный блок и встроенные трансиверы с максимальной скоростью передачи данных 5 Гбит/с.
Для создания и отладки многопроцессорной системы была выбрана плата разработки представленная на рисунке 3. В основе данной платы ле- жит кристалл Altera Cyclone V 5CEBA4F17C8N.

Рис. 3. Внешний вид платы разработки
ГЛАВА 2. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
2.1. ПРЕИМУЩЕСТВА ИЕРАРХИЧЕСКИХ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
Мультипроцессорные системы обладают преимуществом повышенной производительности, но, почти всегда, обладают большей сложностью их разработки, включающей в себя используемые аппаратные средства и программное обеспечение. Идея использования нескольких процессоров для выполнения различных задач и использования на разных процессорах в режиме реального времени встроенных приложений получила широкую популярность. ПЛИС Altera обеспечивают идеальную платформу для раз- работки встроенных многопроцессорных систем, поскольку аппаратное обеспечение может быть легко модифицировано и настроено, используя инструмент Qsys для обеспечения оптимальной производительности системы. Увеличение возможностей ПЛИС Altera делают возможными системные конструкции со многими процессорами Nios II на одном кристалле. Кроме того, с мощным инструментом интеграции, таким как Qsys, различные конфигурации системы могут быть спроектированы, построены и оценены в короткие сроки. Qsys включает в себя иерархические структуры, снижая сложность системы за счет раздельного проектирования в дискретных подсистемах. Каждая подсистема экспортирует пользовательские интерфейсы, образующих иерархию подсистем.
2.2. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ NIOS II
Nios II SBT for Eclipse включает функции, помогающие в создании и отладки многопроцессорных систем. Несколько процессоров Nios II способны эффективно делиться периферией благодаря возможности ввода в систему дружественного арбитража, описанного при помощи Qsys. Поскольку возможности Qsys позволяют практически без усилий добавлять столько процессоров в систему, сколько будет необходимо, основное внимание в создании многопроцессорных систем больше не лежит в организации и подключении отдельных аппаратных компонентов. Задача построения многопроцессорных систем состоит в том, чтобы написать программное обеспечение для этих процессоров, которое позволит им эффективно работать вместе и не противоречить друг другу. [8][9]
Чтобы помочь предотвратить взаимодействие нескольких процессоров друг с другом, в систему, при помощи Qsys, введено ядро аппаратного мьютекса. Ядро аппаратного мьютекса позволяет различным процессорам получать доступ к общим периферийным устройством в течение определенного периода времени. Это временное владение периферией защищает общее периферийное устройство от повреждений при одновременном действии на него нескольких процессоров.
Чтобы предотвратить общее воздействие на периферию, необходимо написать программное обеспечение, которое ждет получения разрешения от мьютекса на подключение к общему периферийному устройству, обеспечивая взаимно-эксклюзивный доступ.
Nonatomic тестовая и установочная операция имеет серьезный риск: два процессора могут одновременно проверить флаг и определить, что ни один процессор не имеет доступа. Если оба процессора подключаются к периферийному устройству, они нарушают взаимное исключение.
Atomic тестовая и установочная операция позволяет избежать этого риска, поскольку её нельзя прерывать. Данная операция позволяет процессору проверять право доступа и приобретать права владения ресурса за одну операцию.
Тот факт, что операция не может быть прервана, также обеспечивает, защиту от переключения системных задач во время тестирования или при- обретения/освобождения мьютекса процессором.
Ядро аппаратного мьютекса обеспечивает семафор для взаимоисключающего доступа к любой периферии. Программное обеспечение определяет это периферийное устройство и отвечает за равномерное использование мьютекса API (англ. интерфейс прикладного программирования) для обеспечения взаимно-исключающего доступа каждый раз, когда периферийное устройство доступно.
Nios II SBT for Eclipse поддерживает отладку программного обеспечения в многопроцессорных системах, позволяя запускать и останавливать несколько сеансов отладки программного обеспечения для одновременно работающих процессоров.
2.3. КОНСТРУКЦИИ АППАРАТНЫХ СРЕДСТВ ДЛЯ СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ ПЕРИФЕРИЙНЫХ УСТРОЙСТВ
2.3.1. ОСНОВНОЕ РАЗДЕЛЕНИЕ
Многопроцессорные системы Nios II делятся на две основные категории: те, которые разделяют периферийные устройства и те, в которых каждый процессор является автономным и не разделяет периферийные устройства с другими процессорами.
2.3.2. АВТОНОМНЫЕ МУЛЬТИПРОЦЕССОРЫ
Хотя автономные многопроцессорные системы содержат несколько процессоров, эти процессоры полностью автономны и не общаются друг с другом, как если бы они были полностью отдельными системами. По своей конструкции системы такого типа не используют общие периферийные устройства, и поэтому процессоры не могут мешать друг другу. По- этому такие системы, как правило, менее сложны и создают меньше проблем. На рисунке 4 схематически изображена система из двух автономных процессоров.
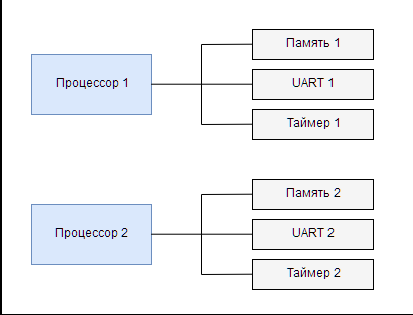
Рис. 4. Система из двух автономных процессоров
2.3.3. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ С ОБЩЕЙ ПЕРИФЕРИЕЙ
Многопроцессорные системы, с общими периферийными устройства- ми, могут создавать множество проблем. Для предотвращения этого в Qsys существуют функции, которые позволяют надежно реализовать многопроцессорные системы с общей периферией. Однако создать данную систему не всегда просто.
На рисунке 5 показана блок-схема простой многопроцессорной системы, в которой два процессора совместно используют общую память.
На данном рисунке два экземпляра процессоров ис- пользуют, помимо индивидуальной периферии, раздел общей памяти, в котором может находиться их инициализирующее программное обеспечение или их общие данные, которые они могут считывать и переписывать. Сложность данных систем – это обеспечение взаимно исключающего доступа к общей периферии, т.к. одновременное обращение к ней может вызвать повреждении данных и, в худшем случаи, вывести ее из строя.
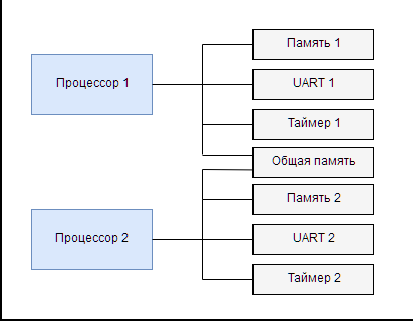
Рис. 5. Система из двух процессоров с общей памятью
2.4. ИСПОЛЬЗОВАНИЕ ОБЩИХ ПЕРИФЕРИЙНЫХ УСТРОЙСТВ В МНОГОПРОЦЕССОРНЫХ СИСТЕМАХ
2.4.1. РАЗДЕЛЯЕМЫЕ ПЕРИФЕРИЙНЫЕ УСТРОЙСТВА
Периферийные устройства считаются разделяемыми, когда к ним могут обращаться несколько процессоров. Панель соединений Qsys определяет, к каким аппаратным компонентам может получить доступ каждый из отдельных процессоров Nios II.
Совместное использование периферийных устройств может быть очень мощной функцией многопроцессорных систем, но нужно заботиться об определении того, какие периферийные устройства системы являются общими, и как различные процессоры взаимодействуют с ними.
В неиерархической системе периферийные устройства можно сделать общими, просто подключив их к нескольким основным интерфейсам процессора в матрице соединений Qsys. В иерархической системе, периферийные устройства также могут быть доступны для совместного использования с процессорами за пределами подсистемы, содержащей периферийное устройство, экспортируя его интерфейс. Ведущие интерфейсы процессора получают доступ к периферийным устройствам через соединения в матрице соединений Qsys с экспортированными интерфейсами под- системы содержащий периферийное устройство. На рисунке 6 показан пример того, как выглядит соединение двух интерфейсов процессоров в матрице соединений Qsys.
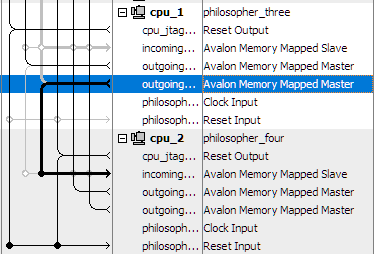
Рис. 6. Пример соединения в матрице соединений Qsys
Основной интерфейс процессора CPU1 может получить доступ к периферийному устройству, расположенному в подсистеме CPU2, посредством соединения с шиной Avalon Memory-Mapped (Avalon-MM) pipeline bridge. Avalon-MM pipeline bridge также обеспечивает механизм для одновременного соединения ведомого интерфейса как к локальному мастер-процессору, так и внешнему ведущему процессору в другом месте иерархии. В этом случае Avalon-MM pipeline bridge экспортирует ведомый, а не ведущий, интерфейс периферии напрямую.
Программное обеспечение, запущенное на каждом процессоре, отвечает за взаимную координацию при доступе к совместно используемым периферийным устройствам с другими процессорами в системе при помощи использования мьютекса. Процессор может взаимодействовать с периферией другого процессора только при условии, что в этот момент он владеет взаимно-исключающим доступом одновременно к своему мьютексу и мьютексу соседнего процессора.
На рисунке 7 показана примерная многопроцессорная система, построенная в Qsys. Компонент, указанный снизу, shared_memory (разделенная память), считается разделяемым, потому что ведущие порты данных и команд обоих процессоров подключены к ведомому интерфейсу памяти. Поскольку cpu1 и cpu2 физически способны одновременно записывать блоки данных в совместно используемую память, программное обеспечение для этих процессоров должно использовать мьютексы для защиты целостности данных, хранящихся в общей памяти.
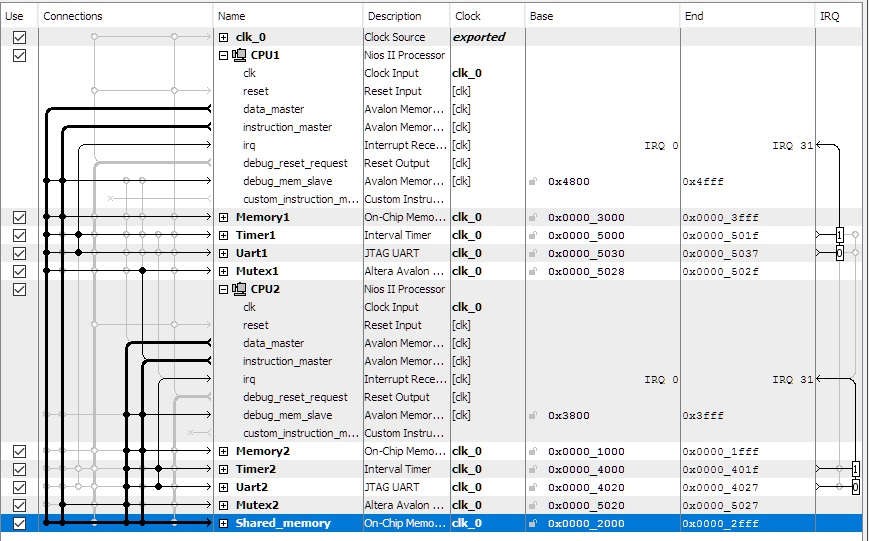
Рис. 7. Совместное использование памяти многопроцессорной системой.
2.4.2. СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ ПАМЯТИ
Наиболее распространенным типом общей периферии в многопроцессорных системах является память. Общая память может использоваться для чего угодно: от простого флага, целью которого является состояние связи между процессорами, до сложных структур данных, которые совместно вычисляются многими процессорами одновременно.
Если компонент памяти должен содержать программную память для нескольких процессоров, то каждый процессор, совместно использующий память, должен использовать отдельную область для инициализации исполняемого кода. Процессоры не могут использовать одну и ту же область памяти для программного пространства. Каждый процессор должен иметь свои собственные уникальные разделы: .text, .rodata, .rwdata, .heap и .stack . Для получения информации о том, как каждый процессор совместно ис- пользует компонент памяти существует программа в выделенной области этой памяти. [9][10]
Если для системы необходим доступ к общему разделу памяти, где хранятся данные, с которыми работают процессоры, то мы должны подключить ведомый интерфейс памяти к ведущим интерфейсам этих процессоров. Все эти соединения необходимо выполнить в иерархическом файле описания верхнего уровня, а не внутри каждой подсистемы отдельно.
Совместное использование памяти данных между несколькими процессорами может быть сложным, поскольку она может работать на запись и на чтение. Если один процессор пишет в определенную область общего доступа, и, в то же время, другой процессор считывает или записывает данные в этой области, то это, вероятно, приведет к повреждению данных, что вызовет ошибки, как минимум, исполняемой программы и, возможно, вызовет сбой всей системы.
Процессоры, использующие общую память или общие интерфейсы, нуждаются в механизме информирования друг друга, чтобы предотвратить их общее воздействие. В следующем разделе описан такой механизм: the Altera hardware mutex core (ядро аппаратного мьютекса). В некоторых случаях ядро мьютекса не обязательно. Например, не требуется мьютекс с односторонним буфером обмена, где только один процессор пишет в буфер, а все остальные процессоры могут работать только в режиме чтения. Однако безопасное совместное использование периферийных устройств без мьютекса возможно, но является более сложным в плане обеспечения взаимно-исключающего доступа.
2.4.3. ЯДРО АППАРАТНОГО МЬЮТЕКСА
Процессор Nios II обеспечивает защиту общих периферийных устройств, обращаясь к ядру аппаратного мьютекса, которое гарантирует, что только один процессор имеет право владения мьютексом в любой момент времени. Ядро аппаратного мьютекса не является внутренней особенностью процессора Nios II. Это простой компонент Qsys.
Термин «мьютекс» означает взаимное исключение. Мьютекс позволяет взаимодействующим процессорам согласовать то, что только один процессор будет получать временный доступ к определенной аппаратной периферии. Это полезно для защиты периферийных устройств от повреждения данных, которые могут появиться при использовать периферийного устройства одновременно несколькими процессорами.
Ядро мьютекса действует как совместно используемое периферийное устройство, предоставляющее собой Atomic тестовую и установочную операцию, которая позволяет процессору проверить, доступен ли мьютекс, и, если это так, завладеть блокировкой мьютекса в одну операцию. Когда процессор завершит работу с совместно используемым периферийным устройством, связанный с мьютексом, процессор освобождает блокировку мьютекса. После этого другой процессор может получить блокировку мьютекса и использовать общую периферию. Без мьютекса такой функции обычно требует процессор для выполнения двух отдельных команд - тестирования и установки, между которыми процессор также может проверить работоспособность и успешность выполнения. В этой ситуации появилось бы два процессора, которые, могли бы определить, что они успешно приобрели взаимоисключающий доступ, хотя это не так.
Ядро мьютекса физически не защищает периферийные устройства в системе от одновременного доступа к ним нескольких процессоров. Программное обеспечение, запущенное на процессорах, несет ответственность за соблюдение правил. Программное обеспечение должно быть написано так, чтобы перед доступом к общему периферийному устройству было необходимо получить мьютекс.
Другой тип мьютекса, называемый программным мьютексом, является общим для многих операционных систем. В компьютерном программировании мьютекс является программным объектом, который позволяет нескольким потокам программ совместно использовать один и тот же ресурс, такой как доступ к файлам, но не одновременно. Когда программа запускается, создается мьютекс с уникальным именем. После этого этапа любой поток, который нуждается в ресурсе, должен блокировать мьютекс из других потоков, пока он использует ресурс. Мьютекс устанавливается для разблокировки, когда данные больше не нужны или процедура завершена. [3][11]
Ядро аппаратного мьютекса является компонентом Qsys с интерфейсом Avalon, который использует логику, чтобы гарантировать, что только одному процессору предоставляется блокировка мьютека в любой момент времени. Пока каждый процессор находится в ожидании соответствующего мьютекса для использования, связанного с ним общего периферийного устройства, это периферийное устройство защищено от повреждений, вызванных одновременным доступом нескольких процессоров. Аппаратное ядро мьютекса само по себе не имеет никакого подключения к общему периферийному устройству; это просто один из видов семафора.
2.4.4. СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ ПЕРИФЕРИЙНЫХ УСТРОЙСТВ
Совместное использование периферийных устройств в многопроцессорных системах вызывает некоторые проблемы, обычно приводящих к неэффективному проектированию системы. Самые большие проблемы возникают для периферийных устройств, управляемых прерываниями. Если периферийному устройству разрешено вызывать прерывания у всех процессоров, разделяющих его, нет надежного способа гарантировать, какой процессор ответит первым. Кроме того, если периферийное устройство используется в качестве устройства ввода для нескольких процессоров, становится трудно определить, какой процессор должен собирать данные с устройства. Хотя для этого может быть создана сложная система связей, такая система выходит за рамки настоящего документа и не предоставляет собой абстрактный слой библиотек Nios II (HAL).
При построении любой системы, особенно многопроцессорной системы, рекомендуется только устанавливать соединения между процессорами и периферийными устройствами, которые требуют прямой связи. Напри- мер, если процессор работает и использует только один встроенный чип памяти, нет необходимости подключать этот процессор к любой другой памяти в системе. Физически отключая процессор от памяти, он не взаимодействует с ней, тем самым экономит ресурсы ПЛИС и гарантирует, что процессор никогда не повредит данные хранящиеся в этой памяти.
В многопроцессорных системах необходимость подключения различных компонентов очень зависит от реализации разработки. Поэтому при проектировании многопроцессорных систем необходимо убедиться, что каждый компонент подключен к желаемому процессору. Наиболее лучше компоненты управляются одним процессором. Если процессор A требует доступ к периферийному устройству, которое подключено к процессору Б и управляется им, процессор A должен запросить у процессора B, чтобы он выполнял операции с периферийным устройством от имени процессора A. Для этой цели мы можем использовать общую память, защищенную мьютексом для связи между двумя процессорами.
2.5. ПЕРЕКРЫТИЕ АДРЕСНОГО ПРОСТРАНСТВА
Однопроцессорные системы обычно не допускают более одного ведомого периферийного устройства, занимающего одно и то же адресное пространство, поскольку такая организация вызывает конфликты. Однако в многопроцессорных системах отдельные ведомые периферийные устройства могут занимать один и тот же базовый адрес без конфликта, поскольку каждое периферийное устройство управляется другим процессором. Поскольку не каждое периферийное исключительно устройство ведомого обязательно обрабатывается каждым процессором, каждый процессор может иметь другое представление о системе. Если процессор А подключен к ведомому периферийному устройству, записанному по адресу 0x8a00, процессор Б может подключается к отдельному ведомому периферийному устройству, которое записано по тому же адресу, до тех пор, пока процессор А не подключен к периферийному устройству процессора Б, а процессор Б – не подключен к периферийному устройству процессора А. В сущности, двухточечное соединение позволяет двум процессорам иметь отдельные адресные пространства. На рисунке 8 показан блок диаграммы примерной многопроцессорной системы с различными подчиненными компонентами с одним базовым адресом.
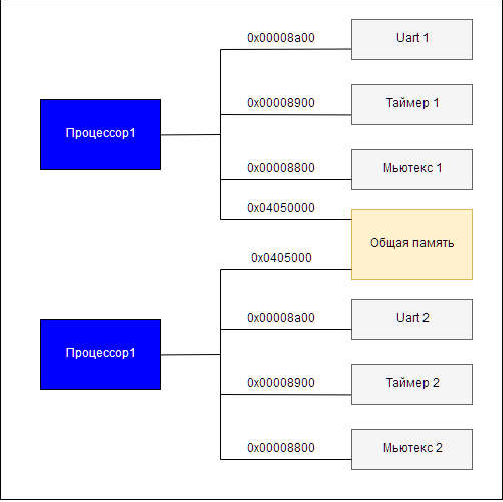
Рис. 8. Многопроцессорная ведомая периферия, с одним базовым адресом
2.6. ПРОЕКТИРОВАНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ НЕСКОЛЬКИХ ПРОЦЕССОРОВ
2.6.1. ПРОГРАММИРОВАНИЕ ПАМЯТИ
При создании многопроцессорной системы мы можем запустить про- граммное обеспечение для несколько процессоров из одного физического запоминающего устройства. Программное обеспечение для каждого про- цессора должно располагаться в своем собственном уникальном регионе памяти, но эти регионы могут находиться в том же физическом запоми- нающем устройстве. Для программного обеспечения каждого процессора требуется 8 килобайт (КБ) памяти для кода программы и для данных. Пер- вый процессор может использовать область между 0x0 и 0x1FFF памяти на кристалле в качестве своего программного пространства, а второй процес- сор может использовать область между 0x2000 и 0x3FFF.
Nios II SBT предоставляет собой простую схему разбиения памяти, которая позволяет использовать несколько процессоров для запуска своего программного обеспечения из разных регионов одной и той же физической памяти. SBT использует адрес исключения для каждого процессора при определении области памяти, из которой каждый процессор может выпол- нить свой код. Разработчик системы устанавливает адрес для каждого про- цессора не зависимо от Qsys. [10][12]
Nios II SBT гарантирует связь программного обеспечения процессора и его места в памяти. Он использует адреса исключений, чтобы вычислить, где находится каждая секция кода. Nios II SBT позиционирует область ко- да каждого процессора в памяти, содержащего адрес исключения.
Если программное обеспечение для нескольких процессоров связано с одной физической памятью, то Nios II SBT использует адрес исключения каждого процессора для определения базового адреса региона. Область кода заканчивается на адресе исключения для следующего процессора определённого в той же памяти. Процессору с наивысшим адресом исключения присваивается область кода, которая продолжается до конца всего адресного диапазона памяти.
Каждый процессор имеет пять разделов компоновщика по умолчанию. Независимо от того, принадлежит ли процессор однопроцессорной или многопроцессорной системе, секции компоновщика по умолчанию имеют следующий вид:
.text - исполняемый код;
.rodata - любые данные только для чтения, используемые при выполнении кода;
.rwdata - раздел где хранятся переменные значения чтения, записи и указатели;
.heap - раздел где расположена динамически распределенная память;
.stack - раздел параметров функции-вызова и других временных данных.
Эти разделы должны быть связаны и расположены по фиксированным адресам в памяти. На рисунке 9 приведён структурный вид этих секций.
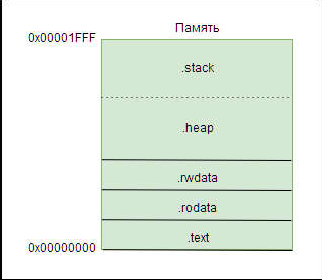
Рис. 9. Секции компоновщика одного процессора.
Рис. 9. Секции компоновщика одного процессора
В многопроцессорной системе может быть полезно использовать единую память для хранения всех секций кода каждого процессора. В этом случае адрес исключения для каждого процессора в Qsys определяет границы между тем, где заканчивается кодовая секция одного процессора и начинается секция кода следующего процессора. [10][13]
Например, можно представить систему, в которой внутренняя память занимает следующие специфические для процессора диапазоны адресов: 0x00050000 to 0x0005FFFF—cpu_top процессор;
0x04000000 to 0x0405FFFF—Nios II процессор в любой подсистеме.
Процессору cpu_top и процессорам в каждой подсистеме выделено 8 КБ встроенной памяти каждому для запуска своего программного обеспе- чения. Если мы используем Qsys для установки их адресов исключений на 8КБ памяти, то Nios II SBT автоматически разбивает память на кристалле на основе этих адресов исключений.
На рисунке 10 приведён пример разделение памяти для системы построенной в данной работе.
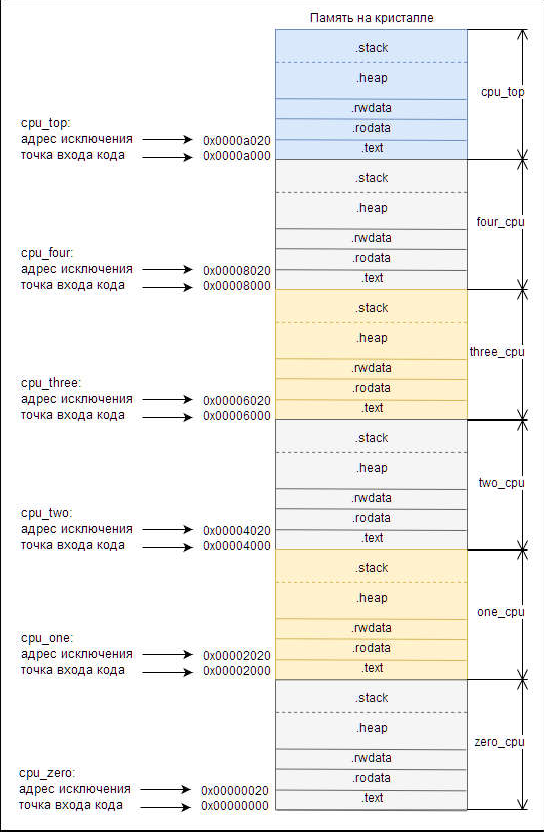
Рис.10. Разбиение встроенной памяти для шести процессоров
На этом рисунке показана карта адресов смещений во встроенной памяти определенной в верхнем уровне иерархии. Встроенная память рассматривается процессорами в каждой подсистеме в другом адресном месте.
Этот адрес получается путем добавления базового адреса встроенной памяти, который определен в верхнем уровне, к базовому адресу шины Avalon-MM pipeline bridge, используемой подсистемами для доступа к компонентам верхнего уровня.
В младших шести битах адреса исключения всегда устанавливается 0x20. Смещение 0x0 – это адрес где процессор Nios II должен запустить свой код сброса, поэтому адрес исключения должен быть помещен в другом месте. Смещение 0x20 используется, потому что оно соответствует одной строке кэша команд. 0x20 байтов кода сброса инициализируют кеш команд, а затем разветвляются по адресам исключения для системного кода этого процессора.
Необходимо соблюдать осторожность при разбиении физической памяти на разделы кода нескольких процессоров. В Qsys или Nios II SBT нет гарантий, что мы предоставили достаточно места для кода, стека и кучи разделов каждого процессора. Если в памяти выделяется неадекватное пространство кода, стека или разделов то это может вызвать переполнение и повреждение исполняемого кода процессора.
АДРЕСА ЗАГРУЗКИ
В многопроцессорных системах каждый процессор должен загружаться из своего собственного региона памяти. Несколько процессоров не могут успешно загружаться из одного и того же бита исполняемого кода, находящегося в том же адресном пространстве одной энергонезависимой памяти. Загрузочная память может быть разделена также, как и программная память, но понятия разделов и ссылок не вызывают беспокойства, поскольку код загрузки обычно просто копирует реальный программный код туда, где он определён в ОЗУ, а затем его исполняет. Для загрузки нескольких процессоров из отдельных регионов на одной энергонезависимой памяти, необходимо просто установите каждый адрес сброса процессора в то место, откуда мы должны загрузить этот процессор. Нужно убедиться, что мы оставили достаточно места между адресами загрузки, для хранения полезной нагрузки. На рисунке 11 приведён пример разделения памяти для загрузки трёх процессоров.
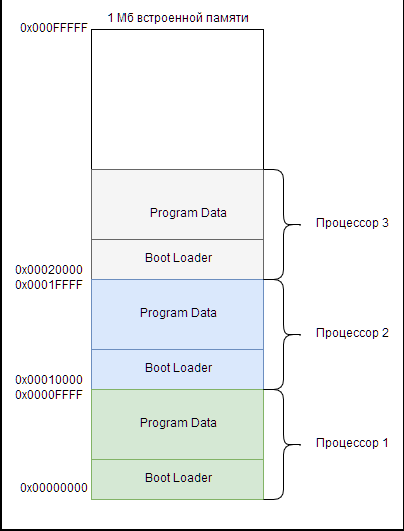
Рис. 11. Разделение памяти для загрузки трех процессоров
Прошивальщик флэш-памяти для Nios II может загрузить загрузочный код для не скольких процессоров в одно устройство флэш-памяти. Он просматривает адрес сброса каждого процессора и использует этот адрес сброса для вычисления смещения во флэш-памяти, где зашит код. Необходим проявлять осторожность при подключении нескольких процессоров Nios II к одному CFI (Common Flash Interface - Общий интерфейс памяти). Поскольку в драйвере CFI нет механизма защиты от одновременного доступа к ней нескольких процессоров - операция чтения может возвращать испорченные данные. [11][14]
В частности, если процессор попытается прочесть с устройства флэш-памяти CFI, которое находится в режиме записи, то данная операция будет работать неправильно. Если другой процессор выдает запрос к устройству флэш-памяти непосредственно перед чтением первого процессора, то память будет находиться в режиме чтения команд во время обработки запроса, а операция чтения не сможет правильно считать данные. По этой причине Altera рекомендует назначить один процессор Nios II в качестве флэш-мастера, который может работать с устройством флэш-памяти и на чтение, и на запись, в любой многопроцессорной системе с общим устройством флэш-памяти. Назначенный процессор может считывать данные с устройства флэш-памяти для других процессоров.
ОТЛАДКА МНОГОПРОЦЕССОРНЫХ ПРОЕКТОВ NIOS II
Nios II SBT for Eclipse включает в себя ряд функций, которые могут помочь в разработке программного обеспечения для многопроцессорных систем. Наиболее примечательной является способность Nios II SBT for Eclipse для одновременной отладки нескольких процессоров. [12][15] Несколько сеансов отладки могут выполняться одновременно в многопроцессорной системе и могут быть приостановлены и возобновлены для каждого процессора независимо. Точки остановы также могут быть установлены индивидуально для каждого процессора. Если один процессор попадает в точку остановы, он не останавливается и не влияет на работу других процессоров. Сеансы отладки можно запускать и останавливать независимо.
ЗАКЛЮЧЕНИЕ
По результатам данной курсовой работы можно сделать следующие основные выводы:
1. Исследованы основные методы синтеза процессоров и периферии на кристаллах ПЛИС.
2. Изучены программные среды для создания и отладки устройств в составе ПЛИС.
3. Исследованы и изучены основные аспекты многопроцессорных систем с общей периферией и межпроцессорным доступом.
Полученные результаты позволяют сделать вывод, что на основе разработанных методов может быть реализовано цифровое устройство, в основе которого лежит многопроцессорная система, обеспечивающая обработку цифровых потоков и выполнение заданных алгоритмов.
Таким образом, задачи курсовой работы решены, а поставленная цель достигнута.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Программируемые логические интегральные схемы (ПЛИС) // URL:http://digteh.ru/digital/PLD/ (дата обращения 23.06.2018).
2. Компания ГАММА, электронные компоненты. QUARTUSII // URL:http://www.icgamma.ru/linecard/altera/kits/quartus2/ (дата обращения 22.06.2018).
3. Creating a System with Qsys // URL:https://documentation.altera.com/#/link/mwh1409960181641/mwh140995 8596582 (дата обращения 23.06.2018).
4. Ефремов Н. В., Бородин А. А. Инструментальные средства проектирова- ния и отладки систем на программируемых кристаллах компании Altera: Учебное пособие. М.: Изд-во Московского государственного университета леса, 2012.
5. Spartan-6 Device Handbook // URL:http://www.xilinx.com/support/documentation/user_guides/ug389.pdf (да- та обращения 23.06.2018).
6. MicroBlaze Processor Reference Guide // URL:https://www.xilinx.com/support/documentation/sw_manuals/xilinx2017_1/ ug984-vivado-microblaze-ref.pdf (дата обращения 22.06.2018).
7. The Nios II (Gen2) Software Developers Handbook (ver 2015.05.19)URL:https://www.altera.com/documentation/lro1419794938488.html (дата обращения 20.06.2018).
8. Cyclone V Device Handbook. // URL:https://www.altera.com/content/dam/alterawww/global/en_US/pdfs/literature/hb/cyclone-v/cyclone5_handbook.pdf (дата обращения 20.06.2018).
9. Nios II Multiprocessor Design Example // URL:https://www.altera.com/support/support-resources/design- examples/intellectual-property/embedded/nios-ii/exm-multi-nios2- hardware.html (дата обращения 23.06.2018).
10. Стешенко В.Б. ПЛИС фирмы «ALTERA»: элементная база, система проектирования и языки описания аппаратуры: М.: изд-во ДМК Пресс, Додэка, 2015.
11. Методические указания по экономическому обоснованию выпускных квалификационных работ бакалавров: сост. О.Г. Алексеева, СПб.: Изд- во СПбГЭТУ “ЛЭТИ”, 2013.
12. Экономика предприятия учебник: под ред. проф. В. М. Семенова. М.: Питер, 2008.
-
Программируемые логические интегральные схемы (ПЛИС) // URL:http://digteh.ru/digital/PLD/ (дата обращения 23.06.2018). ↑
-
Программируемые логические интегральные схемы (ПЛИС) // URL:http://digteh.ru/digital/PLD/ (дата обращения 23.06.2018). ↑
-
Компания ГАММА, электронные компоненты. QUARTUSII // URL:http://www.icgamma.ru/linecard/altera/kits/quartus2/ (дата обращения 22.06.2018). ↑
-
Компания ГАММА, электронные компоненты. QUARTUSII // URL:http://www.icgamma.ru/linecard/altera/kits/quartus2/ (дата обращения 22.06.2018). ↑
-
Spartan-6 Device Handbook // URL:http://www.xilinx.com/support/documentation/user_guides/ug389.pdf (да- та обращения 23.06.2018). ↑
-
MicroBlaze Processor Reference Guide // URL:https://www.xilinx.com/support/documentation/sw_manuals/xilinx2017_1/ ug984-vivado-microblaze-ref.pdf (дата обращения 22.06.2018). ↑
-
The Nios II (Gen2) Software Developers Handbook (ver 2015.05.19)URL:https://www.altera.com/documentation/lro1419794938488.html (дата обращения 20.06.2018). ↑
-
Cyclone V Device Handbook. // URL:https://www.altera.com/content/dam/alterawww/global/en_US/pdfs/literature/hb/cyclone-v/cyclone5_handbook.pdf (дата обращения 20.06.2018). ↑
-
Cyclone V Device Handbook. // URL:https://www.altera.com/content/dam/alterawww/global/en_US/pdfs/literature/hb/cyclone-v/cyclone5_handbook.pdf (дата обращения 20.06.2018). ↑
-
Nios II Multiprocessor Design Example // URL:https://www.altera.com/support/support-resources/design- examples/intellectual-property/embedded/nios-ii/exm-multi-nios2- hardware.html (дата обращения 23.06.2018). ↑
-
Creating a System with Qsys // URL:https://documentation.altera.com/#/link/mwh1409960181641/mwh140995 8596582 (дата обращения 23.06.2018). ↑
-
Стешенко В.Б. ПЛИС фирмы «ALTERA»: элементная база, система проектирования и языки описания аппаратуры: М.: изд-во ДМК Пресс, Додэка, 2015. ↑
-
Стешенко В.Б. ПЛИС фирмы «ALTERA»: элементная база, система проектирования и языки описания аппаратуры: М.: изд-во ДМК Пресс, Додэка, 2015. ↑
-
Методические указания по экономическому обоснованию выпускных квалификационных работ бакалавров: сост. О.Г. Алексеева, СПб.: Изд- во СПбГЭТУ “ЛЭТИ”, 2013. ↑
-
Экономика предприятия учебник: под ред. проф. В. М. Семенова. М.: Питер, 2008. ↑

- Виды и пути достижения конвертируемости национальных валют (Конвертируемость валюты)
- Порядок правового регулирования защиты права собственности
- Нотариат в РФ (Институт нотариата в России)
- Система вознаграждения персонала организации ООО «Омеко-труд»
- Политика регулирования численности персонала в системе стратегического управления кадровым направлением деятельности организации
- Правовые основы организации нотариата (Дореволюционный период развития нотариата)
- Разработка конфигурации «Учет реализации лекарственных препаратов через аптечную сеть»»
- Классификация языков программирования. Критерии выбора среды и языка разработки программ (Анализ современных языков программирования)
- Кадровая стратегия в системе стратегического управления организацией (Сущность стратегического управления в организации)
- Роль мотивации в поведении организации (Понятие и сущность морального и материального стимулирования)
- Аналитические регистры налогового учета по налогу на прибыль (Сущность налога на прибыль организаций и его основные элементы)
- Роль финансового рынка в мобилизации и распределении финансовых ресурсов