
Методы кодирования данных (Программная реализация алгоритма кодирования Хаффмана)
Содержание:

ВВЕДЕНИЕ
Необходимость кодирования данных появилась раньше, чем появился первый персональный компьютер.
Для любого метода кодирования характерно наличие начальных данных, наименьшая единица которых – бит, а наибольшая - несколько бит, байт или несколько байт.
Методику, изобретенную Дэвидом Хаффманом, можно без преувеличения назвать популярнейшим способом кодировки. Данная методика — это простейший алгоритм, призванный создавать кодировки с изменчивой длиной, имеющие самое малое среднее протяжение. Многие приложения для ПК, сжимающие информацию, основываются на данной методике. Отдельные приложения полностью используют методику, а другие пользуются методом частично на разных уровнях. Методика Хаффмана позволяет достичь идеала в сжатии данных и довести их до энтропического состояния при равенстве символьных данных степени с отрицательным значением «два». Данная методика использует также выстраивание древа кодировки от низа до верха. После этого производится скольжение в нижний уровень, чтобы создать личные кодировки, начиная с правой стороны в сторону левой.
Объект исследования: процесс кодирования данных.
Предмет исследования: методы кодирования данных.
Цель курсовой работы – анализ методов кодирования данных.
Для достижения поставленной цели требуется решить следующие задачи:
1) рассмотреть теоретические основы кодирования данных;
2) рассмотреть методы кодирования данных;
3) разработать программу для демонстрации метода кодирования.
1. Теоретические основы кодирования данных
1.1 Основные понятия кодирования данных
Остановимся на базовых понятиях, которые имеют отношение к кодированию данных. С целью отправки в канал связи информация трансформируется в сигнал. Символы, которые используются в формировании данных, формируют первичный алфавит. Любому символу соответствует определённая степень вероятности того, что он будет содержаться в сообщении. Для любой переданной информации всегда имеется некоторый сигнал, который является строгой последовательностью кодовых комбинаций.
Кодирование представляет собой трансформацию информации в комбинацию кода.
Под кодом понимается структура соответствия передаваемой информации и сигналов.
Кодер – это механизм, который выполняет функцию кодирования. Декодер – это механизм, который решает обратную задачу, трансформирует код в распознаваемую информацию.
Алфавит – совокупность допустимых частей кода.
X = {xi}, где i = 1, 2,..
Основание кода – это число возможных его элементов. Если код состоит только из нулей и единиц, то основание кода равно двум.
Кодовая комбинация – итоговая комбинация символов алфавита. Значность комбинации – количество её элементов.
Объём кода – количество отличающихся кодовых комбинаций.
Кодирование может быть использовано для решения следующих задач:
1) Достижение оптимального кодирования за счёт наиболее высокой скорости при передаче данных.
2) Снижение влияния помех в процессе передачи данных.
Согласно данным задачам, теория кодирования имеет две главные отрасли развития:
1. Поиск наиболее оптимального кодирования. Происходит поиск комбинаций, которые без создания дополнительных помех делают скорость передачи данных наиболее высокой, но учитывая возможности самого канала связи.
2. Устойчивость к помехам. Происходит поиск комбинаций, которые увеличивают точность передачи данных в каналах, которые имеют помехи.
Впервые научные труды по кодированию изложил К. Шеннон. Он изучал, как данные передаются по техническим каналам связи. Шеннон понимал кодирование как преобразование информации от одной системы к другой. В качестве примера можно привести трансформацию латинских символов в код азбуки Морзе, с целью его дальнейшей передачи по телеграфу или радио. Данное кодирование появилось в связи с необходимостью адаптации кода к имеющимся техническим возможностям работы с данными.
Под декодированием понимается обратная трансформация кода к виду начальной символьной структуры. В качестве примера можно привести трансформацию азбуки Морзе в латинские символы.
Если рассматривать декодирование более широко, то это процесс, который предоставляет исходное сообщение в первоначальном его виде. В качестве примера, запись сообщения латинскими буквами будет являться кодированием, а его чтение декодированием.
Кодировать одинаковые данные можно по-разному. В качестве примера, русские слова мы записываем русскими буквами. Но в это же время их можно записать буквами английского алфавита. Многие так делают, отправляя SMS, если на телефоне отсутствует возможность писать по-русски, или, набирая электронное письмо, если операционная система компьютера не предусматривает русский язык.
Рассмотренные примеры подтверждают одно очень важное правило: кодирование одних и тех же данных возможно с применением различных методов. На применение того или иного метода влияют различные условия, например, задача кодирования или имеющиеся средства.
Также выбор метода кодирования данных может зависеть от того, каким образом предполагается осуществление обработки. Продемонстрируем это на примере представления чисел. Применив латинские символы, имеется возможность написать число «сорок девять». Применив десятичную систему исчисления, это же число будет написано так: «49». Использование десятичной системы исчисления является более коротким и удобным для того, чтобы проводить подсчёты. Как более просто выполнять вычисления: «сорок девять разделить на семь» или «49/7»? Очевидно — второй способ является более удобным.
Иногда требуется оставить число без искажений. С этой целью его более удобно оставить в текстовом виде. В качестве примера, в банковских документах, как правило, денежные суммы отражаются в текстовом виде: «пятьсот тридцать два руб.», а не «532 руб.». Это является важным в данном случае, так как при искажении одного символа в цифровой записи приведёт к изменению всего значения. Что касается текстового вида, даже при наличии грамматической ошибки смысл останется прежним.
Иногда появляется необходимость сделать данные засекреченными, чтобы они могли быть просмотрены только узким кругом лиц. Это называется защитой от несанкционированного доступа. При этой необходимости данные шифруются.
Шифрование – трансформация читаемой формы документа в зашифрованную. Дешифрование является обратной процедурой, при которой происходит восстановление читаемой формы. Процесс шифрования отличается от кодирования тем, что при шифровании используется секретный метод, который знают только источник и адресат. Разработкой методов шифрования занимается наука криптография.
Главнейшим свойством происшествий, произошедших случайным образом, является отсутствие уверенного и точного осуществления таких происшествий. Данное свойство ведет к появлению неточностей во время исполнения смежных с происшествиями опытов. Тем не менее, признается очевидность отличия неточностей для отдельных событий. На практике важнейшим свойством является навык четкой аналитики градации неточностей разных опытов. Этот навык нужен для того, чтобы можно было сравнить эксперименты и события в различном свете.
Для примера берем стандартные опыты «А» и «В»; усложненный опыт «А/В», в котором идет одновременное исполнение опытов «А» и «В». Опыт «А» включает в себя «х» результатов с одинаково точной вероятностью. «В», в свою очередь, включает в себя наличие только одного результата с такой степенью. Таким образом, становится очевидным факт превосходства неопределенного значения у опыта «А/В» над опытом «А», так как в данном опыте появляются еще и неопределенные вероятности от опыта «В». То есть, градация неопределенного состояния опыта «А/В» — это результат сложения неопределенных значений опытов «А» и «В», а именно:
 .
.
Условиям:

 ,
, 
при  удовлетворяет только одна функция -
удовлетворяет только одна функция -  :
:
 .
.
Рассмотрим эксперимент С, который содержит эксперименты и имеет вероятности . Общая неопределенность для эксперимента С будет:
Это последнее число будем называть энтропией эксперимента А, которое будет отражаться как Н(А).
Если «алфавит» содержит количество символов x, а количество задействованных элементарных сигналов – y, то в независимости от того, какой метод кодирования применяется, среднее количество элементарных сигналов, которое приходится на один символ алфавита, всегда будет больше или равным:
При этом его можно сделать максимально близким к данному отношению, если проводить сопоставление отдельных кодовых обозначений сразу длинными «блоками», которые будут содержать большое количество символов.
Остановимся на простом случае данных, которые были записаны некоторыми x «символами», вероятность появления которых в том или ином месте целиком характеризуется вероятностями р1, р2, … …, рх, где, р1 + р2 + … + рх = 1, при котором степень вероятности pi проявления i-й буквы в произвольном месте будет одна и та же, независимо от того, какие символы были во всех других местах. На практике, как правило, бывает по-другому, если взять русский язык, то на вероятность появления буквы сильно влияет предыдущая буква. Но если мы будем учитывать, как буквы зависят друг от друга, то дальнейшие рассмотрения станут очень сложными, но не окажут влияния на будущий результат.
Сделаем остановку на кодировках с двоичными системами. В таких системах обычно очень простое суммирование итогов кодировок, использующих неопределенную сумму стандартных сигнализаций. Можно рассмотреть простейшее событие, в пределах которого каждая кодировка — числовое последовательное выражение, состоящее из чисел «1» и «0». Эти числа заменяют символику события. При данном обозначении любая сумма с двоичным кодом использует отдельную методику, определяющую точную задуманную цифру, являющуюся, в свою очередь, равной «х» или меньше этого значения. При этой методике применяется некоторое количество вопросов с ответами только ДА/НЕТ (1/0). Все это в сумме заставляет применять двоичную кодировку.
Когда вероятные значения «Р1», «Р2», «Рх» указаны точно, идеальной кодировкой для отсылки сообщений с множеством символов является та кодировка, которая обладает самым меньшим количеством заданных вопросов при точных вероятных значениях «х» (двоичная символика или стандартная сигнализация).
Прежде всего, средняя сумма двоичной стандартной сигнализации сообщений с кодировкой в отношении единичного значения в стандартном событии в любом случае превышает или равняется «Н» (Н = - p1 log p1 – p2 log p2 - .. - pn log pn — энтропическое свойство опыта, распознающего единичные символы события). Таким образом подводится итог: при применении любой методики кодировки обязательно нужно минимально «ХН» символов с двоичным значением (при передаче данных из «Х» значений).
1.2 Классификация назначения и способы представления кодов
Классификация кодировок производится с использованием следующих критериев:
1. Основа — количество алфавитных значений, букв. Различаются бинарный и небинарный типы (m=2/m№2).
2. Протяженность суммы кодировки. Различаются равные (длина любой комбинации одинакова) и неравные (длина различается).
3. Методика отправки. Различаются постепенная и параллельная методики.
4. Степень устойчивости к помехам. Простой уровень: для отправки сообщений используются разные кодировки; коррекционный уровень — отправка сообщений осуществляется заданными кодировками.
5. По использованию и предназначению. Кодировки внутреннего характера (такие коды свойственны разным системам; сюда можно отнести кодировки машинного типа и кодировки, использующие двоичные, десятичные и прочие системы позиционного типа). Наиболее распространенной кодировкой для электронно-вычислительных машин можно назвать кодировку двоичного типа. Данный код помогает создать аппарат, которые может осуществлять обработку, передачу и хранение информации. В результате применения данной кодировки, аппараты становятся максимально надежными. При этом сложность операций сводится к минимуму. В случае объединения информации двоичного типа (по 4) происходит превращение в кодировку шестнадцатеричного типа. Такой код обладает удобством в использовании с архитектурным строением электронно-вычислительных машин, работающих в 8-битной системе.
Кодировки, созданные для обмена и передачи информации. Распространенной можно назвать кодировку «ASCII». Данный код представляет из себя семибитную кодировку с различной символикой. Как и в случае работы электронно-вычислительных машин с байтовыми значениями, так и восьмой разряд используется для синхронизации и проверки, а также для увеличения кодировки. Электронно-вычислительные машины фирмы IBM используют кодировку двоично-десятичного расширенного характера для передачи информации «EBCDIC». Связные каналы постоянно используют телетайп, кодировку «МККТТ» или модифицированный код «МТК» и прочие коды.
Специализированные коды – это коды, которые позволяют решать конкретные специализированные задачи передачи и обработки информации. В качестве примера можно привести циклический код Грея, часто применяемый в АЦП угловых и линейных перемещений. Коды Фибоначчи применяются с целью создания быстрого и помехоустойчивого АЦП.
2. Методы кодирования данных
2.1 Метод кодирования Хаффмана
1952 г. ознаменовался разработкой Д. Хаффманом метода кодировки информации на основе двоичных кодирующих структур. Создание данной методики случилось еще до появления первых ПК. Эффективности методики до такой степени велика, что современные методы по сей день основаны на ней. Данный метод в основном не используется отдельным образом. Довольно часто методику совмещают с другими кодировками. Код, созданный Хаффманом, показывает правильное построение кодировок с переменной протяженностью и наименьшей стандартной длиной. В результате применения методики, сжатие данных происходит до энтропического состояния, если соблюдается условие равенства отрицательного значения цифры «2».
Методика характеризуется наличием двух объемных стадий, таких как:
- Построение структуры кода с оптимальным значением;
- Показательное отображение системы «символа-кода» на основе построенной структуры.
База метода показывает: какая-либо символика, входящая в стандартную систему из 256 символов, попадается наиболее часто по отношению к средней протяженности повторов, а какие-то символы характеризуются более редким появлением. То есть, происходит сокращение целого объема данных при применении кратких длин бит (не превышающих 8 бит) для записи числового значения. То же самое характерно при применении длинных последовательностей для записи редкой символики. В итоге, получается точное системное строение информации, которое отображается, как дерево (двоичная структура, двоичное древо).
Например, A={a1,a2,...,an} — это алфавит, содержащий «n» случайной символики, а W={w1,w2,...,wn} — это совокупность цельных весовых структур с положительным значением. В этом случае набор кодировок бинарного типа C={c1,c2,...,cn} приобретает такие свойства:
- «ci» не работает в качестве префикса в отношении «cj», когда i!=j; наименьшая протяженность кодировки «ci» - избыточная минимальная кодировка префиксного типа (код Хаффмана).
Древом бинарного типа называется структура с четкой ориентацией, у которой исходная половина степени меньше или равна 2.
Верх структуры бинарного типа с исходной нулевой половиной степени — корень. Любая прочая вершина имеет исходную половину степени, равную 1.
Например, «Т» - это древо бинарного типа, «А»=(0,1) - это алфавит двоичного типа. Всем ребрам бинарного древа присуща одна и та же алфавитная символика таким образом, что все ребра, начинающиеся в единых вершинах, отмечаются различными символами. Таким образом, любой лист бинарного древо имеет собственное отличающееся кодовое значение, а именно слово, состоящее из символьных обозначений. Данные обозначения появляются в результате продвижения корень-лист. Отдельным отличием этой методики можно назвать наличие префикса у конечных кодировок.
Значение стоимости сохранения информации, подверженной кодировке с использованием бинарного древа, равняется сложению значений путей корень-все листы древа. Данные значения взвешиваются в зависимости от того, как часто появляется нужное кодовое значение (слово) или в зависимости от протяженности путей, подверженных взвешиванию, а именно:  ,
,  - частота кодового значения (слова) протяженности
- частота кодового значения (слова) протяженности  во входящем движении.
во входящем движении.
Чтобы наглядно проследить данный процесс, проведем анализ устройства кода в «ASCII». Эта кодировка характерна тем, что вся символика представлена кодовыми значениями (словами), имеющими четкую стандартную протяженность 8 бит. В результате, значение стоимости сохранения информации такое:
 , «W» - сумма кодовых значений (слов) во входном движении.
, «W» - сумма кодовых значений (слов) во входном движении.
Эта формула сообщает, что значение стоимости сохранения двадцати восьми кодовых значений (слов) равняется 312 в «ASCII». Данный параметр не зависит от значения относительных частот отдельно взятой символики во входном движении. Код Хаффмана позволяет снизить значение стоимости сохранения движения кодовых значений (слов) путем подборки такой протяженности кодовых значений, в результате которой протяженность длин, подверженных взвешиванию станет минимальной. Бинарную структуру, имеющую самую малую протяженность потоков, называют древом Хаффмана.
В результате применения кода Хаффмана можно отследить появления табличного значения с частотой выпадания буквенных символов на входящем потоке. Далее посредством использования этих табличных значений происходит создание древа Хаффмана.
1. Буквенные символы входящего потока осуществляют создание списка узлов свободного типа. Каждый лист имеет свое значение веса, соответствующее числу выпадания буквенного символа в информации, подвергнутой сжатию, или же вероятности;
2. Происходит определение двух узлов структуры свободного типа, имеющих минимальное весовое значение;
Осуществляется производство родителя узлов, который имеет весовое значение, равное совокупности их весовых значений;
Осуществляется добавление родителя к узлам свободного типа и удаление двух предшествующих узлов;
Производится получение выходящей дугой бита со значением «1» и со значением «0»;
Вторая ступень начинается с повторения момента, который характеризуется наличием свободных узлов более 1. Данный момент называется корень структуры (дерева).
Классическая методика Хаффмана характеризуется наличием негативного момента. Для возвращения информации, которая была подвержена сжатию, декодер должен знать табличные частотные значения, применявшиеся при использовании данной методики. В результате, протяженность данных, подверженных сжатию, увеличивается на протяженность табличных частотных значений. Эти значения обязаны быть предшествующими информации, поэтому весь процесс сжатия информации может приобрести бесполезность. Кроме того, становится необходимым наличие двух информационных потоков в результате обязательного наличия полноценных частотных данных до начала кодировки. Первый поток нужен для создания информационной структуры: табличных частотных значений и бинарного древа. Второй поток требуется для самой кодировки.
2.2 Метод арифметического кодирования
Создание методики кодировки арифметическим способом принадлежит П. Элиасу. Дерево информации, подверженной арифметической кодировке, включает в себя блоки, имеющие одну и ту же протяженность и возможность будущей собственной кодировки. Если протяженность блока растет, усредненная протяженность кодового значения (слова) движется к энтропическому значению. В этом случае становится затруднительным практическое создание алгоритмики и происходит общее замедлении кодировки. В итоге, при использовании кодировки арифметического типа, можно получить невысокие избыточные значения в случае кодировки громадных входящих потоков.
Проведем анализ объединяющих принципов кодировки арифметического типа. К примеру, мы обладаем источником, создающим символьные алфавитные значения А={a1,a2,…,an} при соответствии в отношении вероятных значений pi=P(ai). Необходимо проведение кодировки каждого символьного значения в отношении источника данного типа Х=х1х2х3х4.
Произведем подсчет вероятных значений кумулятивного типа Q0 ,Q1,…,Qn:
Q0=0
Q1=p1
Q2=p1+p2
Q3=p1+p2+p3
..
Qn=p1+p2+…+pn=1
Произведем разделение интервала [Q0,Qn) (а именно интервала [0,1) так, чтобы каждый начальный алфавитный символ обладал сходным интервалом, который равен вероятному значению ( рис. 1).
a1 [Q0,Q1)
a2 [Q1,Q2)
a3 [Q2,Q3)
a4 [Q3,Q4)
..
an [Qn-1,Qn)
При проведении кодировки становится необходимым отбор интервального значения, имеющего сходное изначальное символьное значение. В будущем, в отношении данного интервала будем производить его деление пропорциональным образом относительно вероятных изначальных символьных алфавитных значений. В результате, производится уменьшение интервального значения до полного кодирования каждого символа.
Рис. 1 демонстрирует такое кодирование, используя как пример последовательный значения а3а2а3.
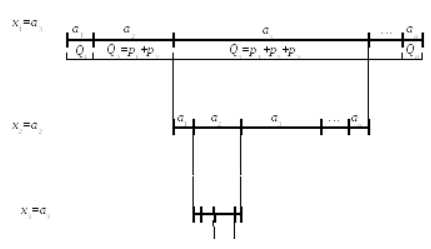
Рис. 1 Схематическое изображение кодировки арифметического типа
Для максимального удобства при расчетах обозначим отдельные моменты:
«li» является нижним граничным значением выбранного сегмента, соответствующим «i-тому» начальному символьному значению информации;
«hi» является верхним граничным значением выбранного сегмента
«ri» является протяженностью выбранного сегмента длина («li», «hi»).
Производим приведение входных значений выбранных отрезков
l0 = Q0=0, h0 = Qk=1, r0 = h0 l0=1
После этого вычислим граничные интервальные значения, соответствующие символьному значению посредством формул:
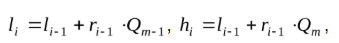
«m» является порядковым номером начального алфавитного значения в источнике, m=1,..,n.
Таким образом, интервальная итоговая протяженность — это произведение всех вероятных символьных значений при влиянии порядка размещения буквенных символов на начальное интервальное значение в области последовательности, подвергнутой кодированию.
2.3 Адаптивные методы кодирования
Непосредственно в процессе кодирования наблюдается отсутствие знания точных действительных значений, а также их изменчивость, зависящая от временных интервальных значений. Если возникает подобная ситуация, используется адаптивная модифицированная кодировка.
Адаптивная методика обычно подразумевает наличие «окна» для отслеживания статистической исходной информации. Окном называется последовательная связь буквенных символов, предшествующих буквенному символу, подверженному кодировке. Протяженностью окна является количество буквенных символов.
Протяженность окна обычно обладает постоянностью. В процессе кодировки отдельного символьного значения происходит смещение в правую сторону на 1 шаг. В результате, создание хода для последующего символьного значения производится на базе информации, содержащейся в настоящее время в области окна (рис. 2).
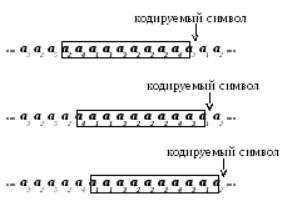
Рис. 2 Схематическое изображение передвижения окна в процессе кодировки.
При декодировке происходит смещение окна в тексте аналогичным образом. Информация в области окна позволяет декодировать следующий буквенный символ однозначным образом.
Анализ избыточности при кодировке адаптивного типа не является простой арифметической задачей, потому как цельной избыточностью можно назвать сложением двух блоков, а именно: избыточности, которая появляется в результате анализа вероятного расположения буквенных символов и избыточной кодировки. Таким образом, градация эффектных методик кодировки адаптивного типа обычно анализируется посредством экспериментальных значений.
Большинство методик кодировки адаптивного типа следуют такой теореме:
Стандартная длина кодового значения (слова) при кодировке адаптивного типа равна такому неравенству:
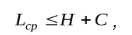
«Н» – энтропическое значение исходника информации, «C» – постоянная величина, находящаяся под влиянием протяженности окна и объема алфавитного значения исходника.
1978 г. ознаменовался разработкой метода кодировки исходников, содержащих меняющиеся статистические данные. Данный метод разработал Р. Галлагер. Он основывается на базе методики Хаффмана, поэтому метод был назван адаптивным кодированием Хаффмана.
Эта методика используется вместе с прочими методиками, позволяющими сжимать информацию. Кодировка осуществляется в источниках информации, сохраняемых в области окна протяженностью «W». Алгоритмика этой кодировки предусматривает ряд таких, действий, как:
Перед осуществлением кодировки последующего символьного значения, производится вычисление частотных данных в виде символьных начальных алфавитных значений А={a1, a2, .., an}. Обозначим эти частотные значения в виде q(a1), q(a2), .., q(an). Проведение оценки вероятных исходных значений осуществляется в источниках частотных значений (букв) в области окна
P(a1)= q(a1)/W, P(a2) =q(a2)/W, .., P(an)= q(an)/W.
По соотношению с итогами осуществляется создание кодировки Хаффмана относительно алфавитного значения «А».
Последующее символьное значение подвергается кодированию посредством получившегося кода.
Окно смещается в правую сторону на один шаг. При этом заново производится вычисление частотных данных относительно области алфавитного окна и осуществляется создание нового кода для последующего буквенного символа. Постоянное повторение данного процесса необходима для итогового создания кодировки для полного доклада.
2.4 Методы словарных кодов класса Lz
Очень широко в практическом кодировании используется кодировка слов разряда «LZ». Данные словарные коды использовались при создании разных архивирующих программ. Кроме того, эти методы используются, когда нужно сжимать изображения для каких-либо аппаратов, призванных передавать и хранить информацию.
Данная методика позволяет оптимальным образом кодировать исходники с изменчивыми данными. Важно отметить высокую скорость кодировки и легкую работу на практике. Также, словарные коды разряда «LZ» легко приспосабливаются в условиях переменных статистических данных.
«LZ» кодирование подвержено постоянной модернизации и улучшению. 1977 г. ознаменовался представлением первого вида словарной кодировки. Словарный код впервые был создан А. Лемпелом и Я. Зивом. На сегодняшний день можно говорить о большом количестве методов в разряде словарных кодов и многие из этих методов — модернизированные словарные коды Лемпела и Зива.
«LZ» имеют общие признаки в схематическом отображении. При кодировке информация разделяется на отдельные слова, которые имеют различную протяженность. При обрабатывании любого слова производится поиск схожих слов в предыдущем источнике, который был закодирован. При удачном нахождении слова, ему передается подходящая кодировка. При отсутствии результатов поиска, передается специализированное символьное значение, обозначающее неимение результатов и производится создание другой пометки этого значения (слова). Каждое новое слово подвергается сохранению и получению для него отдельного кода.
Классификация при сохранении и поиске выделяет такие виды, как:
- Алгоритмика с целью поиска значений (слов) в какой-либо части источника, ранее подвергнувшегося кодированию;
- Алгоритмика с применением адаптивных словарей, содержащих значения, которые встречались раньше. Если словарь заполняется до завершения кодировки, некоторые методики осуществляют процесс обновления, а именно записывают новые слова взамен предыдущих. Словари обновляются не во всех методах.
Словарные коды «LZ» отличаются наличием иных размеров окна, отдельных методов кодировки, другим обновлением словарей и прочими признаками. Любой из перечисленных признаков непосредственным образом влияет на отдельные свойства этих методик, такие как: временные промежутки кодировки, память и ее количество, а также а также уровень сжатия информации. Тем не менее, на практике данные методики очень удобны и используются повсеместно. «LZ» помогают эффективно сжимать информацию, которой характерна неизвестность статистических данных.
3. Программная реализация алгоритма кодирования Хаффмана
Алгоритм кодирования Хаффмана был реализован в среде разработки Borland Delphi 7.0.
Создание кода Хаффмана было выполнено в соответствии со следующим алгоритмом:
- Необходимо выделить все буквы алфавита в зависимости от того, насколько вероятно их можно встретить в тексте;
- Необходимо объединить две буквы, вероятность появления которых ниже других; в итоге создаётся дерево, каждый узел которого будет иметь общую вероятность, которая будет равна сумме вероятностей узлов, которые ниже;
- Необходимо выстроить пути, ко всем листам дерева, отмечая направления ко всем узлам.
Для выявления количества повторяющихся букв, мы обозначили введенные буквы единой строкой «s», добавили новую переменную к подстроке «st» и построили цикл, который продолжается до того времени пока не будет проверена вся строка. Используя классическую функцию «pos» был произведён поиск одинаковых подстрок в строке (одинаковых символов «st» в строке «s»). При обнаружении повторяющихся букв производилось их удаление.
Все проверенные символы снова добавлялись к массиву с их числовым вхождением. С этой целью применялся этот же массив, но его увеличивали на проверенное значение «setlength (a, KolSim)». В «Memo1» привели итог подсчета символов.
begin
Button2.Enabled:=true;
Button1.Enabled:=false;
Memo1.Clear;
Memo2.Clear;
s:=Edit1.text;
st:=s;
KolSim:=0;
while length(s)>0 do
begin
c:=s[1];
j:=0;
repeat
i:=pos(c,s);
if i>0 then
begin
inc(j);
delete(s,i,1);
end;
until not(i>0);
Memo1.Lines.Add(c+' -> '+inttostr(j));
inc(KolSim);
setlength(a,KolSim);
a[KolSim-1].Simvol:=c;
a[KolSim-1].Kolizestvo:=j;
a[KolSim-1].R:=-1;
a[KolSim-1].L:=-1;
a[KolSim-1].x:=1;
end;
Затем осуществлялся поиск двух самых малых элементов массива. С этой целью использовали переменные Ind1 и Ind2 – начальные листья дерева. Им было присвоено значение «-1». Далее был определён цикл прохождения по массиву, и дополнительно добавлены две переменных с самым низким значением: MinEl1 MinEl2. Для каждого из этих элементов создаётся собственный цикл нахождения:
repeat
MinEl1:=0;
MinEl2:=0;
Ind1:=-1;
Ind2:=-1;
for i:=0 to KolSim-1 do
if (a[i].x<>-1) and ((a[i].Kolizestvo<MinEl1) or (MinEl1=0)) then
begin
Ind1:=i;
MinEl1:=a[i].Kolizestvo;
end;
for i:=0 to KolSim-1 do
if (Ind1<>i) and (a[i].x<>-1) and ((a[i].Kolizestvo<MinEl2) or (MinEl2=0)) then
begin
Ind2:=i;
MinEl2:=a[i].Kolizestvo;
end;
Осуществив поиск двух наименьших элементов массива, их сложили, и образовался новый индекс. При дальнейшем прохождении по массиву к вниманию принимался только новый индекс, который сравнивался с другими элементами. Этот цикл работал пока не осталось одно значение – корень.
if (MinEl1>0) and (MinEl2>0) then
begin
inc(KolSim);
setLength(a,KolSim);
a[KolSim-1].Simvol:='';
a[KolSim-1].Kolizestvo:=MinEl2+MinEl1;
a[KolSim-1].R:=Ind1;
a[KolSim-1].L:=Ind2;
a[Ind1].x:=-1;
a[Ind2].x:=-1;
end;
until not((MinEl1>0) and (MinEl2>0));
Далее все данные были выведены в « Memo2 », а длина всего сообщения в « Еdit2».
for i:=0 to KolSim-1 do
begin
Memo2.Lines.Add(' s-> '+a[i].Simvol);
Memo2.Lines.Add('Veroat -> '+inttostr(a[i].Kolizestvo));
Memo2.Lines.Add('R -> '+inttostr(a[i].R));
Memo2.Lines.Add('L -> '+inttostr(a[i].L));
Memo2.Lines.Add('------------------------');
end;
Edit2.Text:=inttostr(KolSim);
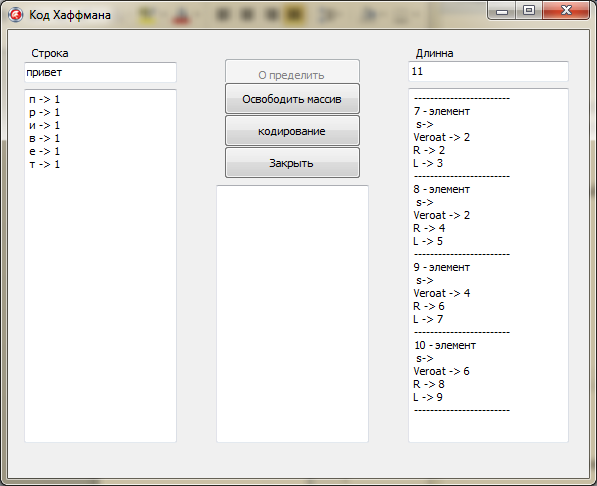
Рисунок 3. Отображение информации в полях
Далее была произведена кодировка всех введённых символов при помощи рекурсии.
Индексами были помечены все правые и левые ветви дерева. Рекурсия будет просматривать всё дерево, начиная с корня. Если будем идти по правой ветви, то расстоянию от уза до узла присвоим 0, по левому - 1. Ветви буду просматриваться до тех пор пока не будет достигнуто исходных листьев «-1 » (символов).
После достижения «-1» рекурсия заканчивает работу и выводит полученный результат в Memo3 (рис. 4).
Memo3.Lines.Add(a[Ind].Simvol+' -> '+s);
exit;
end;
if a[Ind].R<>-1 then
f(a[Ind].R,s+'0');
if a[Ind].L<>-1 then
f(a[Ind].L,s+'1');
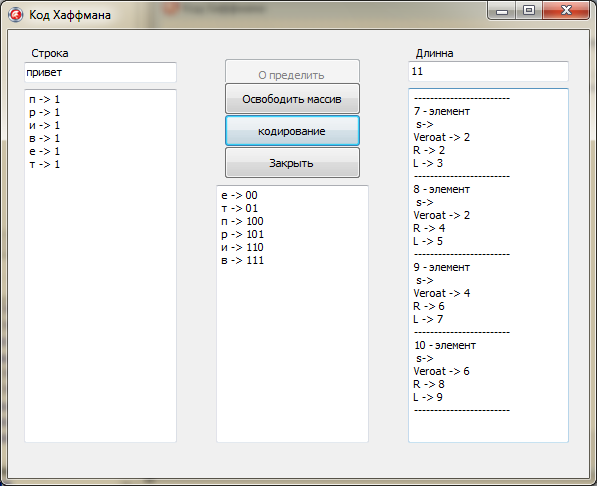
Рисунок 4. Полученный результат кодирования
Таким образом, был программно реализован алгоритм кодирования Хаффмана.
ЗАКЛЮЧЕНИЕ
При подготовке курсовой работы на тему «Методы кодирования данных» была проанализирована литература по данной теме и подготовлена программа, демонстрирующая работу алгоритма Хаффмана.
Цель работы – проанализировать методы кодирования была достигнута за счёт выполнения задач:
1) рассмотреть теоретические основы кодирования данных;
2) рассмотреть методы кодирования данных;
3) разработать программу для демонстрации метода кодирования.
Можно сделать следующие выводы:
Проблема кодирования данных зародилась очень давно, намного раньше, чем появилась вычислительная техника.
До того, как были открыты методики Хаффмана и Шеннона, алфавитные символы в процессе передачи информации кодировались одним и тем же количеством бит. При появлении новейших методик произошло создание способов, использовавших при кодировке символьные значения, которые имели разное число бит. Данное значение зависело от вероятностей расположения их непосредственно в самом тексте.
Достоинствами новых методов кодирования выступили их простая реализация и, как следствие этого, быстрое кодирование и декодирование.
Таким образом, поставленная цель работы достигнута, но данная работа может быть продолжена в других аспектах.
СПИСОК ЛИТЕРАТУРЫ:
1. Берлекэмп Э.Р. Техника кодирования с исправлением ошибок // ТИИЭР. - 1980. - Т. 68, № 5, - С. 24-58.
2. Боуз Р.К., Рой-Чоудхури Д.К. Об одном классе двоичных групповых кодов с исправлением ошибок // Кибернетический сборник.- 1961.-Вып. 2. - С. 83-94.
3. Витерби А. Границы ошибок для сверточных кодов и асимптотически оптимальный алгоритм декодирования // Некоторые вопросы теории кодирования. - М.: Мир, 1970. - С. 142-165.
4. Галисеев Г.В. Программирование в среде Delphi 7 / Г.В. Галисеев – М.: Вильямс, 2004. – 288с.
5. Золотарёв В.В. Алгоритмы кодирования символьных данных в вычислительных сетях // Вопросы кибернетики. - 1985. - Вып. 106.
6. Иванова Г.С. Технология программирования / Г.С. Иванова – М.: Изд-во МГТУ им. Н.Э. Баумана, 2004. – 320с.
7. Соколов, А.В. Защита информации в распределенных корпоративных сетях и системах / А.В. Соколов, В.Ф. Шаньгин. - М.: ДМК Пресс, 2014. - 656 c.
8. Спесивцев, А.В. Защита информации в персональных ЭВМ / А.В. Спесивцев, В.А. Вегнер, А.Ю. Крутяков. - М.: Радио и связь, 2015. - 192 c.
9. Шаньгин, В.Ф. Защита компьютерной информации / В.Ф. Шаньгин. - М.: ДМК Пресс, 2014. - 544 c.
10. Экслер, А.Б. Архиваторы. Программы для хранения и обработки информации в сжатом виде: моногр. / А.Б. Экслер. - М.: МП Алекс, 2015. - 150 c.

- Применение процессного подхода для оптимизации бизнес-процессов (Процессный подход и соответствие стандартам качества)
- Процессы принятия решений в организации (ООО ТК «Транс-Авто»)
- Юрисдикционные документы « Судне психологическая экспедиция »
- международной уголовное право и его особенности
- Определение наличной конверсионной операции
- Корпоративная культура в организации («ДОМАШНИЙ ЭКСПЕРТ»)
- Финансы акционерных обществ: понятие и сущность
- Законность и правопорядок (Сущность законности)
- Комплект мебели в «Скандинавском» стиле для жилой квартиры
- Информационное обеспечение анализа банковских рисков
- Информационное обеспечение анализа банковских рисков (ПАО «Сбербанк России»)
- Организация банковских систем зарубежных стран: сущность и понятие